今天原本預計要使用訓練完模型結合爬蟲,來實際運用訓練好的模型,但發現直接跳到Transformer似乎有點跳太多,前面我們只有使用Keras來做IMDB模型,沒有針對自然語言做說明,這裡來補充說明有關文字處理NLP(自然語言處理)相關概念,稍微把腳步緩一緩,下面讓我們來說明。
自然語言處理(NLP)是人工智慧(AI)領域的一個分支,針對於使計算機能夠理解、處理和生成自然語言文本,NLP的領域非常廣泛,包括文本分類、機器翻譯、文本生成、情感分析等,這裡我們了解NLP的基本概念,後將以英文做訓練模型動作,主要原因為相較中文而言,在英文在分詞(Tokenization)(或稱斷詞)上較為容易,能夠以空白當作分詞位置判斷,下面讓我們繼續。
自然語言處理如前面所述,針對使計算機能從文本的基本處理到高級的語言理解和生成,而NLP的目標包括:
文本分類: 將文本劃分為不同的類別,例如垃圾郵件檢測、情感分析等。
機器翻譯: 將一種語言的文本翻譯成另一種語言,例如Google翻譯。
文本生成: 創建自然語言文本,包括文章、詩歌、對話等。
問答系統: 回答自然語言問題,例如智能助手和聊天機器人。
信息擷取: 從文本中提取有用的信息,例如新聞摘要或實體識別。
情感分析: 分析文本中的情感或情感極性,了解人們對某事物的情感。
在進行任何NLP任務之前,需要對文本數據進行預處理,包括了:
如同我們學新語言般,我們總不會一開始就一整段句子去學,也是從單字開始,而英文分詞較為容易主要是因為每個詞都會有空格分開,而中文卻無法使用空白或逗號,分詞效果就如下面畫線切割般。
停用詞移除(Stopword Removal): 去除常用的停用詞,如“and”、“the”等,這些詞對理解文本內容較為不重要。
詞幹提取(Stemming)和詞形還原(Lemmatization): 將單詞轉換為它們的基本形式,以減少詞彙的變化形式。
PS.
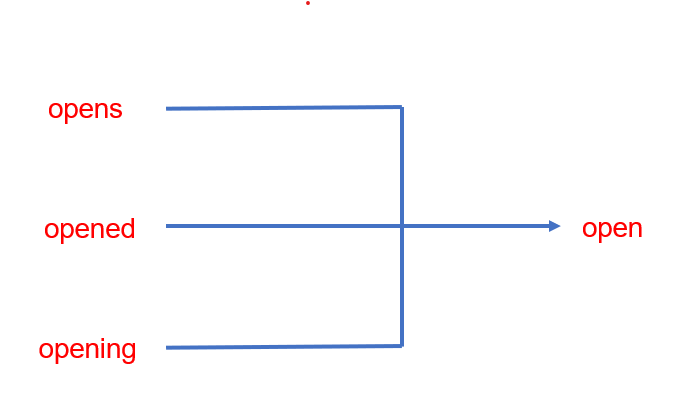
詞幹提取(Stemming)以例子說明如
可以看到這三中變化其最原始詞根就是open,而詞幹提取目的是為了獲得他的詞根。
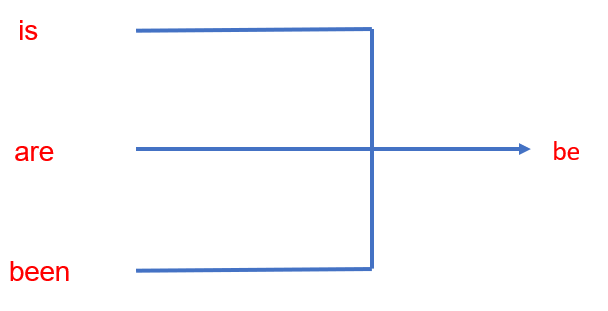
詞形還原(Lemmatization)則如
看似與詞幹提取相似,但有點不同,詞形還原會依照辭典內來做還原,而不是相詞幹提取將他的前後綴去除
詞嵌入是NLP中一個關鍵概念。它將單詞映射到連續向量空間中,使得計算機能夠理解單詞之間的語義相似性。常見的詞嵌入模型包括Word2Vec、GloVe和FastText。
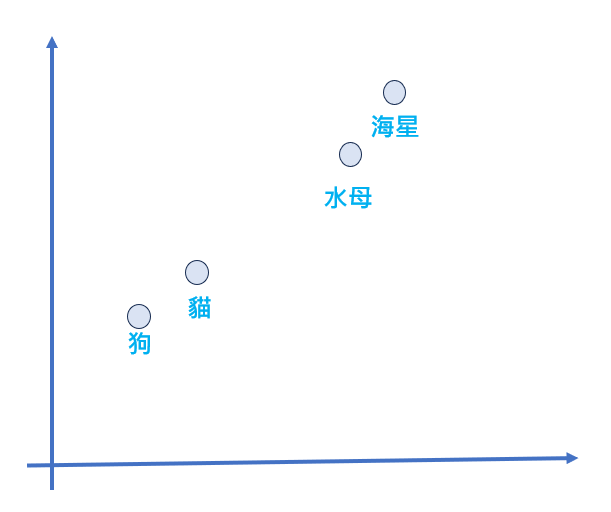
這裡我們假設有一個詞彙表,包含以下幾個單詞:["狗", "貓", "水母", "海星"],我們將這些單詞轉換為詞嵌入向量,
"狗"的詞嵌入向量:[0.1, 0.5]
"貓"的詞嵌入向量:[0.2, 0.6]
"水母"的詞嵌入向量:[0.6, 0.7]
"海星"的詞嵌入向量:[0.7, 0.9]
假設把它們在座標上表現出來概念如下
貓與狗之間語意比較相近(如寵物貓寵物狗),狗與水母就相差較遠。
為了使計算機能夠理解文本,我們需要將文本轉換為數字表示(給計算機一個辭典)。常見的方法包括:
可以簡單看成下圖
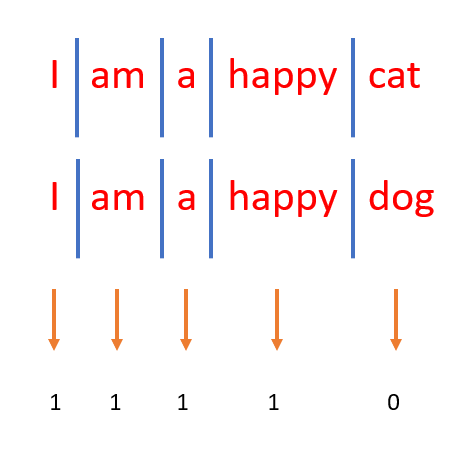
而讀熱編碼則表示方式不同。
如圖,若以第一句做範本,第二句有重複詞則標記,dog前面沒出現過則0。
將文本表示轉換為數字後,我們可以使用機器學習模型來解決各種NLP任務。常見的模型包括:
文本分類模型: 使用分類算法(如支持向量機、決策樹、深度學習模型)進行文本分類,例如情感分析。
序列標記模型: 用於命名實體識別(NER)等任務的模型,例如隱馬爾可夫模型(HMM)和循環神經網絡(RNN)。
詞嵌入模型不僅用於文本理解,還可以應用於其他NLP任務,如文本生成、情感分析、語言翻譯等。通過詞嵌入,計算機能夠理解語言中的語義關係。
以上大致介紹有關NLP的一些基礎知識,這都是需要來了解的,前面簡單用過模型處裡文字,卻沒詳細說明,這裡也算是補了點,而上面提到在文本表示,也就是我們給計算機的辭典有不同的方,如熱編碼優點是簡單直觀,保留了單詞之間的唯一性,但無法捕捉語義相似性,且在詞彙表變大時會變得非常稀疏,且會有維數增多造成維數災難,(簡單形容,如果有一萬個不同單詞那後面會變成[1.1.0..........0.0.1]很長很長,長到你電腦爆炸),而詞袋模型和TF-IDF考慮了詞彙的計數信息,能夠更好地反映文本的特徵,但仍然無法捕捉詞語的語義關係,詞嵌入則將單詞映射到連續向量空間中,有助於理解語義相似性,但需要大量的文本數據來訓練詞嵌入模型,這些方式都有各自優缺,如同各種模型要選出適合我們目標模型,在辭典表示方式等等都是要依照目標去考慮的,以上就是今天內容,大多是補足前面沒有提到的文字處理細節,希望能幫助到你!我們明天見。