
接下來我們就要開始介紹 Facial Landmark 的實做技術細節了,首先我們會從最簡單的一個 CNN 去做 Facial landamrk regression 去做介紹,我們會採取的架構為 PFLD (PFLD: A Practical Facial Landmark Detector),會使用到的資料極為 WFLD 資料集。
要實做出 PFLD 我們需要以下幾步:
在進行 Facial Landmark Detection 的實作之前,首先需要挑選一個適合的資料集。這裡我們使用 WFLW(Wider Facial Landmarks in-the-wild)資料集,它包含了大量的人臉圖像以及每張圖像中的多個臉部關鍵點的標註,共包含著 7500 張訓練用資料以及 2500 張測試用資料。
另外這個 wider 有沒有讓大家有點眼熟?聽起來是不是跟之前人臉辨識章節我們用的 WiderFace 資料集聽起來有點像?
沒錯!WFLD 的作者當初就是去拿了 WiderFace 的資料去手動標記
每張臉標了 96 個點呀!!!好拼!
你可以在 WFLW 資料集的官方網站上下載資料集,並按照其給出的格式組織資料。資料集下載點如下:
下載下來解壓縮之後請放成這樣的格式:
-- datasets
|-- WFLW
|-- WFLW_images
|-- WFLW_annotations
然後我們要來解釋一下 WFLW 的資料格式怎麼用。我想 WFLW_images 資料夾內的照片應該不是問題,你點開就可以看到照片,比較複雜的是 annotation 要怎麼看?
WFLW annotation 為一個 txt 檔,每一行為一張照片的標記資訊,我們把每一行切開並且用逗號分開之後成為一個 list (我們姑且稱為 image_anno),詳細如下:
image_anno[:196] , 一共 98 個點,每個點有 x,y ,假設我們處理後成為 98x2 的 array 叫做 landmarksimage_anno[196:200],一共四個值分別為 bbox_xmin, bbox_ymin, bbox_xmax, bbox_ymax (亦即 face bounding box 左上角跟右下角座標)image_anno[200:206],一共 6 個值,描述這張照片亮度, 表情, 遮擋與否等等資訊,我們不會用到image_anno[-1],為當前照片的名稱,用以去 WFLW_images 裡面撈對應的照片用其中,landmark 這98個點的順序如下圖: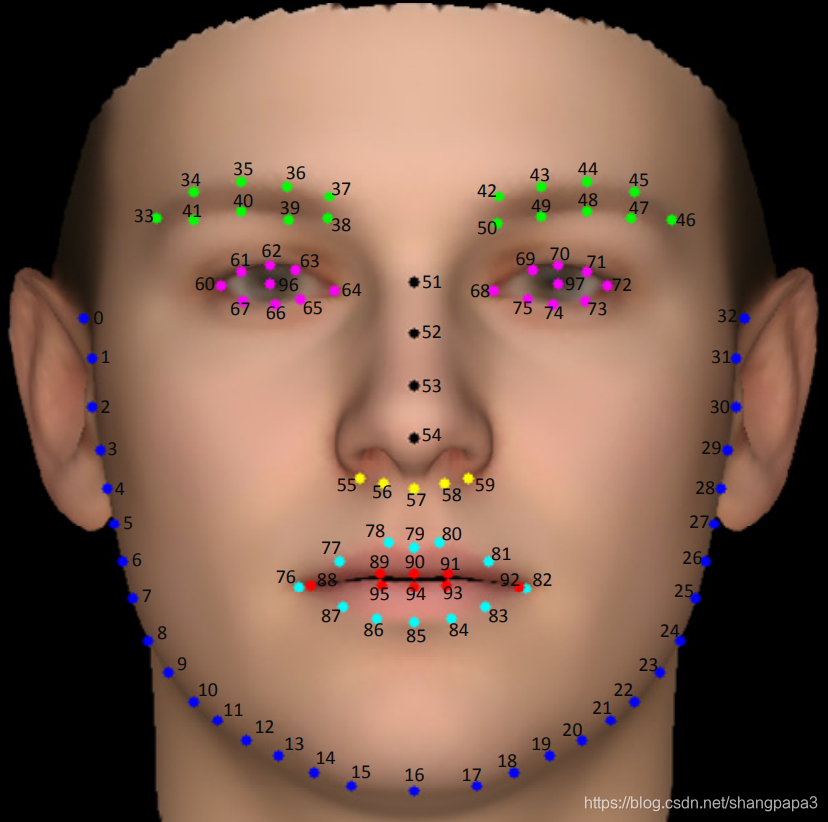
詳細順序可見:
1.下巴 : landmarks[:33]
2.左眉毛 : landmarks[33:42]
3.右眉毛 : landmarks[42:51]
4.鼻子(鼻根): landmarks[51:55]
5.鼻子(鼻孔): landmarks[55:60]
6.左眼 : landmarks[60:68]
7.右眼 : landmarks[68:76]
8.嘴唇(外圍): landmarks[76:88]
9.嘴唇(內圈): ladnamrks[88:]
那我們應該要如何去評價我們 Facial landmark 模型預測的準確呢?最直接簡單的我們可能會想到直接用 L2 去計算 predition 跟 ground truth 之間不就可以了嗎? 但這裡會遇到一個問題,如果這張照片本身 Face boundingbox 本身就大不就更容易有更大的誤差嗎?是的,所以在 Facial landamark 領域我們通常會用 Face bounding box 的大小來對 L2 作 noramlize! 這樣 normalize 後的值我們稱為 NMS,具體公式如下: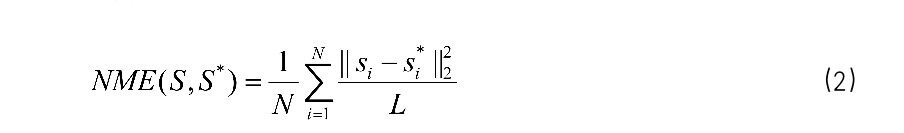
其中兩個 S 分別為預測跟 Label, L 為 Face bounding box 的長跟寬,做平方相加之後開根號
今天我們解析了我們要使用的資料集 WFLW,之後我們會繼續使用這個模型來訓練 Facial landmark 模型,期待與大家明晚再相見!

 iThome鐵人賽
iThome鐵人賽