深度學習已經成為解決各種複雜問題的重要工具,然而隨著模型變得越來越大,訓練深度學習模型變得非常耗時,為了應對這問題,我們可以利用圖形處理器單元(GPU)的強大計算能力來加速訓練過程。
下面來說明如何在PyTorch中使用GPU做計算
讓我們開始吧,首先是一些基本的背景信息。
GPU是一種特殊的硬體,具有大量的計算核心,特別適用於處理大規模且高度並行的計算工作負載。相比之下,中央處理器(CPU)通常具有較少的計算核心,但對於一般計算任務非常適用。
PyTorch提供了GPU支持,讓可以充分發揮GPU的計算能力來訓練深度學習模型。簡單地說可以將模型和數據移動到GPU上,從而實現更快的訓練速度。接下來,我們將討論如何確保您的GPU驅動程序和CUDA工具包是最新的。
在開始使用GPU進行深度學習訓練之前,確保您的計算機上已安裝了最新版本的GPU驅動程序和CUDA工具包(如果您使用的是NVIDIA GPU)。這些軟件的更新可以改進性能,並確保您可以使用最新的GPU功能。
更新GPU驅動程序:訪問NVIDIA官方網站,下載和安裝最新的GPU驅動程序。確保GPU型號和操作系統選擇正確的驅動程序版本。
安裝CUDA工具包:CUDA是一個並行計算平台,允許您利用GPU的計算能力。安裝與GPU兼容的最新版本的CUDA工具包,以便PyTorch可以充分利用GPU。
要安裝CUDA工具包,可以按照以下步驟進行操作。請注意,這些步驟基於NVIDIA GPU和Linux操作系統,如果使用不同的硬件或操作系統,步驟可能會有所不同。
https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
安裝NVIDIA驅動程序:在設置CUDA之前,請確保您的NVIDIA GPU驅動程序是最新版本。可以從NVIDIA官方網站下載並安裝適用於GPU型號和操作系統的驅動程序。
下載CUDA工具包:前往NVIDIA官方網站的CUDA下載頁面
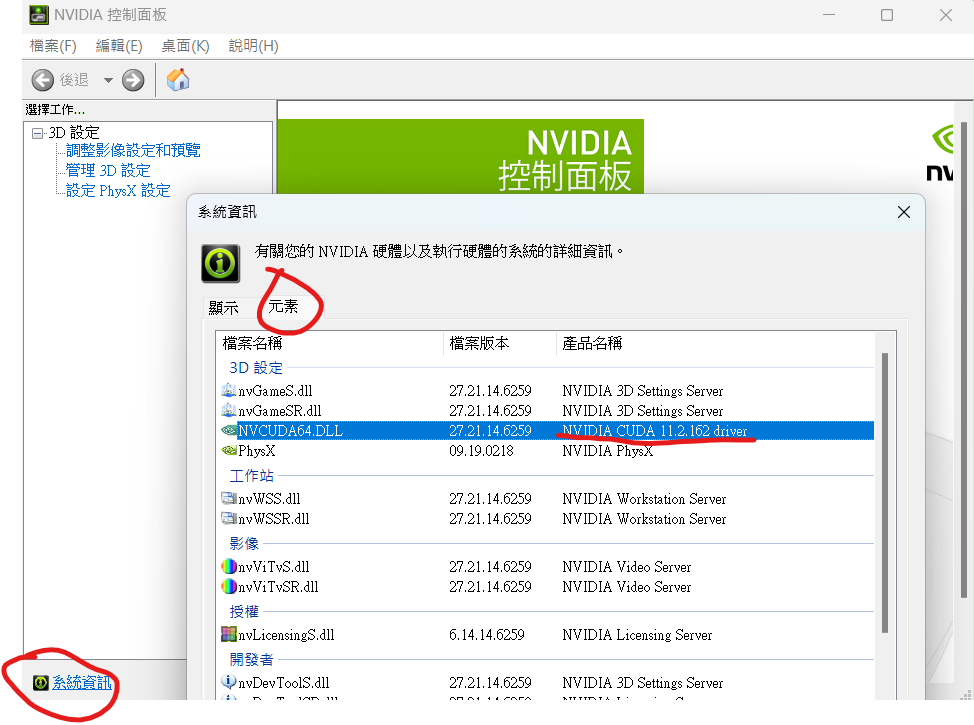
要找對應版本 圖是示範
記得先看自己顯卡支援哪種,可這樣看
檢查CUDA安裝:安裝完成後,可以在CMD中運行以下命令來檢查CUDA是否成功安裝:
nvcc --version
如果看到CUDA版本信息,則表示安裝成功。
一旦確保GPU驅動程序和相關工具的更新,就可以開始在PyTorch中使用GPU了。
在PyTorch中,將模型和數據轉移到GPU上是相對簡單的。以下是一些基本步驟:
首先需要檢查您的計算機是否具有可用的GPU,可以使用以下代碼片段來執行此操作:
import torch
# 檢查是否有可用的GPU
if torch.cuda.is_available():
device = torch.device("cuda") # 使用GPU
else:
device = torch.device("cpu") # 使用CPU
這將根據GPU的可用性選擇適當的設備(GPU或CPU)。
要將PyTorch模型移至GPU,您只需調用to方法:
model.to(device)
這將使模型的所有參數和計算都在GPU上進行。
同樣可以將PyTorch張量(數據)移至GPU,以便在GPU上進行計算。使用以下代碼將張量移至GPU:
data = data.to(device)
現在模型和數據都位於GPU上,可以開始進行GPU訓練。
使用GPU進行深度學習訓練具有明顯的優勢,尤其是對於大型模型和數據集。以下是一些GPU訓練的優勢:
加速訓練速度:GPU可以處理大量計算並且高度並行,因此可以大大加快訓練速度。
支持大型模型:GPU的大容量允許訓練更大的深度學習模型,這些模型在CPU上可能無法訓練。
處理大型數據集:GPU可以高效地處理大型數據集,而無需將其全部加載到內存中。
然而,使用GPU也有一些限制:
GPU內存限制:每個GPU具有有限的內存,對於大型模型或大型數據集,可能需要多個GPU或其他策略。
能源消耗:使用GPU需要額外的電能,這可能會增加運行成本。
編程複雜性:在多GPU或分佈式訓練中,編寫和管理代碼可能變得更加複雜。
# 設置模型為訓練模式
model.train()
for epoch in range(num_epochs):
for batch in dataloader:
# 將數據移至GPU
inputs, labels = batch
inputs, labels = inputs.to(device), labels.to(device)
# 正向傳播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向傳播和優化
optimizer.zero_grad()
loss.backward()
optimizer.step()
在使用GPU進行訓練時,GPU記憶體可能會成為限制因素,尤其是當處理大型模型或數據時。以下是一些處理GPU記憶體限制的方法:
減少批次大小:減少每個批次中的示例數,以減少GPU記憶體的使用。
梯度累積:將梯度累積多個小批次,然後進行一次反向傳播,以減少記憶體使用。
使用混合精度:使用混合精度訓練(half-precision training),這可以減少模型參數和梯度的記憶體使用。
分佈式訓練:將訓練過程分佈到多個GPU上,以增加可用的GPU記憶體。
如果有多個GPU,可以利用它們來加速訓練過程,PyTorch提供了多種方式來實現多GPU訓練,包括DataParallel和nn.DataParallel等模塊,這允許您在多個GPU上同時訓練模型,並自動處理數據的分佈。
對於更大型的模型和更大型的數據集,可以考慮分佈式訓練,這將訓練過程分佈到多台計算機上,每台計算機可以有多個GPU,使用分佈式訓練可以處理非常大型的模型和數據。
後面不會用這裡稍微做個介紹
我們以圖像分類做測試,使用GPU加速圖像分類模型的訓練。
以下
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
# 檢查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 下載和加載CIFAR-10數據集
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
# 定義CNN模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(6 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = x.view(-1, 6 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net().to(device)
# 選擇優化器和損失函數
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 訓練模型
for epoch in range(10): # 訓練10個epoch
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch + 1}, Loss: {running_loss / len(trainloader)}")
print("Finished Training")
可以試試看有沒有變快的感覺,今天先講如何使用GPU做運算,來加速後續我們訓練時的速度,明天見~