到目前為止,分享了一些模型學習的方法,現在要來寫些比較輕鬆的內容,來聊聊模型的評估指標
在前面的分享中,有很多方式可以選擇要如何訓練模型,但是要怎麼知道模型是否有學好呢?
我們會需要一些特殊的規則和方式來檢查它的表現。這就是今天要討論的主題:分類模型的評估指標
首先,想像你正在玩一個辨識圖片中的動物是貓還是狗的遊戲,當看完了所有圖片,就可以看到遊戲的得分數,這時,你可能會發現回答的正確率並沒有百分之百,也就是代表有些圖片沒有選擇正確,有些辨識錯了。這就是為什麼我們需要評估指標,就像是遊戲的比分卡一樣,它可以顯示你在遊戲中表現得怎麼樣。
會是一個 NXN 的矩陣,N 代表了所有可能的標籤類別的數量,可以用來呈現分類模型的效果
以下用一個二分類的模型(N=2,只有兩種可能的標籤)當作例子: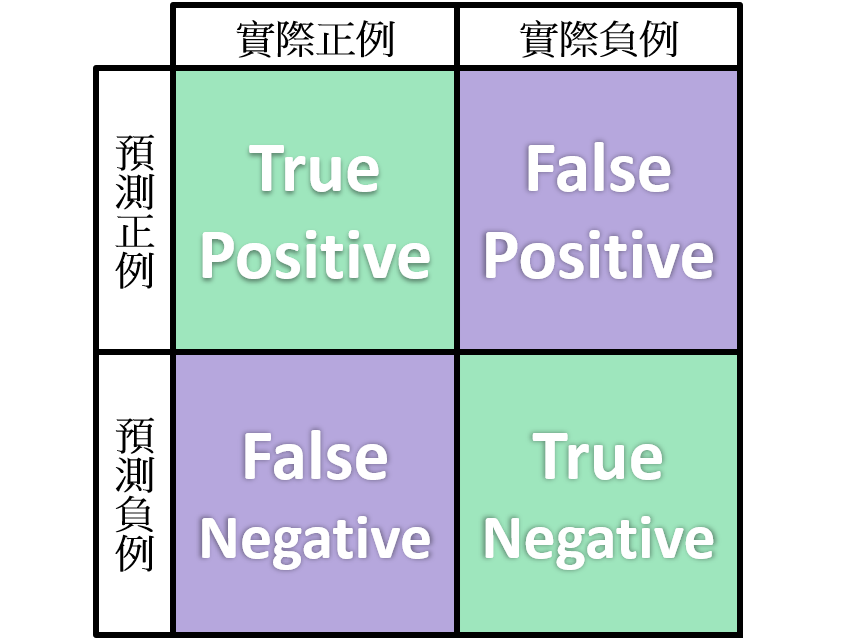
有了這些術語的基礎,接下來是可以基於 Confusion Matrix 算出的一些常見評估指標:
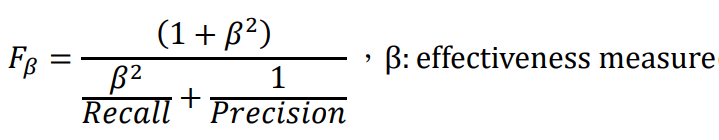
這些評估指標可以幫助我們更全面地了解模型的性能,並確保不會只關注模型的準確性,還會關注其他重要的因素,像是錯誤的類型和分類結果的分布


 iThome鐵人賽
iThome鐵人賽