以下針對 Production stage 的重點部分作說明。
ML engineers 擁有 production 環境的權限,也就是可以佈署 ML pipeline。這些 pipeline 會計算新的 feature 值,訓練和測試新的 model 版本,將預測結果發佈到下游的 table 或是應用程式,並且監控整個過程,以避免性能下降和不穩定。
資料科學家通常沒有 production 環境的權限,但是他們需要能夠看到測試結果、log、model artifacts、production pipeline 的狀態,以便他們能夠在 production 環境中識別和診斷問題。
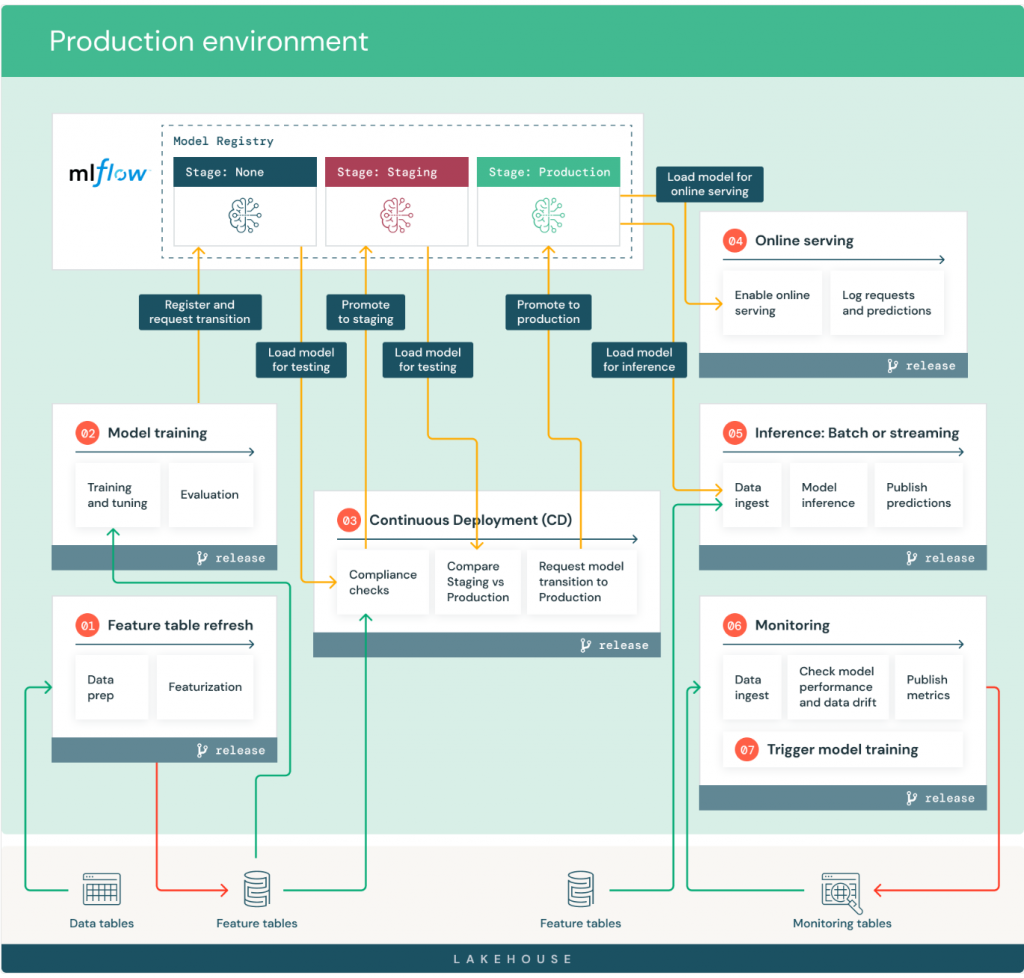
針對上面這張圖來說明。
一旦新的 production data 可用,這個 pipeline 就會將其載入並更新 production feature store tables。這個 pipeline 可以作為 batch 或是 streaming job 執行,並且可以排程、觸發或是持續執行。
就是使用 production data 來訓練 model,並且將 model 透過 MLflow 註冊到 Model Registry。這個 pipeline 可以由程式碼變更或是自動重新訓練的 job 觸發。
包括了兩種 Tasks:
可以透過 webhooks 或是自己的 CD 系統來實現。包括三種 Tasks:
透過 REST API 來提供服務,並且透過 Model Registry 來管理 model 版本。每次 request 都會從 online Feature Store 中取得 feature,並且透過 model 來預測。可以透過 serving system、data transport layer 或是 model 來記錄 request 和 prediction。
一般實作方式就是 Databricks Model Serving 或是其他 Cloud provider 的 ML serving system。
如果是要考慮較好的成本效益的話,可以考慮 Batch。如果是要考慮較好的 latency 的話,可以考慮 Streaming。
監控方向可以考慮三種 Tasks:
這應該是 MLOps 最重要的一環,也就是如何觸發 model retraning。然而觸發 retraining 的機制實在是因應不同的情境而有所不同,以底下兩個方向提供後續調整:
Refernce: https://docs.databricks.com/en/machine-learning/mlops/mlops-workflow.html


 iThome鐵人賽
iThome鐵人賽