交叉驗證 ( Cross-Validation ) 是在機器學習中是一個評估模型性能的技術,從而使我們能更準確地估計模型在面對陌生資料的擬和能力,也就是模型的泛化能力 ( Generalization )。
防止模型過度擬和
在一般情況下,我們只會把資料集 ( Dataset ) 分成訓練集 ( Training Set ) 和測試集 ( Testing Set ),用訓練集來訓練模型,然後再用測試集評估模型的性能,而這種方式會導致模型可能在訓練集上的表現很好,但在訓練集或是沒看過的資料集上表現卻差強人意,這時使用交叉驗證就能有效的解決這種過度擬和 ( Overfitting ) 的問題。
更準確評估模型性能
把資料集單純分成訓練集和測試集進行模型評估可能會因為資料的分布、切分方式等因素而導致評估結果不穩定。交叉驗證通過切分資料集,使模型在多個不同的子集上進行訓練和測試,從而更準確地評估模型的性能,就好比我們用一組訓練集訓練,模型訓練出來的表現和用別的訓練集訓練的表現可能不同,模型在不同訓練集上預測能力存在著偏差,然後透過交叉驗證方法,將不同的資料集子集輪流當作訓練集訓練後平均模型的表現,就能夠更準確評估模型的性能。
交叉驗證最常見的方法就是用 K-Fold 交叉驗證法,可能用來優化你的模型找到最佳的一組超參數。
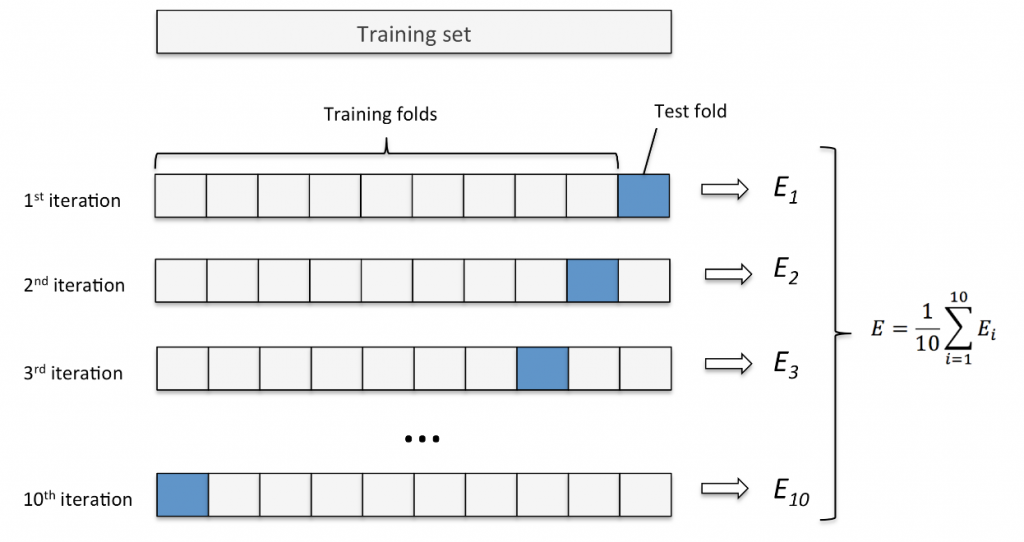
K-fold ( K 折 ) 交叉驗證是一種常見的交叉驗證方法,目標能夠準確估計模型的泛化能力,在實做這個方法前,我們會先把拿到的資料集 ( Original set ) 分成訓練集 T1 ( Training set ) 和測試集 ( Test set ),再將訓練集 T1 切分成訓練集 T2 和驗證集 ( Validation Set ),會基於這兩者做模型訓練、評估與參數調整,最後再用測試集評估模型的最終性能表現。

然後我們會讓訓練集 T2 切分成 K 個子集,其中一個子集作為驗證集 ( Test fold ) 測試,剩下的 K - 1 個子集當訓練集 ( Training folds ) 訓練,這樣的過程重複 K 次,每次都輪流讓不同的子集當驗證集,剩下當訓練集並求出模型的性能分數,如此我們就能掌握模型在不同訓練資料下的表現,把 K 次模型的性能分數平均起來就能夠得到模型的平均性能分數 ( Mean Validation Score )。
在調整超參數時,通常會用到網格搜索或隨機搜索方法來找出最佳的超參數組合,而這兩個方法和交叉驗證其實有著密切的關係。
網格搜索的基本概念是在指定的超參數範圍內進行網格狀的搜索。遍歷所有可能的超參數組合,針對每個組合訓練模型並依據其性能分數評估,最終選擇性能最好的一組超參數。下面是進行網格搜尋的流程:
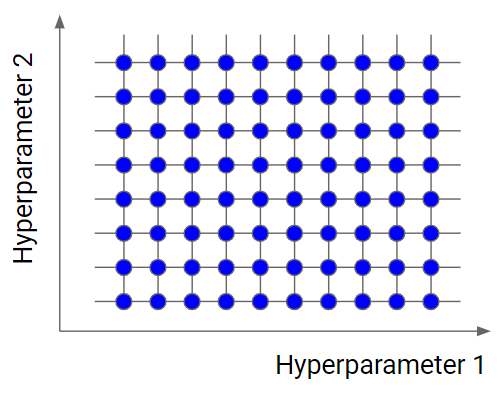
網格搜索的優點是較容易理解,並且能夠全面、有系統地列舉出所有超參數組合,找到最好的模型性能,相對地缺點就是在算每點的平均性能分數時,會用 K- Fold 交叉驗證,這意味者每點都要經過 K 次的迭代計算,因此當超參數組合一多時,時間成本可想而知,整個搜索的過程就會相當耗時。
隨機搜索這個方法相比於網格搜索,在搜索的過程中不需要遍歷所有的超參數組合,組合的數量可預先給定,接著在所有組合中隨機抽取不同的組合,最後再進行迭代搜索和評估,因此在搜索效率上會比網格搜索來的快速,因此適合用在較大參數空間的搜索。
至於找最佳超參數組合的流程就和網格搜尋相同,一樣會用到 K-Fold 交叉驗證算出網格上每點的平均效能分數,以評估模型的泛化能力。
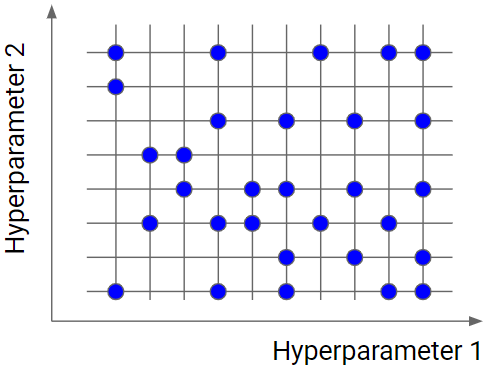
然而,因為隨機搜索不會搜尋網格上所有點,而是隨機抽取幾個點搜尋,因此有可能會因此錯過某些特定的模型而錯過平均性能分數高的點,下面是兩種搜索方法在不同方面的區別:

今天我們學習到:
在調整好模型的所有參數後,在我們就要來對模型進行評估,其中混淆矩陣是重要的評估標準,明天會先跟各位介紹什麼是混淆矩陣 ( Confusion Matrix ),那我們就下篇文章見 ~
https://www.yourdatateacher.com/2021/05/19/hyperparameter-tuning-grid-search-and-random-search/
https://www.javatpoint.com/cross-validation-in-machine-learning
http://karlrosaen.com/ml/learning-log/2016-06-20/


 iThome鐵人賽
iThome鐵人賽