這篇文章會使用 Python 的 Requests 和 Beautiful Soup 函式庫,實作一個可以自動下載圖片的網路爬蟲,只要知道 PTT Beauty 板的網頁網址,就能將網頁內全部的正妹圖片,自動下載到電腦的資料夾中。
原文參考:爬取並自動下載 PTT 正妹圖片
本篇使用的 Python 版本為 3.7.12,所有範例可使用 Google Colab 實作,不用安裝任何軟體 ( 參考:使用 Google Colab )
PTT Beauty 板是一個 BBS 分享帥哥美女圖片的空間,除了正常使用 BBS 登入瀏覽,也可以透過瀏覽器,進行單純的網頁瀏覽,範例使用的網址為其中一篇分享藝人安心亞照片的網頁。
- PTT Beauty 板網址:https://www.ptt.cc/bbs/Beauty/index.html
- 安心亞照片分享網址:https://www.ptt.cc/bbs/Beauty/M.1638380033.A.7C7.html
使用 Requests 函式庫的 get 的方法,抓取安心亞網頁的內容 ( 注意需要加入 Cookies,避免出現「看板內容需滿十八歲方可瀏覽」的頁面 )。
import requests
from bs4 import BeautifulSoup
web = requests.get('https://www.ptt.cc/bbs/Beauty/M.1638380033.A.7C7.html', cookies={'over18':'1'}) # 傳送 Cookies 資訊後,抓取頁面內容
soup = BeautifulSoup(web.text, "html.parser") # 使用 BeautifulSoup 取得網頁結構
imgs = soup.find_all('img') # 取得所有 img tag 的內容
for i in imgs:
print(i['src']) # 印出 src 的屬性

讀取圖片的網址後,再次使用 requests 抓取圖片資訊編碼,接著使用 open 設定以二進位格式寫入圖片檔案,每次開啟新檔案時,透過變數 name 設定編號,就能讓每張圖片的檔名都不同。
- 注意,寫入時要注意「資料夾」必須存在,不然會發生錯誤。
- 參考:內建函式 ( 檔案讀寫 open ) - 存取模式
import requests
from bs4 import BeautifulSoup
web = requests.get('https://www.ptt.cc/bbs/Beauty/M.1638380033.A.7C7.html', cookies={'over18':'1'})
soup = BeautifulSoup(web.text, "html.parser")
imgs = soup.find_all('img')
name = 0 # 設定圖片編號
for i in imgs:
print(i['src'])
jpg = requests.get(i['src']) # 使用 requests 讀取圖片網址,取得圖片編碼
f = open(f'/content/drive/MyDrive/Colab Notebooks/download/test_{name}.jpg', 'wb') # 使用 open 設定以二進位格式寫入圖片檔案
f.write(jpg.content) # 寫入圖片的 content
f.close() # 寫入完成後關閉圖片檔案
name = name + 1 # 編號增加 1
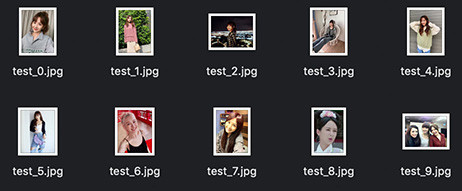
程式執行後,就會看見圖片依序下載到電腦裡。
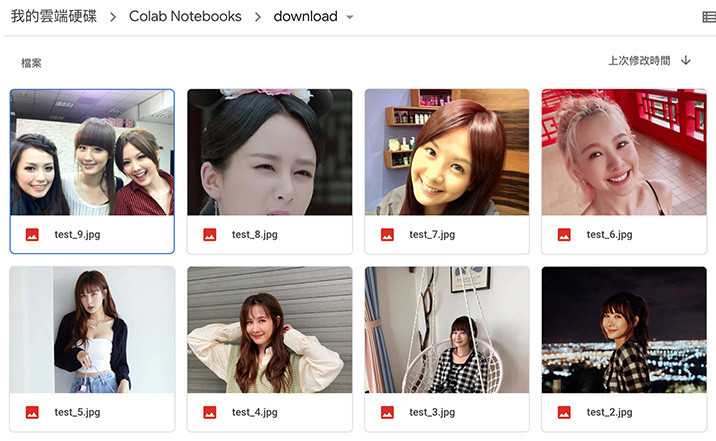
如果使用 Colab 就會下載到雲端硬碟指定的資料夾裡。
學會自動下載圖片的方法後,就能夠輕鬆爬取並下載各種「靜態網頁」的圖片 ( 動態網頁會在另外的篇幅介紹 ),過程中比較需要注意的是「圖片網址」,如果網址有包含 http 或 https 表示是「絕對路徑」,直接下載即可,但如果沒有,表示該網址是「相對路徑」,就必須要自行將路徑換成真正的路徑位置。
大家好,我是 OXXO,是個即將邁入中年的斜槓青年,我有個超過一千篇教學的 STEAM 教育學習網,有興趣可以參考下方連結呦~ ^_^


 iThome鐵人賽
iThome鐵人賽