在測試中,同一個功能都會需要很多測試資料的組合來測試。若每一組 Test Data 都寫成一個測試用例,要寫的測試用例的數量就非常多了,且重覆性會很高,因此我們需要學習用 Data Driven Testing (DDT 數據驅動測試) 的方式去撰寫自動化測試。
此外,有些測試資料並非因 Test Case 而改變,而是因測試環境改變,我們把它會存成環境變數,以方便更動。此外,環境變數還有一個用途就是用來存機密的資料。這一篇就來說說 Test Data 和 環境變數 的應用。
@pytest.mark.parametrize 實現 DDTDDT (Data Driven Testing) 是一種測試方法,透過使用 不同的測試數據 來執行 相同的測試用例,以驗證系統在不同情況下的行為。在自動化測試中,DDT 通常涉及將測試數據從外部源(如 Excel 表格、CSV 文件、數據庫等)讀取,然後用於執行 Test Case。
在 pytest 中可以用 @pytest.mark.parametrize 來實現 DDT,把數據參數化,通過對參數的賦值來驅動測試用例的執行。
# 以 num 存放 3 個測試數據,以參數的形式傳入 test case
# 這 Test Case 將會執行 3 次,而每次帶入不同的測試數據
@pytest.mark.parametrize("num", [1, 2, 3])
def test_number(num):
print(f"Current Number : {num}")
# 以可以傳入多組參數,以 Tuple List 的形態傳入。
@pytest.mark.parametrize("num, result", [(1, 2), (2, 3), (3, 4)])
def test_add_1(num, result):
assert num + 1 == result
Output:
tests/test_param.py::test_number[1] Current Number : 1
PASSED
tests/test_param.py::test_number[2] Current Number : 2
PASSED
tests/test_param.py::test_number[3] Current Number : 3
PASSED
tests/test_param.py::test_add_1[1-2] PASSED
tests/test_param.py::test_add_1[2-3] PASSED
tests/test_param.py::test_add_1[3-4] PASSED
為了更好管理測試的數據,我們可能會用到 Excel / Database 來存放大量測試數據。我們之前已經學過怎樣讀取 Excel 跟 Database 的資料,可把這些內容寫成 function,回傳成 @pytest.mark.parametrize 傳參數的格式,即可為 Test Case 帶來不同的測試數據。以下是簡單的例子,會應用在 Day 07 所建的 Excel File。個人習慣 Test Data 都會存放在同一個資料夾以方便查閱,所以這裡建一個 /test_data 資料夾,再放入 Excel 檔案。
import pandas as pd
import pytest
def read_excel():
score_df = pd.read_excel('test_data/score_table.xlsx')
reading_score_list = []
for index, row in score_df.iterrows():
data = {
"Reading": row["Reading"],
"Writing": row["Writing"],
"Listening": row["Listening"],
"Speaking": row["Speaking"],
}
# 以 dict 型別存成 list
reading_score_list.append(data)
# 回傳作為 test case 的參數列,使用 dict list 可以一次傳入多個 test data
return reading_score_list
# 在 @pytest.mark.parametrize 應用 function,則會以 function 的回傳值作為參數
@pytest.mark.parametrize("score_dict", read_excel())
def test_score(score_dict):
print(f"Current Score Info: {score_dict}")
Output:
tests/test_excel.py::test_score[score_dict0] Current Score Info: {'Reading': 80, 'Writing': 80, 'Listening': 75, 'Speaking': 88}
PASSED
tests/test_excel.py::test_score[score_dict1] Current Score Info: {'Reading': 88, 'Writing': 95, 'Listening': 86, 'Speaking': 90}
PASSED
tests/test_excel.py::test_score[score_dict2] Current Score Info: {'Reading': 92, 'Writing': 98, 'Listening': 85, 'Speaking': 92}
PASSED
tests/test_excel.py::test_score[score_dict3] Current Score Info: {'Reading': 81, 'Writing': 82, 'Listening': 88, 'Speaking': 80}
PASSED
tests/test_excel.py::test_score[score_dict4] Current Score Info: {'Reading': 75, 'Writing': 80, 'Listening': 80, 'Speaking': 78}
PASSED
通常是為了提高程式的可配置性和安全性。我們會用 .env 來存放環境變數。
需注意的是,這個 .env 一般都不建議上傳到 Git 儲存庫,因為當中可能含有機密性的資料,可能導致資料外洩,從而危及系統和數據的安全。因此在專案會應用 .gitignore 防止 .env 檔上傳,另一方面會做一個 .env.sample 的範本,讓團隊成員在自己的本地環境中創建 .env 檔案。
以下是一些應該考慮設定為環境變數的資料類型:
需要在 Python 安裝 pytest-dotenv 套件,會自動讀取 .env 的資料成環境變數
pip install pytest-dotenv
# .env
DOMAIN="http://www.example.com"
# test_a.py
import os
def test_a():
# 讀取環境變數 DOMAIN
print(os.environ.get("DOMAIN"))
Output:
http://www.example.com
Jenkins 執行的檔案是由 Git 儲存庫拉下來的,若我們把 .env 應用 .gitignore 以防止上傳,那 Jenkins 在執行時,則沒有環境變數可用。
這時候我們會把 .env 檔在 Jenkins 上存成 Secret File 。 Secret Text / Secret File 是儲存一些敏感的資訊的方式,將敏感資訊以加密的形式存儲在 Jenkins 中,並且可以在 Jenkins Job 中使用。可以降低數據外洩和機密泄漏的風險,同時提供了一個集中的地方來管理敏感資訊,有助於簡化 CI / CD 流程。
在 Jenkins Job 的 Configure 的 Build Environment,勾選 Use secret text(s) or file(s)
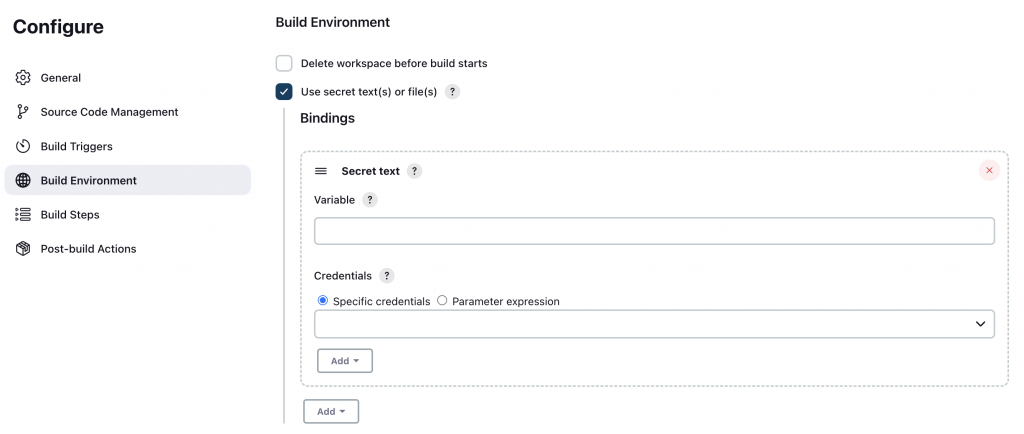
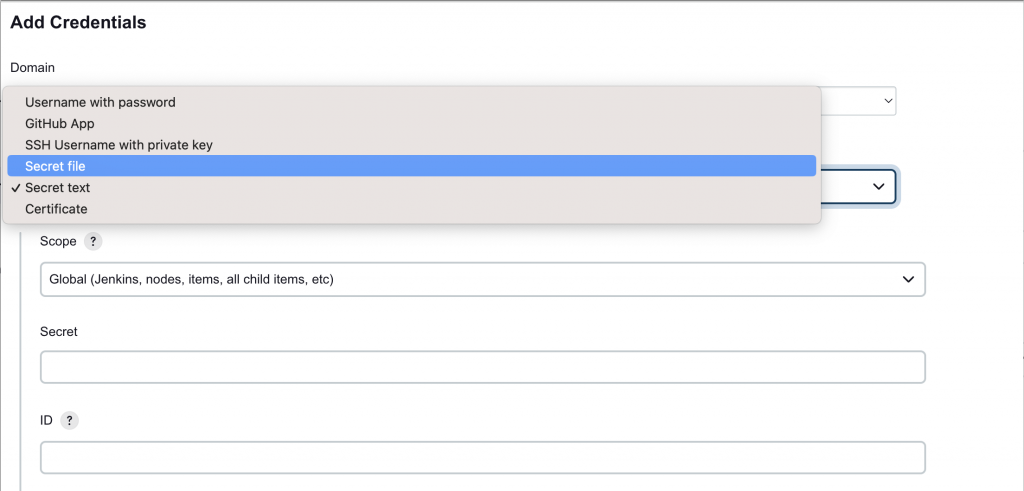
可以 Secret file / Secret text 的方式儲存資料。
Secret Text 的話,需要逐個輸入,Variable 的名字要跟 .env 的 variable name 一致。
如果資料多的話,可以考慮使用 Secret file,但應用 secret file 需要修改一下程式碼。
# 根目錄下的 Conftest.py
# 在 Jenkins 中 Secret File 的 Variable 命為 ENV_FILE
# 當環境變數含有 ENV_FILE 代表正在 Jenkins 上運行,應用 load_dotenv () 讀取 Secret File
# 若沒有 ENV_FILE,則會讀取本地的 .env 檔
if 'ENV_FILE' in os.environ:
env_file = os.environ['ENV_FILE']
load_dotenv(env_file)
# 這寫法可讓你在本地端 / Jenkins 都能正常運作而不用修改程式碼。
Ref: 官方文件 https://docs.pytest.org/en/7.3.x/how-to/parametrize.html


 iThome鐵人賽
iThome鐵人賽