在訓練模型時,有時會被一些專有名詞搞混,像一個參數就有分「參數」和「超參數」,今天我們要來搞清楚這兩個名詞的差異啦 ~

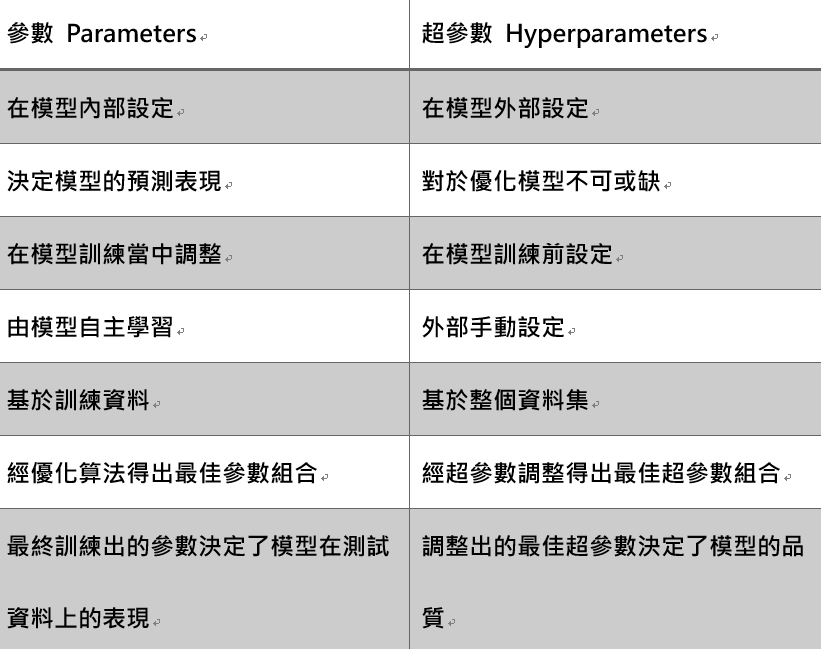
在機器學習中,「參數」常指模型中需要透過訓練,從資料中學習得到的可調整的數值。這些參數決定了模型的預測表現,通常會根據訓練數據進行調整,以最小化預測誤差。
「超參數」是在機器學習模型中需要手動設置的參數,超參數是在訓練模型之前需要手動設定的參數,通常不在模型的內部進行學習,因此不能通過訓練過程自動學習得到,而是需要通過方法調整來找到最佳的值。超參數的設置會直接影響模型的性能,因此在建立模型過程中通常會預設一組超參數,之後再慢慢調整。
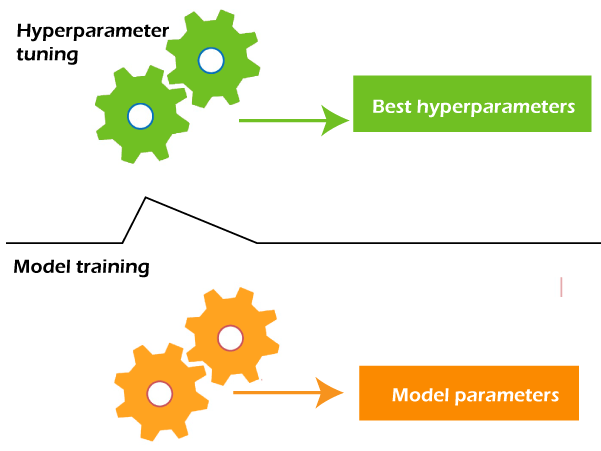
參數的優化會在模型訓練中,經模型的優化算法逐步學習出最佳的參數解。
至於超參數,選擇最合適的超參數組合對於模型的性能和訓練速度極其重要,而這往往需要特殊方法來找到最佳的超參數值,這過程通稱超參數調整 Hyperparameter Tuning,常見的包括網格搜索 ( Grid Search )、隨機搜索 ( Random Search ) 方法,這些方法可稱作超參數調整器 Hyperparameter Tuner,細節明天會再提到。
今天我們了解到了參數與超參數之間的差異,並且用不同的方法為了找出各自的最佳解,一個好的超參數組合與參數組合能夠使模型有更好的泛化能力 ( Generalization ),對於模型泛化能力的評估,我們通常會用到交叉驗證 ( Cross-Validation ) 的方法來實現,這部分在明天會和各位介紹,還有超參數調整的部分也是,那我們就下篇文章見咯 ~
https://www.javatpoint.com/model-parameter-vs-hyperparameter


 iThome鐵人賽
iThome鐵人賽