在前面幾天我們分享了Autoencoder的架構,以及實作了DAE、CAE和VAE等許多變體,而今天呢將會分享模型優化的部分
模型優化確實是所有過程中最極其複雜的一環,它需要透過深刻的經驗和大量的時間,才能將模型調整到最接近完美的狀態。
模型的優化有以下這些方法:
嘗試調整編碼器和解碼器結構,包括增加或減少層數和節點數,以找到更好的表示學習和重建性能,但是增加層數可能會增加電腦的資源消耗

使用正規化技術,如L1或L2正規化,來限制權重的大小,減少過擬合。
L1正規化能夠將模型的複雜度簡化,將模型裡所有的參數都取絕對值。沒有用的權重設為0,留下模型認為重要的權重。
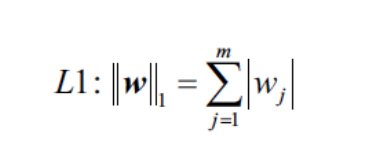
L2正規化是把模型裏頭所有的參數都取平方求和。簡單來說就是削弱所有權重並保留,讓所有權重與神經元都處於活動狀態。
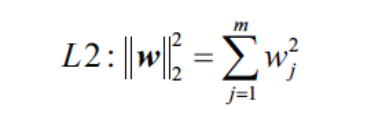
圖源:Blog
增加訓練數據可以提高模型的性能,也可以更好抓住特徵。
根據需求,可以嘗試不同的損失函數,如均方誤差(MSE)、二元交叉熵等。
確保數據預處理步驟正確,包括歸一化、標準化等。
對於目標需求,也可以使用不同的模型,如CAE或DAE。

這是我每次看到訓練結果的反應XD
以上就是今天分享優化模型的內容啦,我們的Autoencoder之旅也到一段落了,明天開始將會介紹生成對抗網路(GAN),那我們明天見!


 iThome鐵人賽
iThome鐵人賽