2023 iThome 鐵人賽
分享至
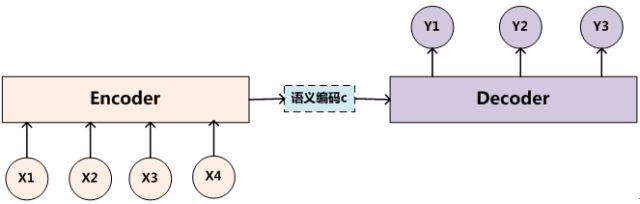
句向量Sentence Embedding:以句子為單位,以固定維數的向量來訓練學習與表示。
NLP使用以下演算法來對詞向量進行各種NLP的任務。
參考來源:人工智慧:概念應用與管理 林東清
IT邦幫忙


 iThome鐵人賽
iThome鐵人賽