這篇文章會使用 Python 的 Requests 和 Beautiful Soup 函式庫,實作一個網路爬蟲,利用傳送 cookie 的方式,突破未滿十八歲的按鈕檢查限制,取得 PTT 八卦版文章的標題,並更進一步使用 txt 儲存。
原文參考:爬取 PTT 八卦版文章標題
本篇使用的 Python 版本為 3.7.12,所有範例可使用 Google Colab 實作,不用安裝任何軟體 ( 參考:使用 Google Colab )
PTT 八卦版是一個 BBS 分享八卦的空間,除了正常使用 BBS 登入瀏覽,也可以透過瀏覽器,進行單純的網頁瀏覽。
使用 Requests 函式庫之後,就能使用 get 的方法抓取 PTT 八卦版的網頁內容。
參考:Requests 函式庫
import requests
web = requests.get('https://www.ptt.cc/bbs/Gossiping/index.html')
print(web.text)
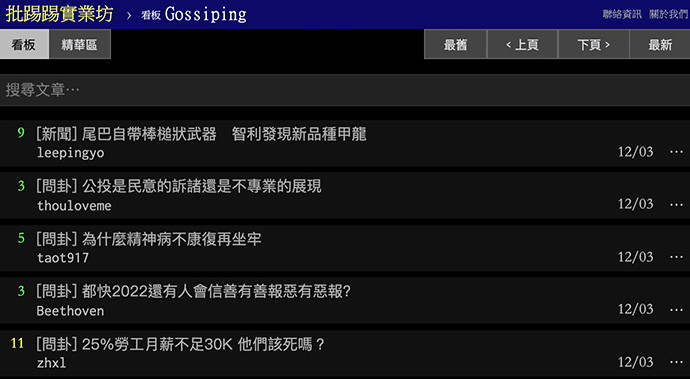
執行程式後,雖然可以正常抓取網頁,但會發現抓到的內容與實際上的不同,出現了「看板內容需滿十八歲方可瀏覽」的文字。

因為 PTT 八卦版的網頁版,額外多了一層 Cookies 的驗證手續,在沒有點擊過「我已滿十八歲」按鈕的情形下,會缺少 Cookies 相關資訊,導致會多一頁提示文字,下圖是沒有點擊過按鈕,單純打開 PTT 八卦版頁面的長相,Requests 就是抓取到這一頁的資訊。
Cookies 是指某些網站為了辨別使用者身分而儲存在用戶端瀏覽器中的資料,Cookies 可以記錄使用者瀏覽時的資訊,當使用者存取另一個頁面,瀏覽器會把 Cookies 傳送給伺服器,讓伺服器知道使用者目前的狀態。

用滑鼠在頁面的任意位置,按下右鍵,點選「檢查」。
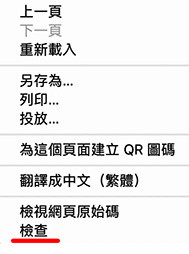
開啟後點選「Application」頁籤,左側選擇 Cookies > https://www.ptt.cc,就可以看到瀏覽器記錄了哪些 PTT 網站的 Cookies。
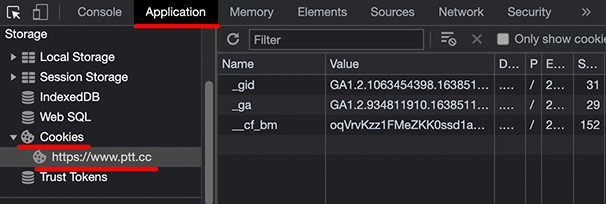
這時如果點擊了「已經年滿十八歲」的按鈕,Cookies 裡會多出一個 Name 是 over18,Value 是 1 的項目,這個項目就是判斷是否出現這個頁面的依據。
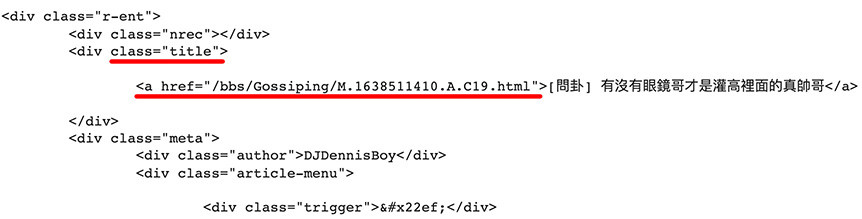
回到剛剛的 Python 程式,將 Cookies 的資訊加入 Requests 的方法裡,重新執行後,就會抓取到正確的網頁內容 ( 下圖紅線的 tag 是要抓取的資料位置 )。
import requests
web = requests.get('https://www.ptt.cc/bbs/Gossiping/index.html', cookies={'over18':'1'}) # 加入 Cookies 資訊
print(web.text)
取得網頁內容後,使用 Beautiful Soup 函式庫就能篩選出特定內容,下方的程式碼執行後,會取得文章的標題以及超連結的網址。
import requests
from bs4 import BeautifulSoup
url = 'https://www.ptt.cc/'
web = requests.get('https://www.ptt.cc/bbs/Gossiping/index.html', cookies={'over18':'1'})
soup = BeautifulSoup(web.text, "html.parser")
titles = soup.find_all('div', class_='title') # 取得 class 為 title 的 div 內容
for i in titles:
if i.find('a') != None: # 判斷如果不為 None
print(i.find('a').get_text()) # 取得 div 裡 a 的內容,使用 get_text() 取得文字
print(url + i.find('a')['href'], end='\n\n') # 使用 ['href'] 取得 href 的屬性

使用 Python 內建的 open 指令,就能使用純文字文件 txt 檔案,儲存爬蟲爬到的資料,下方的程式碼將取得的資料,記錄在 output 變數裡,全部完成後將 output 的內容寫入純文字文件中 ( 每個人的純文字文件路徑可能不同,請依照自己電腦或 Colab 的路徑為主 )。
import requests
from bs4 import BeautifulSoup
url = 'https://www.ptt.cc/'
web = requests.get('https://www.ptt.cc/bbs/Gossiping/index.html', cookies={'over18':'1'})
web.encoding='utf-8' # 避免中文亂碼
soup = BeautifulSoup(web.text, "html.parser")
titles = soup.find_all('div', class_='title')
output = '' # 建立 output 變數
for i in titles:
if i.find('a') != None:
# 將資料一次記錄到 output 變數裡
output = output + i.find('a').get_text() + '\n' + url + i.find('a')['href'] + '\n\n'
print(output)
f = open('/content/drive/MyDrive/Colab Notebookstest.txt','w') # 建立並開啟純文字文件 ( Colab 才需要 )
f.write(output) # 將資料寫入檔案裡
f.close()
熟悉自動爬取文章標題的做法後,就能夠應用在各種「靜態網頁」裡,輕鬆收集各種想收集的資料 ( 動態網頁內容會再另外的篇幅介紹 )。
大家好,我是 OXXO,是個即將邁入中年的斜槓青年,我有個超過一千篇教學的 STEAM 教育學習網,有興趣可以參考下方連結呦~ ^_^


 iThome鐵人賽
iThome鐵人賽