GloVe詞向量Global Vectors for Word Representation:指的是一種詞與詞的共現矩陣Co-cooccurrence Matrix為核心所計算出來的一種詞向量。 步驟: ①根據語料庫建構一個共規矩陣來表達每個詞與其他文內所有詞在整個全局的語料庫中同時出現的次數。 ②根據共現關係,利用統計模式來估算每個詞的詞向量,使這個詞向量能準確表達兩個詞之間的共現特徵。 優點:全局性:能掌握每個詞與整個文本內所有詞的關係。
詞向量模式比較
詞向量優缺點
優點:
瞭解詞與詞之間的關係:瞭解詞與詞之間語意的相關性、相似性。
密集的向量表示Dense One Hot Encoding:詞向量是屬於密集的分布,每個維度都存在著有意義的權重,BOW的One Hot Coding是稀疏表示Spare One Hot Encoding其在文本的10萬向量中,只有一兩個參數值是1,其他都是0。
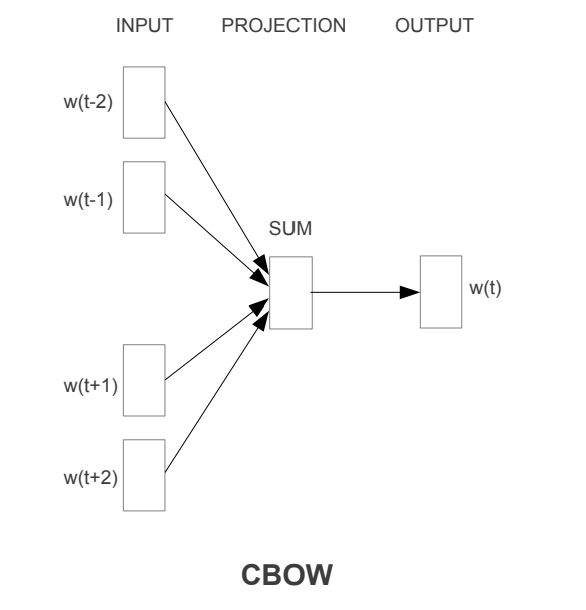
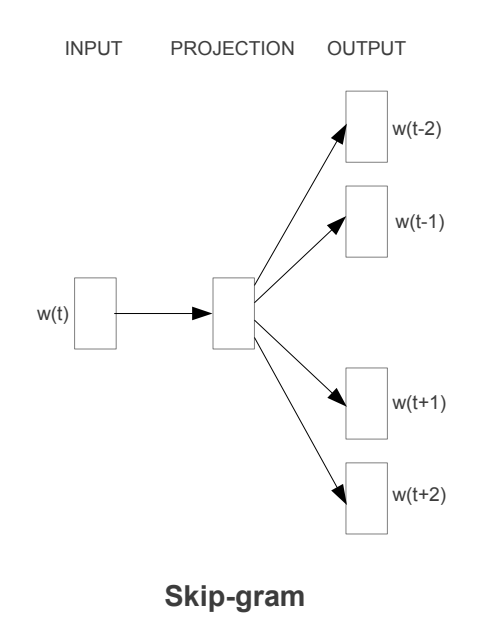



 iThome鐵人賽
iThome鐵人賽