這篇文章會使用 Python 的 Requests 函式庫,前往 Yahoo 股市的頁面,實作從網頁 HTML 裡,爬取指定上市公司股票即時股價的網路爬蟲。
原文參考:爬取 Yahoo 股市即時股價
本篇使用的 Python 版本為 3.7.12,所有範例可使用 Google Colab 實作,不用安裝任何軟體 ( 參考:使用 Google Colab )
通常比較大型的數據分析公司要取得即時股價資訊,會串接台灣證券交易所的即時股價 API,進一步得到即時資訊,但相對必須支付年費,因此,如果是個人或作為練習使用,可以前往「Yahoo 股市」,透過靜態網頁爬蟲的方法,取得某支股票的即時股價。
開啟 Yahoo 股市網頁後,在搜尋欄位輸入指定的股票名稱或代號,就能搜尋出對應的股票,本篇文章搜尋「台積電」作為範例。
Yahoo 股市:https://tw.stock.yahoo.com/
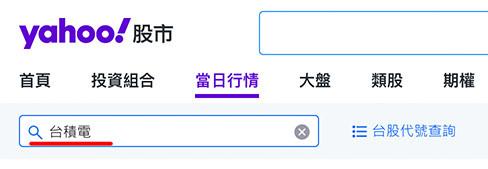
開啟台積電即時股價的網頁後,目標要抓取「股票名稱」、「即時價格」和「漲跌幅」( 下圖紅色框的內容 )
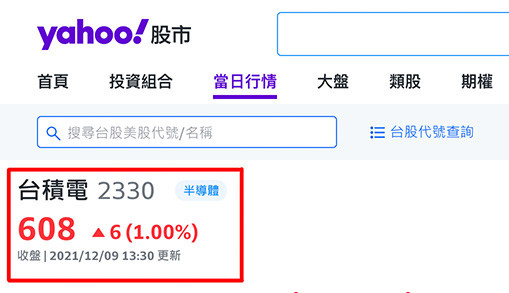
將滑鼠移到台積電名稱的上方,按下右鍵,選擇「檢查」,查看該名稱在 HTML 裡的位置和長相。
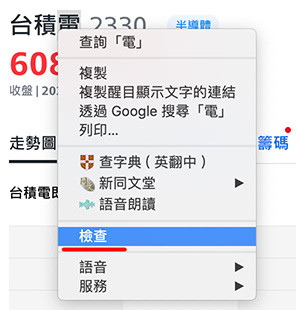
點擊檢查後,Chrome 瀏覽器會開啟「開發者工具」,工具裡 Elements 頁籤會顯示網頁目前的 HTML 結構,從中可以看到一個 id 為 main-0-QuoteHeader-Proxy 的 div 裡,包含 h1 的股票名稱標題,以及相關的股價資訊。
正常的網頁裡,id 和 h1 都只會存在一個 ( 不會有兩個重複的 id 或重複的 h1 )。
再開啟網頁的原始碼 ( 滑鼠在網頁的任意位置按下右鍵,選擇「檢視網頁原始碼」),檢查原始碼裡是否包含這些資訊,檢查後發現原始碼內也有這些內容,所以就能夠用靜態網頁的爬蟲抓取資料。
如果網頁原始碼和開發者工具的 HTML 的內容不同,表示這個網頁可能是「動態」產生內容,就必須要用動態網頁的爬蟲方式爬取資料。
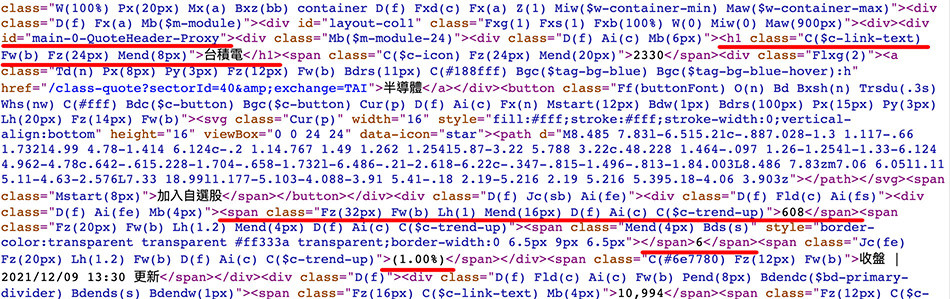
從原始碼裡看到 id、class 和 h1 之後,就可以使用 requests 與 Beautiful Soup 函式庫爬取所需的內容,當中使用了 try...except 的方式,判斷是否具有代表上漲或下跌的 class 名稱,下方的程式執行後,就會印出股票名稱、股價以及漲跌幅。
參考:Requests 函式庫、Beautiful Soup 函式庫、例外處理 ( try、except )、文字格式化 f-string
import requests
from bs4 import BeautifulSoup
url = 'https://tw.stock.yahoo.com/quote/2330' # 台積電 Yahoo 股市網址
web = requests.get(url) # 取得網頁內容
soup = BeautifulSoup(web.text, "html.parser") # 轉換內容
title = soup.find('h1') # 找到 h1 的內容
a = soup.select('.Fz(32px)')[0] # 找到第一個 class 為 Fz(32px) 的內容,如果出現錯誤,可以使用 .Fz\(32\) 轉義
b = soup.select('.Fz(20px)')[0] # 找到第一個 class 為 Fz(20px) 的內容,如果出現錯誤,可以使用 .Fz\(32\) 轉義
s = '' # 漲或跌的狀態
try:
# 如果 main-0-QuoteHeader-Proxy id 的 div 裡有 C($c-trend-down) 的 class
# 表示狀態為下跌
if soup.select('#main-0-QuoteHeader-Proxy')[0].select('.C($c-trend-down)')[0]:
s = '-'
except:
try:
# 如果 main-0-QuoteHeader-Proxy id 的 div 裡有 C($c-trend-up) 的 class
# 表示狀態為上漲
if soup.select('#main-0-QuoteHeader-Proxy')[0].select('.C($c-trend-up)')[0]:
s = '+'
except:
# 如果都沒有包含,表示平盤
s = '-'
print(f'{title.get_text()} : {a.get_text()} ( {s}{b.get_text()} )') # 印出結果
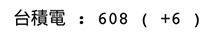
順利爬取即時股價後,搭配 concurrent.futures 內建函式庫,就能夠同時 ( 接近同時 ) 抓取多支股票的股價。
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
# 建立要抓取的股票網址清單
stock_urls = [
'https://tw.stock.yahoo.com/quote/2330',
'https://tw.stock.yahoo.com/quote/0050',
'https://tw.stock.yahoo.com/quote/2317',
'https://tw.stock.yahoo.com/quote/6547'
]
# 將剛剛的抓取程式變成「函式」
def getStock(url):
web = requests.get(url)
soup = BeautifulSoup(web.text, "html.parser")
title = soup.find('h1')
a = soup.select('.Fz(32px)')[0] # 如果出現錯誤,可以使用 .Fz\(32\) 轉義
b = soup.select('.Fz(20px)')[0] # 如果出現錯誤,可以使用 .Fz\(32\) 轉義
s = ''
try:
if soup.select('#main-0-QuoteHeader-Proxy')[0].select('.C($c-trend-down)')[0]:
s = '-'
except:
try:
if soup.select('#main-0-QuoteHeader-Proxy')[0].select('.C($c-trend-up)')[0]:
s = '+'
except:
state = ''
print(f'{title.get_text()} : {a.get_text()} ( {s}{b.get_text()} )')
executor = ThreadPoolExecutor() # 建立非同步的多執行緒的啟動器
with ThreadPoolExecutor() as executor:
executor.map(getStock, stock_urls) # 開始同時爬取股價

這篇教學整合了三種函式庫的應用,包含 Requests、Beautiful Soup 和 concurrent.futures,除了單純地取得靜態網頁股價,也可以同時抓取多個網頁的資訊,最後,也可以嘗試看看配合 CSV 函式庫,就能將抓取的股價,存到 CSV 檔案裡。
大家好,我是 OXXO,是個即將邁入中年的斜槓青年,我有個超過一千篇教學的 STEAM 教育學習網,有興趣可以參考下方連結呦~ ^_^


 iThome鐵人賽
iThome鐵人賽