昨天我們以精簡的內容來加深你對ELMo的理解,而內容簡短的原因除了其訓練方式與Word2Vec等相似之外,最主要的理由在於今天將介紹的內容極為重要,所以我希望你能將所有精力放在此次學習上,因這種語言模型在後續的發展中極具影響力,許多熱門的語言模型都是其的衍生的,包括當今最強的語言模型ChatGPT(更精確的說,是GPT-4)也使用這種架構,今天的學習重點如下:
Transformer架構與公式理解Self-Attention的實現方式Query、Key、Value之理解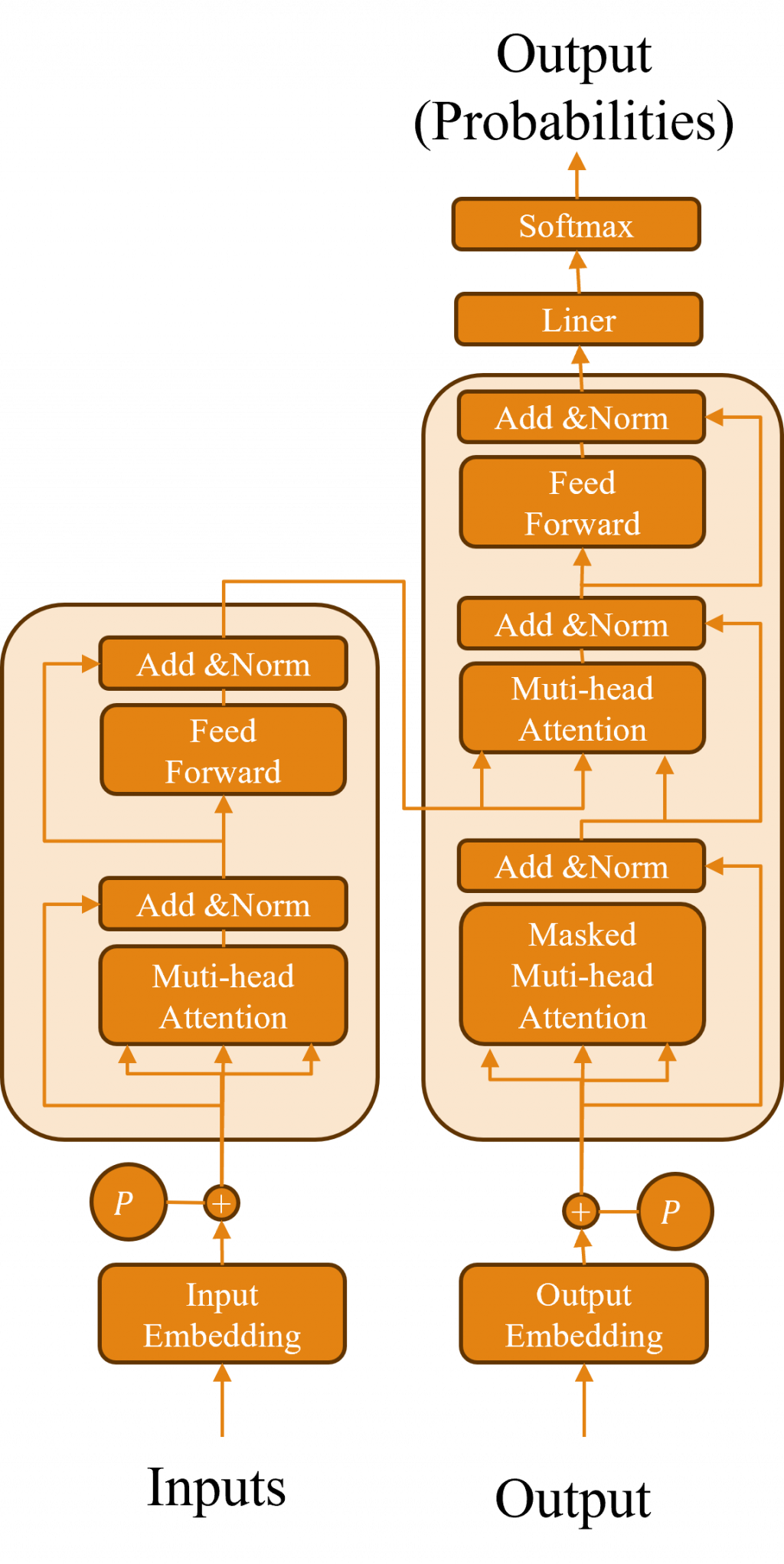
Transformer是一種衍生自Encoder-Decoder架構的變化方式,它於2017年最初出現在Attention Is All You Need(注意力機制就是你全部所需)的期刊論文中,它的設計理念具有革命性地影響了人工智慧領域,因為它不再依賴於傳統的時間序列模型,並且正如論文的名稱所述,這種架構能適用於音訊、文字、圖像等不同的場域,而這一點特性這都歸功於他所建立的Self-Attention(自注意力機制)概念,現在讓我們深度的解析該模型的架構吧。
小提示:
該架構需要具備Seq2Seq中的Attention知識,若有內容不清楚或不瞭解的,建議先看我在掌握文字翻譯的技術中所提到Attention理解與實作。
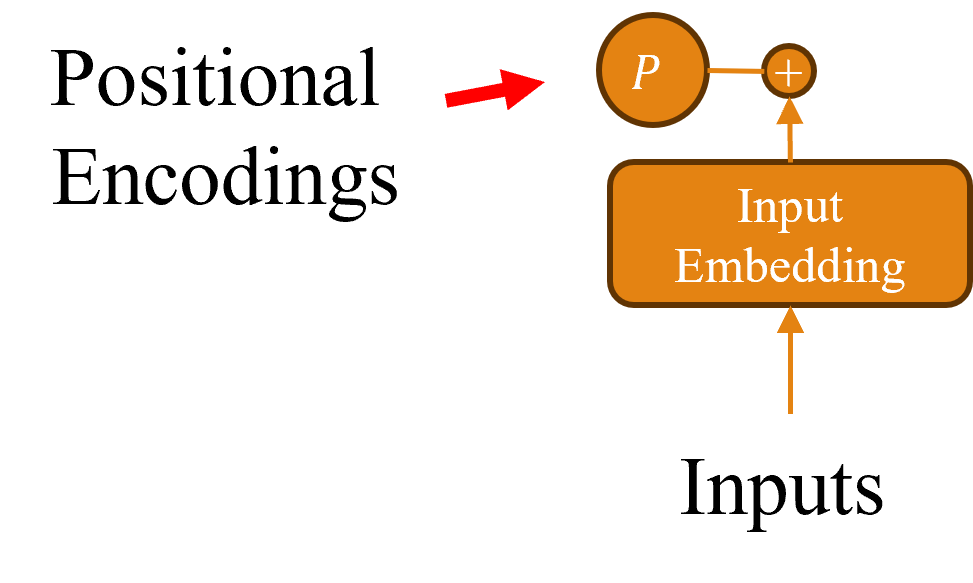
在Transformer中,由於其與時間序列模型模型不同,採取的是平行運算方式,所以對於每一個輸入的詞彙,該架構無法得知順序,因此我們需要在此步驟利用Positional Encoding對每個輸入進行編碼。讓我們先來看以下的公式: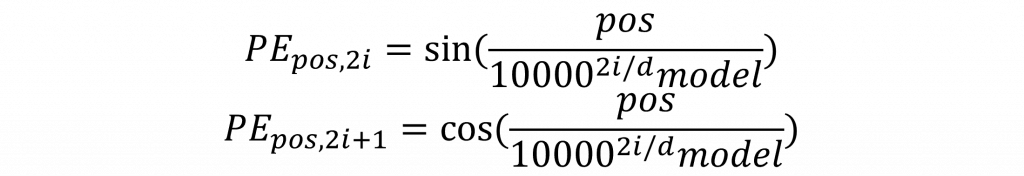
其中dmodel是指詞嵌入層的維度,i則代表該詞向量的第i個維度,而POS則表示輸入詞彙的位置,而該公式這樣的設計主要基於sin()和cos()函數的周期性特性,因為這兩種函數特別適合表現循環性的特徵,由於這種方法能讓數值的最初的序列與最後的序列在性質上更接近,因此能夠解決因詞彙距離過遠而產生的稀疏問題,進一步使模型能夠更好地學習詞與詞之間的相對位置關係。
在我們開始介紹Transformer Encoder之前,必須先理解Self-Attention這個機制,不過先讓我們來回顧一下Attention的概念,該方式是透過注意力權重a(t)來計算出Enocder隱狀態h(t)與Decoder的隱狀態hd(t),對於時間序模型能有最佳表現,而在這裡他將會跨足Encoder與Decoder兩個架構,因此在訊息上的結合就會比較困難。
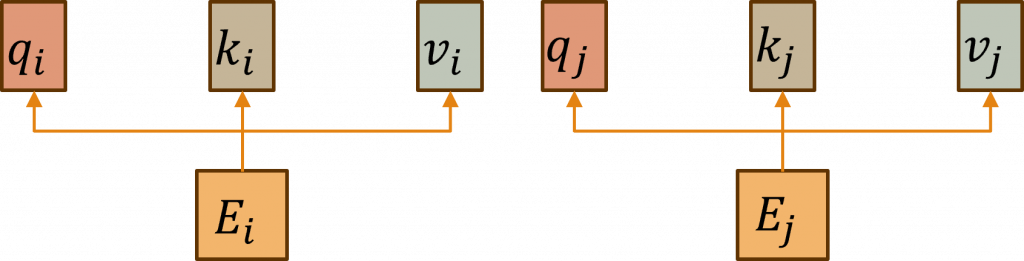
這次所使用的Self-Attention被稱為「Self」,是因為其運算中使用的是文字內部的向量,讓我們來看看圖片中的k、q、v這三個參數,這三個向量是經過Positional Encoding計算過後,再與Wk、Wq、Wv三個權重進行的運算的新結果,而這三個新向量分別代表了該詞彙之後將進行的動作,我們先看到下圖中的簡易的例子。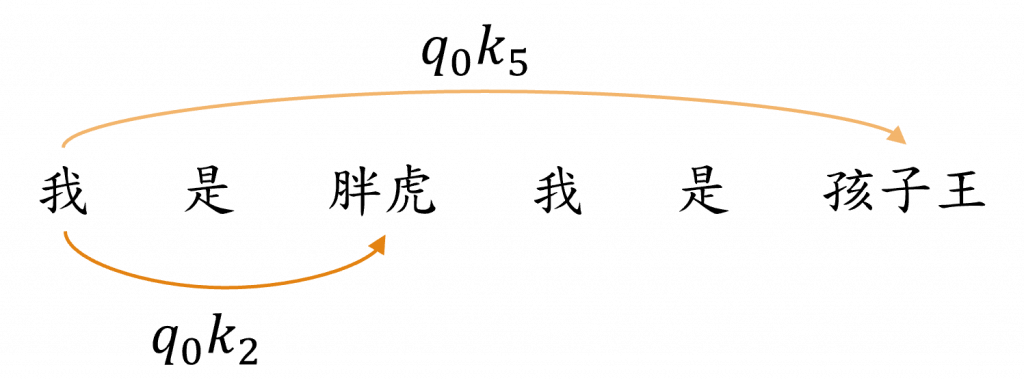
當我們進行尋找代詞的命名實體任務時,必須要留意代詞可能的特性,在LSTM任務中我們通常只會觀察到下一個詞彙的文字資料,因此這樣子可能會讓較遠的資料的注意力權重變得更低,而在Self-Attention中的做法,就是先把每一個詞彙q(我)向量,與其他剩餘詞彙的k(是)...k(胖虎)向量進行比對運算,接下來我們根據q(我)向量去決定哪一個k向量與該向量的關聯性最高,來計算出注意力權重a(t),其詳細作法非常簡單直接將softmax(q·k)就能夠計算出該權重了。
而這樣做的目的是希望讓每個文字能動態地鎖定其應有的焦點,在我們圖片中透過這種方式找出了詞彙「我」與接下來的「胖虎」和「孩子王」的注意力連接強度(透過顏色深淺呈現),這也代表著每個詞彙都會產生出需要的注意力對象,不過該方式還要考慮其他更多的因素,我們先來看到下面的公式:
可以發現在該公式中多出了除上√(𝑑(k))的動作,其原因是在q與k向量進行運算時,數值可能會變得過大,從而導致經過Softmax的輸出梯度可能會過小。
你可能會感到好奇,既然Transformer被設計來取代時間序列模型,那麼它是如何產生類似於時間序列模型的隱狀態h(t)的資料呢?在時間序列模型中我們輸出的資料即為該時序的隱狀態,因此當你察看上述的公式,會發現還多了一個與v相乘的部分,這個向量v的作用,就是呈現出該詞彙本身的特性,因此我們可以認為這個運算結果就是由向量v所算出的狀態。
但在實際的Transformer中,是使用了一種名為Muti-Head Attention(多頭注意力機制)的技術,而這樣的目的是因為在Self-Attention中,每一組q、k向量都只會對同一個詞彙的語意有所注意,然而我們在ELMo的學習過程中,明白到每一個詞彙都應該被分割出多種語意,這樣才能得到更好的結果,因此我們在這裡的作法是在Self-Attention中加入更多組的k、q、v向量,使每一個詞彙能對應到不同的語意環境中。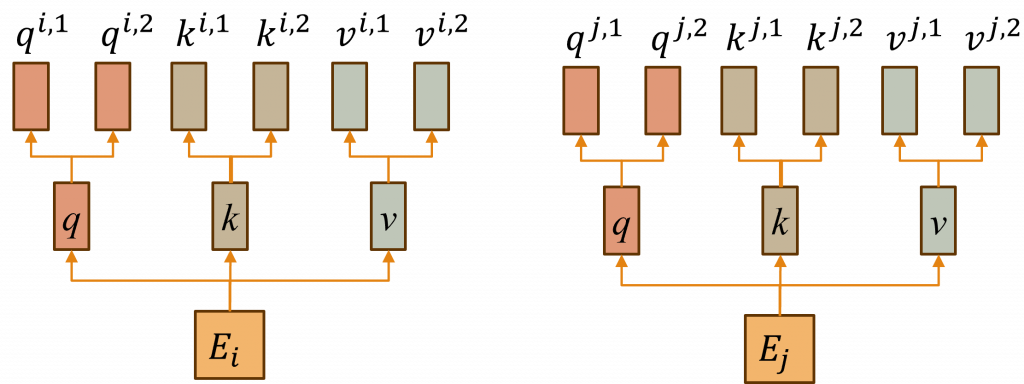
該動作的執行方式與Self-Attention相同,只不過在計算出最後結果時,因為會對同一個時序的資料產生多個輸出b,因此我們需要將其轉換成一個完整的向量,在這裡我們只需要將此輸出b進行維度結合的動作,在與其權重Wb進行矩陣運算,這樣子就完成了Muti-Head Attention的計算方式。
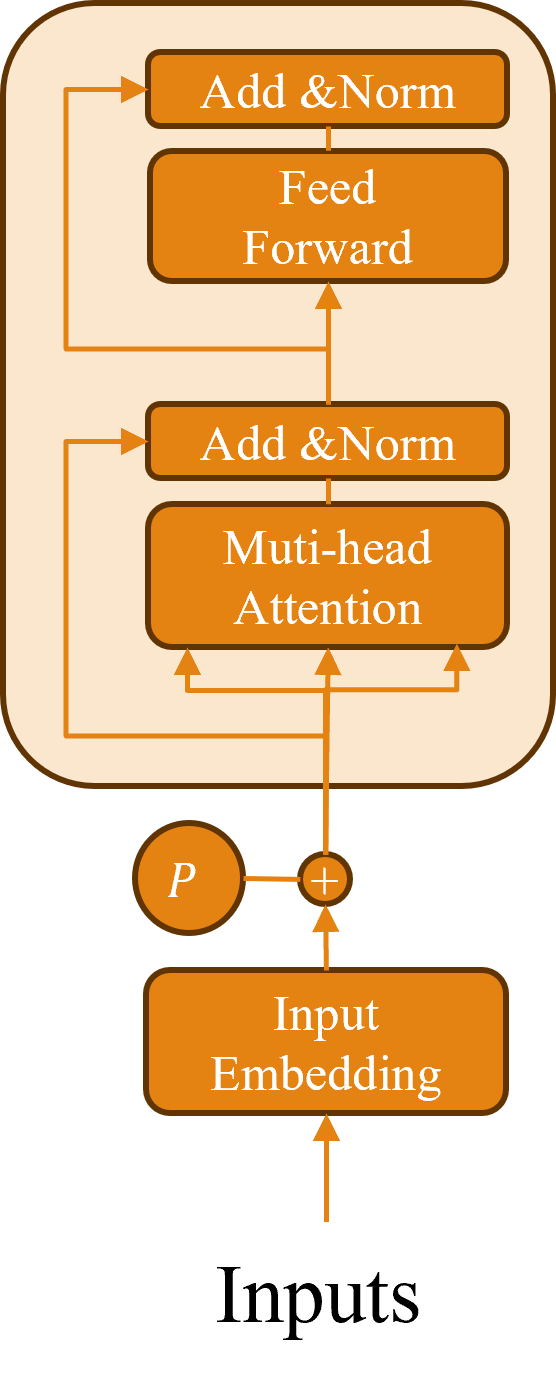
在Transformer的輸出結果中,還會增加了一層Layer Normalization,這個設計的目的是要減少Internal Covariate Shift(內部協變量偏移)的問題。
Internal Covariate Shift的發生,是因為在神經網路裡每一層的輸入分佈都會不斷的變化,這樣會導致訓練過程不穩定,而為了解決這個問題,我們需要一種方式來穩定每層中數值,而在Layer Normalization中就是通過輸入的x、均值E[x]與方差Var[x]來轉換每一層的輸出結果,其計算公式如下:
其中𝜖的用途主要是為了防止出現除以零的情況,因此其數值通常會設定得非常小,至於𝛾則是用來控制縮放輸出的幅度,而𝛽則是代表該層的偏移量,這樣子模型每一層的訊息會比較穩定,使其收斂效果更佳。

在Transformer的Decoder中,多出了一個Masked Multi-head Attention(遮蔽式多頭注意力機制)的層,這層的目的出現是由於Transformer是使用平行運算的,但我們在Decoder中通常是採用Teacher Forcing的訓練方式,這時如果我們將完整的序列傳入,Transformer就會考量到尚未出現的字元,從而導致運算錯誤。
這裡讓我們先回憶一下Teacher Forcing的訓練方式,當我們在進行翻譯任務時,若Decoder的輸出的資料是法文的J'ai un chat <EOS>,而Decoder的輸入資料是<SOS> I have a cat,在這種情況下<SOS>這個序列輸入給Decoder後應該要生成J'ai這個詞彙,而<SOS> I生成un這個詞彙,以此類推直到出現<EOS>。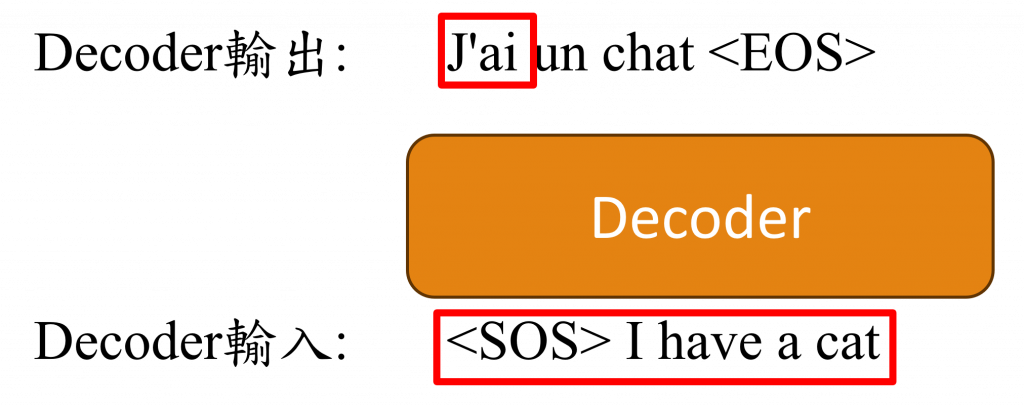
但在Transformer中,當我們輸出J'ai這個詞彙時,它會完整地將<SOS> I have a cat考慮在內,這可能導致在Decoder未完成訓練時就接收了過多的信息,使模型難以收斂,因此對於Decoder的第i個輸出,我們需要對i+1之後的文字位置進行Mask的操作,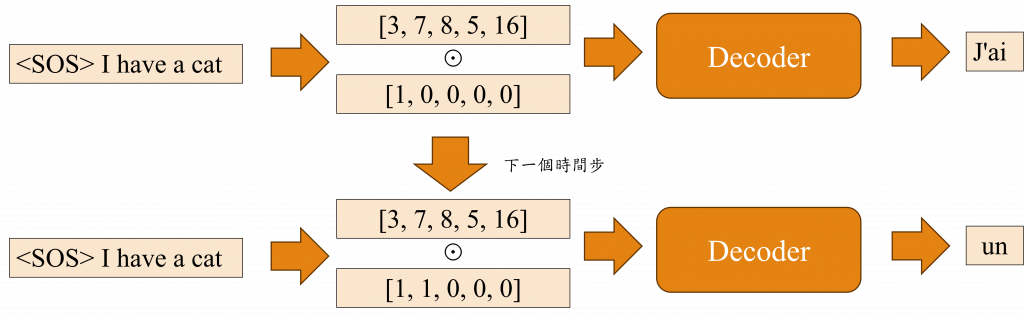
換句話說,當生成'J'ai'這個詞彙時,Decoder的輸入會是<SOS> I have a cat和[1, 0, 0, 0, 0]運算後的結果,這一點就是Masked Multi-head Attention中新增的部分,其餘的部分則與相同。
這次的Transformer的架構與Seq2Seq+Attention非常類似,只是做了一些細微的變動和設計,例如他使用Self-Attention來取代時間序列模型中的複雜運算,並用Positional Encoding來賦予文字時序的概念,而對於ELMo針對詞彙的詞嵌入向量,Transformer則在內部加入了Multi-Head Attention來改進詞嵌入的計算過程,現在你已經用Seq2Seq+Attention的概念來理解Transformer模型了,感覺是不是簡單許多呢?明天我將進一步加深你對這個模型的印象,這次我會Pytorch來教你如何建立一個Transformer模型。
那麼我們明天再見!
內容中的程式碼都能從我的GitHub上取得:
https://github.com/AUSTIN2526/iThome2023-learn-NLP-in-30-days


 iThome鐵人賽
iThome鐵人賽