除了採用「刪除」的方式清理資料外,為確保數據的完整性,「填補」的操作也是另一種常見的方式,本文將說明資料清理中有關填補的操作方法,內容包含:
基本資料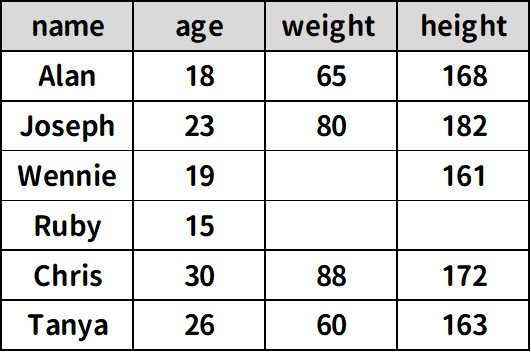
程式碼
import pandas as pd
import numpy as np
data = {'name':['Alan','Joseph','Wennie','Ruby','Chris','Tanya'],
'age':[18,23,19,15,30,26],
'weight':[65,80,np.nan,np.nan,88,60],
'height':[168,182,161,np.nan,172,163]}
df = pd.DataFrame(data)
使用 Pandas 提供的 fillna( value , inplace = True 或 False) 語法進行快速填補。
舉例:將案例中有缺失的 weight 統一填補為60公斤,height 統一填補為165公分
df['weight'].fillna(60,inplace=True) # weight以60填補
df['height'].fillna(165,inplace=True) # height以165填補
print(df)
輸出結果: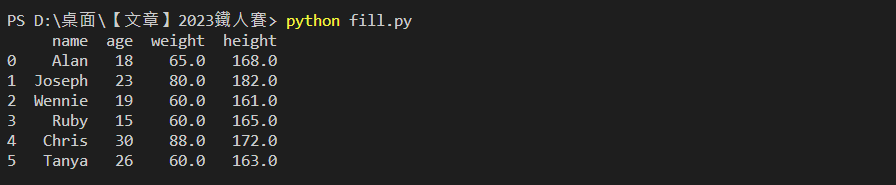
使用平均數 mean()、中位數 median() 或眾數 mode(),搭配 fillna() 語法進行填補。
# 以平均數(73.25)填補
mean_value = df['weight'].mean()
df['weight'].fillna(mean_value,inplace=True)
print(df)
輸出結果: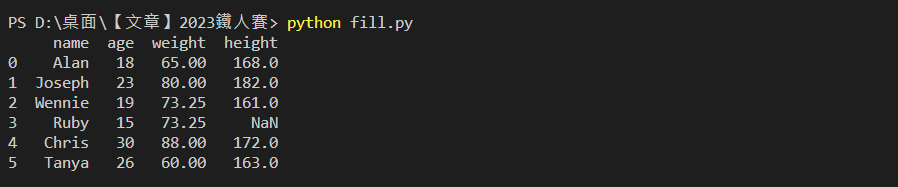
2. 舉例:以中位數填補案例中有缺失的 weight
# 以中位數(72.5)填補
median_value = df['weight'].median()
df['weight'].fillna(median_value,inplace=True)
print(df)
輸出結果:
3. 舉例:以眾數填補案例中有缺失的 weight
⚠️ 眾數
mode()操作時,需指定索引值帶入數值!
越頻繁出現的數值會排在越前面,數值出現次數相同,則以升冪排序。
# 以眾數(60)填補
mode_value = df['weight'].mode()[0]
df['weight'].fillna(mode_value,inplace=True)
print(df)
輸出結果:
使用 Pandas 提供的 interpolate ( method , inplace = True 或 False ) 填補。
舉例:以插值法填補案例中有缺失的 height
# 插值法(166.5)填補
value = df['height'].interpolate()
df['height'].fillna(value,inplace=True)
print(df)
輸出結果:
以上是一些常見的填補方式,如果有任何不理解、錯誤或其他方法想分享的話,歡迎留言給我!也提醒大家,進行填補前,應思考數據的特性採用最適合的方法,才不會對分析或建模產生不良影響唷!
我是 Eva,一位正在努力跨進資料科學領域的女子!我們下一篇文章見!Bye Bye~
【本篇文章將同步更新於個人的 Medium,期待與您的相遇!】

