這篇文章會解析 LINE TODAY 的留言頁面,搭配 Python 的 Requests 函式庫,實作一個可以爬取 LINE Today 某篇文章所有留言的網路爬蟲。
原文參考:爬取 LINE TODAY 留言
本篇使用的 Python 版本為 3.7.12,所有範例可使用 Google Colab 實作,不用安裝任何軟體 ( 參考:使用 Google Colab )
使用 Chrome 瀏覽器,開啟 LINE TODAY 的頁面,點選任意一篇文章,開啟文章頁面。
LINE TODAY:https://today.line.me/tw/v2/tab
本篇範例開啟了一篇「英特爾基辛格已抵台 錄影片讚聲台積電」的文章。
將文章往下捲動,找到留言的位置,點擊「顯示全部」,會開啟留言的頁面。
文章對應的留言頁面:https://today.line.me/tw/v2/comment/article/oqay0ro
開啟留言頁面後,在網頁的任意位置,按下滑鼠右鍵,點擊「檢視」,開啟 Chrome 開發者工具,切換到「Network」頁籤,在 Network 頁籤裡,可以看到網頁開啟時,所有透過網路下載或上傳的內容 ( 如果沒有看到內容,重新整理網頁就會看到 )。
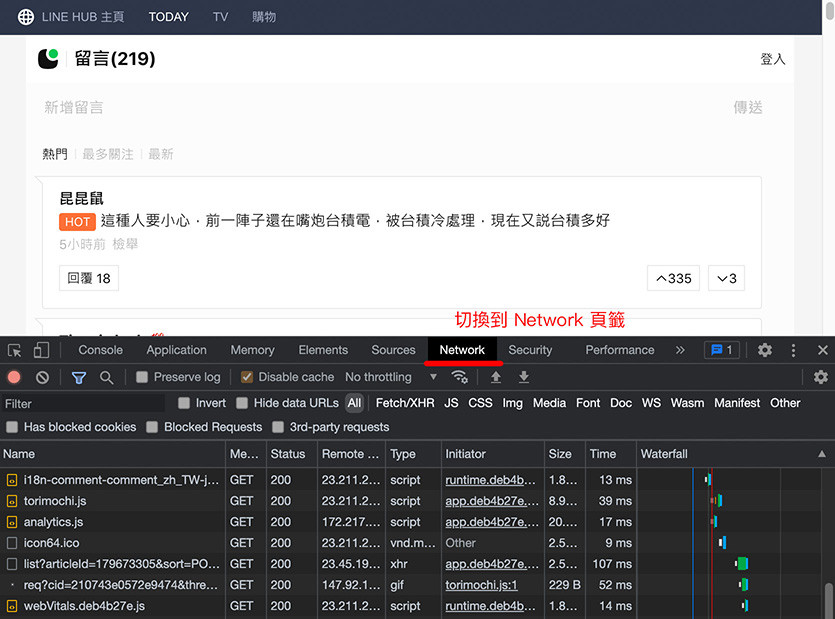
點擊前方的清除按鈕,清空內容 ( 方便待會觀察出現哪些項目 ),再將子頁籤切換到「Fetch/XHR」,該頁籤表示有哪些 XMLHttpRequest 物件在交換溝通。
重新整理網頁,開發者工具中就會陸續出現一些物件,在畫面裡找到名為「list?articleId=.....」的項目,點選這個項目,就能看到該文章的有多少留言以及所有留言的內容。
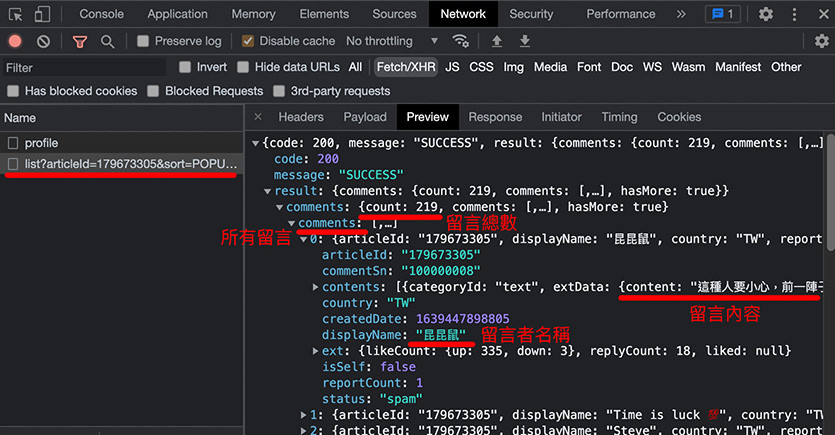
觀察一下這個物件的網址 ( 可以在該項目上按下滑鼠右鍵,開啟到新的 tab 裡 ),可先注意這篇文章的 articleId、每次顯示留言的數量 limit 和第二頁開始的次序 pivot。
https://today.line.me/webapi/comment/list?articleId=179673305&sort=POPULAR&direction=DESC&country=TW&limit=30&pivot=0&postType=Article
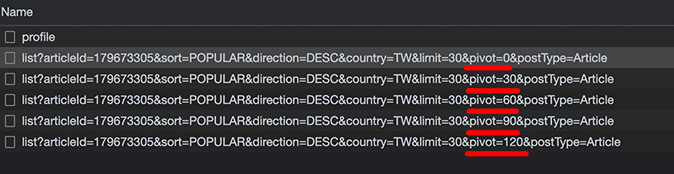
因為留言物件的網址數量 limit 設定為 30,所以如果該網頁的留言很多 ( 範例網頁有超過兩百則留言 ),會產生「不止一筆」留言物件,這時從開發者工具裡就會看到 pivot=0、pivot=30、pivot=60...等的留言物件網址。
由於文章的網址並沒有 articleId,表示網頁一定是透過某些機制將網址對應到 articleId,檢視網頁原始碼後 ( 在網頁上點擊滑鼠右鍵,點選檢視網頁原始碼 ),搜尋 179673305 ( 這篇文章的 articleId ),會發現網頁原始碼有撰寫了相對應的轉換程式,如何轉換並不重要,重要的是記住下圖標註紅色的位置,待會會透過程式擷取對應的 articleId。
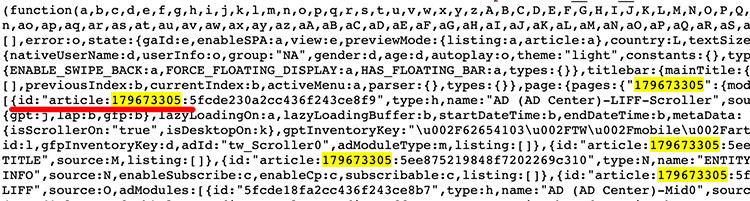
由於 Fetch/XHR 的網址使用的是 articleId,所以必須先從原本的網址裡提取 articleId ( 目的在於如果有多個頁面,就不用一一開啟開發者工具找 articleId ),下方的程式碼執行後,會印出該篇文章的 articleId。
import requests
webUrl = requests.get('https://today.line.me/tw/v2/article/oqay0ro') # get 文章網址
# 取得文章的原始碼後,使用 split 字串拆分的方式,拆解出 articleId
article_id = webUrl.text.split('<script>')[1].split('id:"article:')[1].split(':')[0]
print(article_id)
取得 articleId 後,將使用變數與字串格式化的方式,將留言物件的 articleId 更換成該篇文章的 articleId,再度使用 requests,取得 json 格式的內容,並印出文章的總數。
import requests
webUrl = requests.get('https://today.line.me/tw/v2/article/oqay0ro') # get 文章網址
# 取得文章的原始碼後,使用 split 字串拆分的方式,拆解出 articleId
article_id = webUrl.text.split('<script>')[1].split('id:"article:')[1].split(':')[0]
print(article_id)
# 使用 requests get 留言物件
comment = requests.get(f'https://today.line.me/webapi/comment/list?articleId={article_id}&sort=POPULAR&direction=DESC&country=TW&limit=30&pivot=0&postType=Article')
json = comment.json() # 取得內容後,轉換成 json 格式
num = int(json['result']['comments']['count']) # 取得文章的總數
print(num) # 印出文章總數

由於留言筆數過多時 ( 每頁留言一次顯示最多 100 篇 ),留言的物件會拆分成不同的項目,所以下方的程式定義了一個 getComment 函式,在函式執行時賦予「pivot」( 下一頁從第幾筆留言開始 ) 的參數,並透過 range 和 for 迴圈的搭配,就能印出所有的留言。
import requests
webUrl = requests.get('https://today.line.me/tw/v2/article/oqay0ro')
article_id = webUrl.text.split('<script>')[1].split('id:"article:')[1].split(':')[0]
print(article_id)
commentUrl = requests.get(f'https://today.line.me/webapi/comment/list?articleId={article_id}&sort=POPULAR&direction=DESC&country=TW&limit=30&pivot=0&postType=Article')
json = commentUrl.json()
num = int(json['result']['comments']['count'])
print(num)
# 定義函式,給予一個參數
def getComment(n):
# 使用字串格式化的方式,讓網址會根據不同的參數而有所不同
commentUrl = requests.get(f'https://today.line.me/webapi/comment/list?articleId={article_id}&sort=POPULAR&direction=DESC&country=TW&limit=30&pivot={n}&postType=Article')
json = commentUrl.json() # 取得對應網址的 json 內容
comments = json['result']['comments']['comments'] # 取得該網址下所有留言
for i in comments :
# 印出留言者名稱以及留言內容
print('<' + i['displayName'] + '>\n' + i['contents'][0]['extData']['content'])
print('----------------')
for i in range(0, num, 30):
getComment(i) # 從 0 開始,每隔 30 筆取一次

一個網頁在顯示的過程中,背後可能不斷的在與後端交換資料,只要善用 Chrome 的開發者工具,可以從中獲得很多在網頁上看不到的內容,搭配 Python 的函式庫,就能輕鬆抓取各種網頁內容了。
大家好,我是 OXXO,是個即將邁入中年的斜槓青年,我有個超過一千篇教學的 STEAM 教育學習網,有興趣可以參考下方連結呦~ ^_^


 iThome鐵人賽
iThome鐵人賽