這篇文章會使用 Python 的 Requests 和 Beautiful Soup 函式庫,搭配 threading 內建函式庫進行多執行緒處理,實作爬取寶可夢圖鑑裡的寶可夢網頁,並自動將每隻寶可夢的圖片下載到電腦中。
原文參考:同時下載多張寶可夢圖片
本篇使用的 Python 版本為 3.7.12,所有範例可使用 Google Colab 實作,不用安裝任何軟體 ( 參考:使用 Google Colab )
前往寶可夢圖鑑官方網站,點擊任何一隻寶可夢進入該寶可夢的頁面,本篇教學範例使用傑尼龜的頁面。

在畫面中按下滑鼠右鍵,檢視網頁的原始碼。
從原始碼中可以看見 meta 標籤裡,包含了一張傑尼龜的縮圖,待會就會透過爬蟲抓取這張縮圖。
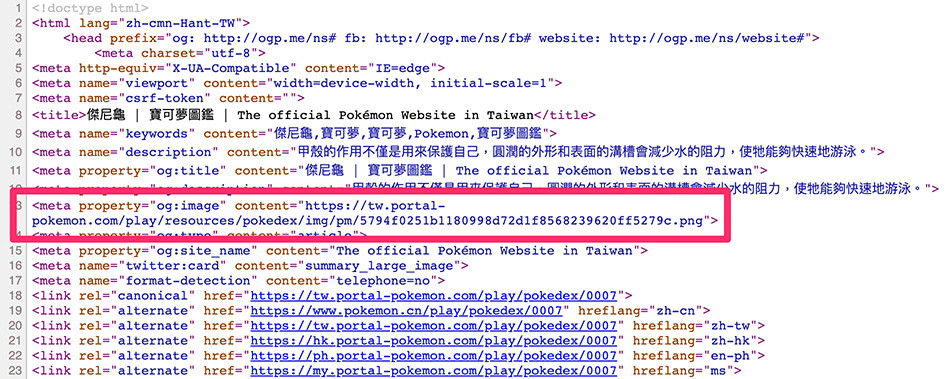
參考「Requests 函式庫」和「Beautiful Soup 函式庫」安裝 Requests 和 Beautiful Soup 函式庫 ( 如果是 Colab 或 Anaconda Jupyter 應該已經內建 ),執行下方的程式碼,使用 select 方法爬取具有 property 屬性為 og:image 的 meta 標籤,就能爬取到 meta 標籤裡的圖片網址。
import requests
from bs4 import BeautifulSoup
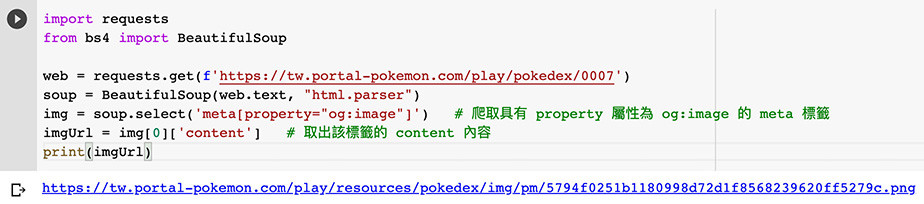
web = requests.get(f'https://tw.portal-pokemon.com/play/pokedex/0007')
soup = BeautifulSoup(web.text, "html.parser")
img = soup.select('meta[property="og:image"]') # 爬取具有 property 屬性為 og:image 的 meta 標籤
imgUrl = img[0]['content'] # 取出該標籤的 content 內容
print(imgUrl)
參考「內建函式 ( 檔案讀寫 open )」教學搭配 Requests 函式庫,就能讀取網址並將該圖片下載到 pokemon 的資料夾中 ( 請先建立該資料夾 )。
如果是 Colab 環境需要先連動 Google Drive,並透過 os.chdir 切換根目錄。
import requests
from bs4 import BeautifulSoup
web = requests.get(f'https://tw.portal-pokemon.com/play/pokedex/0007')
soup = BeautifulSoup(web.text, "html.parser")
img = soup.select('meta[property="og:image"]') # 爬取具有 property 屬性為 og:image 的 meta 標籤
imgUrl = img[0]['content'] # 取出該標籤的 content 內容
print(imgUrl)
import os
os.chdir('/content/drive/MyDrive/Colab Notebooks') # Colab 換路徑使用
imgFile = requests.get(imgUrl) # 讀取圖片資訊
f = open(f'pokemon/0007.png', 'wb') # 建立 0007.png 圖片
f.write(imgFile.content) # 寫入圖片
f.close()
print('ok')
使用 threading 函式庫,將原本的程式,從「同步」改為「非同步」執行,因為有多張圖片要處理,所以採用網址的編號 ( 寶可夢編號 ) 作為圖片的名稱,透過迴圈的方式,就能同時一次下載上百張圖片。
import os
os.chdir('/content/drive/MyDrive/Colab Notebooks') # Colab 換路徑使用
import requests
from bs4 import BeautifulSoup
import threading
def download(num):
# 加入 try 保護避免遇到無法下載的狀況而發生錯誤
try:
web = requests.get(f'https://tw.portal-pokemon.com/play/pokedex/{num}') # 使用變數替換網址
soup = BeautifulSoup(web.text, "html.parser")
img = soup.select('meta[property="og:image"]')
imgUrl = img[0]['content']
imgFile = requests.get(imgUrl)
f = open(f'pokemon/{num}.png', 'wb')
f.write(imgFile.content)
f.close()
print(num)
except:
print('error')
pass
# 使用迴圈,一次可以下載 1~99 張圖片
for i in range(1,100):
n = f'{i:04d}'
threading.Thread(target=download, args=(n,)).start()
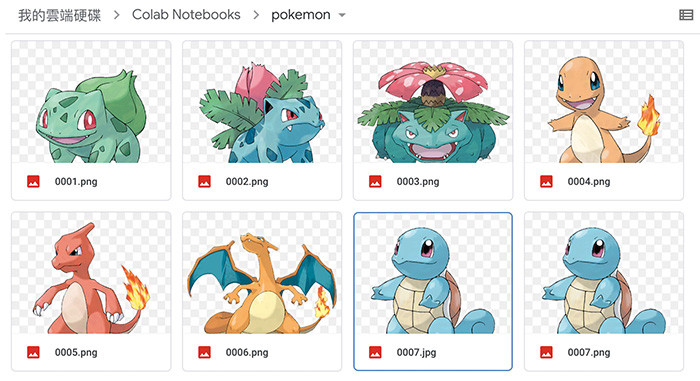
程式執行後,就會看見圖片「幾乎同時」下載到電腦裡。
如果遇到 Colab 無法使用 threading 的情形,可以改用 concurrent.futures 處理非同步下載。
import os
os.chdir('/content/drive/MyDrive/Colab Notebooks') # Colab 換路徑使用
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
def download(num):
try:
web = requests.get(f'https://tw.portal-pokemon.com/play/pokedex/{num}')
soup = BeautifulSoup(web.text, "html.parser")
img = soup.select('meta[property="og:image"]')
imgUrl = img[0]['content']
imgFile = requests.get(imgUrl)
f = open(f'pokemon/{num}.png', 'wb')
f.write(imgFile.content)
f.close()
print(num)
except:
print('error')
pass
numArr = [f'{j:04d}' for j in range(1,10)] # 建立圖片檔名清單
executor = ThreadPoolExecutor() # 建立非同步的多執行緒的啟動器
with ThreadPoolExecutor() as executor:
executor.map(download, numArr) # 同時下載圖片
程式執行後,就會看見圖片「幾乎同時」下載到電腦裡。

如果要用爬蟲下載大量圖片,使用「非同步」( 多執行緒平行處理 ) 的方式是相當方便的做法,不僅不用一張張的等待,更能發揮閒置 CPU 最大的效益 ( 同一時間裡可以做很多事情 )。
大家好,我是 OXXO,是個即將邁入中年的斜槓青年,我有個超過一千篇教學的 STEAM 教育學習網,有興趣可以參考下方連結呦~ ^_^


 iThome鐵人賽
iThome鐵人賽