在訓練完我們的模型之後,通常會用測試資料給我們的模型做測試,評估模型在測試資料上的表現,那要用什麼來評判這個模型的好壞呢?於是我們就用一些驗證指標 ( Validation Index ),用來當作評估模型表現的衡量標準,常用的指標有準確度 ( Accuracy )、精確度 ( Precision )、召回率 ( Recall )、F1 分數 ( F1 Score )、ROC 曲線、AUC 面積等,在計算這些指標之前,先讓我們來了解一下和驗證指標密不可分的混淆矩陣 ( Confusion Matrix ):
當我們用測試資料來測試模型的預測效能時,混淆矩陣它可以幫我們把模型預測的結果與真實資料 ( 測試資料標籤 ) 結果之間的關係顯示出來,就可以評估模型在真實資料上到底預測得準不準,今天我們就要在二元分類問題中,用模型的預測資料與真實資料得出我們的二元混淆矩陣。
下面定義了一個印出混淆矩陣的方法 show_confusion_matrix,傳入我們的模型預測資料跟真實資料,因為是二元分類,類別數量有兩個,模型輸出不是 0 ( Negative ) 就是 1 ( Positive ),因此傳入的 class_num=2,把所有參數都傳入方法後:
skm.confusion_matrix() 就會開始會針對我們傳入的真實資料和對應預測資料,進行比對並取得混淆矩陣,這邊也可以稱作二元混淆矩陣sns.heatmap() 會把混淆矩陣畫到圖上,並且搭配 plt 設定標籤和標題import sklearn.metrics as skm
import matplotlib.pyplot as plt
import seaborn as sns
# 混淆矩陣顯示方法
def show_confusion_matrix(y_true, y_pred, class_num):
cm = skm.confusion_matrix(y_true, y_pred)
plt.figure(figsize=(5, 4))
labels = np.arange(class_num)
sns.heatmap(
cm, xticklabels=labels, yticklabels=labels,
annot=True, linewidths=0.1, fmt='d', cmap='YlGnBu')
plt.title('Confusion Matrix', fontsize=15)
plt.ylabel('Actual label')
plt.xlabel('Predict label')
plt.show()
y_pred = [1, 0, 0, 0] # 預測資料
y_true = [0, 0, 1, 0] # 真實資料
show_confusion_matrix(y_pred, y_true, class_num=2)
最後就會得到我們的二元混淆矩陣結果:

得到的混淆矩陣中的每格其實都代表了一些重要的參數,這些參數可以用來計算之後的指標,如下:
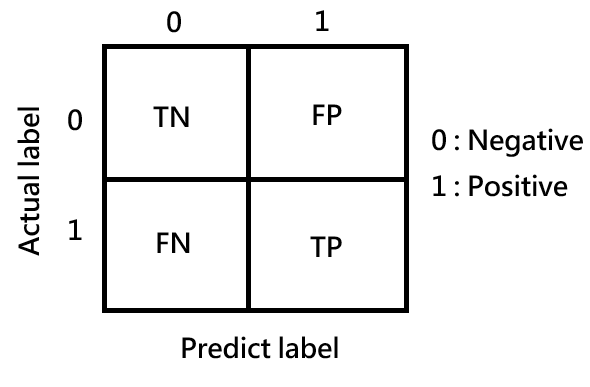
印出混淆矩陣的結果後,矩陣中的每一格都代表著橫軸預測資料對應到縱軸真實資料的數量,我們可以用醫療檢測模型對於患者的檢測來理解,0 代表陰性,1 代表陽性:
以上就是在二元分類問題中,在混淆矩陣中得到的參數說明,有了混淆矩陣就可以讓我們得以用這些參數去計算驗證指標評估模型的效能。
今天我們學會如何看懂二元分類的混淆矩陣,以及混淆矩陣代表的特性,像是真陰性 ( TN )、真陽性 ( TP )、假陰性 ( FN )、假陽性 ( FP ),明天我們將會根據這個混淆矩陣計算出它的各項驗證指標 ( Validation Index ),那我們就下篇文章見 ~


 iThome鐵人賽
iThome鐵人賽