這篇要介紹到論文提到的記憶與檢索系統,記憶比較單純,檢索會比較複雜點,如何快速且有效去找出有相關性、重要性的記憶,對於大腦來說也很重要的問題。以前看書講到,大腦的記憶其實是分散在很多部位,有分長短期、視覺記憶什麼的… 大腦儲存部份會比較複雜點,但如何抽取並整合,這就是一個有挑戰性的問題了。
為了使得agent在每一時刻可以與外界(人或場景)做互動,每一次的行為的產生,都是透過當前獲得資訊以及過去的經驗,所產出的一次行為。但是記憶是可以很長的,所以為了可以找出最相關的記憶,該研究核心用了些方法,或者說是公式,去排列並找出資訊。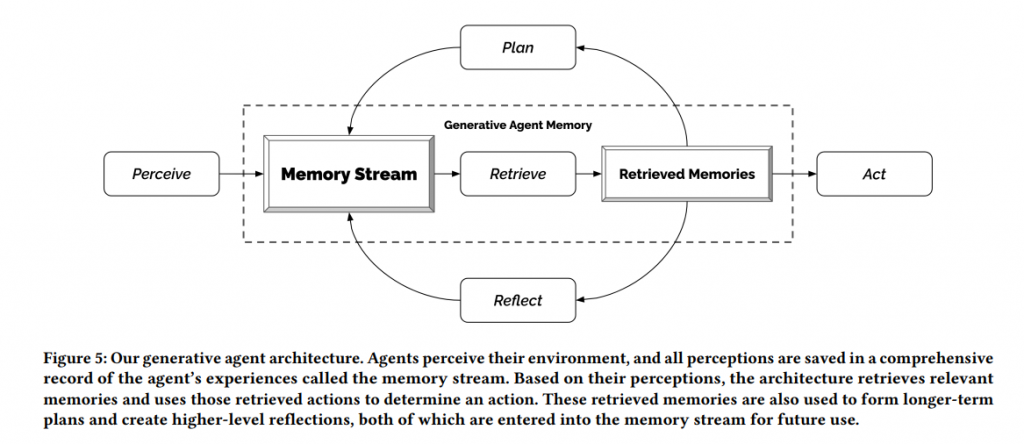
抽取記憶記憶相關性,由三個元素所組成,分別是,最近檢索時間、重要性與相關性。
最終,我們得到三個被規範化到0~1分數的數字,並做加總,總體而言整個公式為
Score = recency + importance + relevance
這三個前面都有一個係數α,但因為論文表示三個都設1,這邊就不多寫
我個人覺得整體設計蠻直覺的,這個框架對我過去沒研究語言模型來說挺新鮮,不過之前有看過類似,更複雜的語言模型系統,但以這邊框架來講,清晰有效,給人的感覺還不錯,太複雜的框架,有時候反而會有很多不穩定因素。
Generative Agents: Interactive Simulacra of Human Behavior


 iThome鐵人賽
iThome鐵人賽