在過去的兩天我們學習到了Transformer的理論與實作程式碼,不過我們所使用的Transfomer是完整的Encoder-Decoder架構所以他的模型大小也會叫大,而在這些預訓練模型中通常會為了減少計算的複雜度所以只會使用到其中一個架構,例如進行分類時只需要使用到Encoder架構,而生成時只使用到Decoder架構,這一點的作法也是我們今天要說到的BERT這一個模型所用的方式,今天的學習重點如下:
BERT的原理與架構BPE(Byte Pair Encoder)斷詞技術解講NSP(Next Sentence Prediction)的理解MLM(Mask Language Model)的使用原因BERT(Bidirectional Encoder Representations from Transformers)是對ELMo模型的改良與提升,該模型通過12層各有12個head的Transformer Encoder來建構,而我將其比喻為「站在巨人肩膀上」的原因在於,它實際上是結合了最新研究的成果與技術,例如:Transformer Encoder架構、BPE斷詞技術、Transfer learning的權重轉移方式,還有特殊Token的文字表示(Representations)方法等,這些都是該模型的重要組成部分而BERT就是這樣一步一步地,借助這些新技術和研究成果使其被建而成。
不過該模型真正厲害的地方在於自創的預訓練策略,這種策略讓模型更進一步理解雙向上下文訊息,這個改動使得BERT論文一經發布後,便在GLUE、SQuAD、SWAG等資料集的準確率排行榜上穩坐龍頭,並且該方式對後續自然語言模型產生了大規模影響,現在讓我們一起來探索該模型的訓練方式吧!

一個優質的模型需要有出色的斷詞策略,這點我們在【Day 16】解析詞嵌入預訓練模型的奧秘(下)-fastText中瞭解了這些道理,透過Subword來為詞彙建構的這種表達方式,能進而大幅提升效能。
因此在這裡,BERT採用一種名為BPE(Byte Pair Encoder)的Subword斷詞法,不過該段詞法從文字敘述上來解釋,可能比較難理解,所以在講解理論的過程中,我將結合程式碼來實現,讓你更易於記住和理解這個過程。
首先我們需要統計每個詞彙的出現次數,在此過程中我們使用了vocab變數進行模擬詞彙的數量。同時我們使用</w>來標示每個詞彙的邊界,而在BPE演算中的第一步就是將這些詞彙轉換為字元,再統計這些字元的出現次數。
def get_tokens(vocab):
tokens = collections.defaultdict(int)
for word, freq in vocab.items():
word_tokens = word.split()
for token in word_tokens:
tokens[token] += freq
return tokens
vocab = {'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w e s t </w>': 6, 'w i d e s t </w>': 3}
# -----------------輸出-----------------
{'l': 7, 'o': 7, 'w': 16, '</w>': 16, 'e': 17, 'r': 2, 'n': 6, 's': 9, 't': 9, 'i': 3, 'd': 3}
接下來BPE算法中會持續重組詞彙表中所有相鄰的兩個字元,並計算出這兩個字元重組後在文本中一共出現了幾次。例如,lo字元在low</w>(出現5次)與lower</w>(出現2次),因此它的出現次數總計為7次。
def get_stats(vocab):
pairs = collections.defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i],symbols[i+1]] += freq
return pairs
pairs = get_stats(vocab)
# -----------------輸出-----------------
('l', 'o'): 7, ('o', 'w'): 7, ('w', '</w>'): 5, ('w', 'e'): 8, ('e', 'r'): 2, ('r', '</w>'): 2, ('n', 'e'): 6, ('e', 'w'): 6, ('e', 's'): 9, ('s', 't'): 9, ('t', '</w>'): 9, ('w', 'i'): 3, ('i', 'd'): 3, ('d', 'e'): 3
接下來我們還要尋找出組合次數最高的結果,在此案例中e與s這兩個字元的出現次數是最高的,因此我們將這兩個字元合併成es,然後統計新產生的es字元在文章中的出現次數,接下來我們會使用新結果來取代掉原本的s字元(因為出現次數相同)並更新字元詞彙表,如此循環STEP 1至STEP 3的步驟直到所有條件都達到為止後,我們就能取得斷詞後的SubWord。
def merge_vocab(pair, v_in):
v_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
tokens = get_tokens(vocab)
print(tokens)
# -----------------輸出-----------------
'l': 7, 'o': 7, 'w': 16, '</w>': 16, 'e': 8, 'r': 2, 'n': 6, 'es': 9, 't': 9, 'i': 3, 'd': 3
而設定停止條件的方式非常多種,在這裡我主要介紹兩種方式,第一種就是直接設定迴圈次數,但這樣將需要我們不斷地測試合併的結果,若迴圈次數設定不足,將可能導致字元無法有效的重組;反之若設定的迴圈次數過多,則可能會導致分割結果不夠乾淨。
num_merges = 10
for i in range(num_merges):
pairs = get_stats(vocab)
if not pairs:
break
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
tokens = get_tokens(vocab)
因此第二種方式是我們可以依照該詞彙的出現次數進行設定,當某些詞彙出現一定數量時才會停止,例如在我們的範例裡面,我們知道low這個詞彙共出現了7次,因此我們可以用此作為設立條件讓它自動停止。
cnt = 0
while(tokens.get('low') != 7):
pairs = get_stats(vocab)
if not pairs:
break
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
tokens = get_tokens(vocab)
cnt +=1
print(tokens)
# -----------------輸出-----------------
'low': 7, '</w>': 7, 'e': 8, 'r': 2, 'n': 6, 'w': 9, 'est</w>': 9, 'i': 3, 'd': 3
這時我們可以看到low與字跟est被有效的分割出來,而這一點當文本資料越大時,該演算法的最終結果越好,不過BERT中的表示方式有一些小改動,它會將最後的結果est</w>修改成##est,來作為它的詞彙之一。
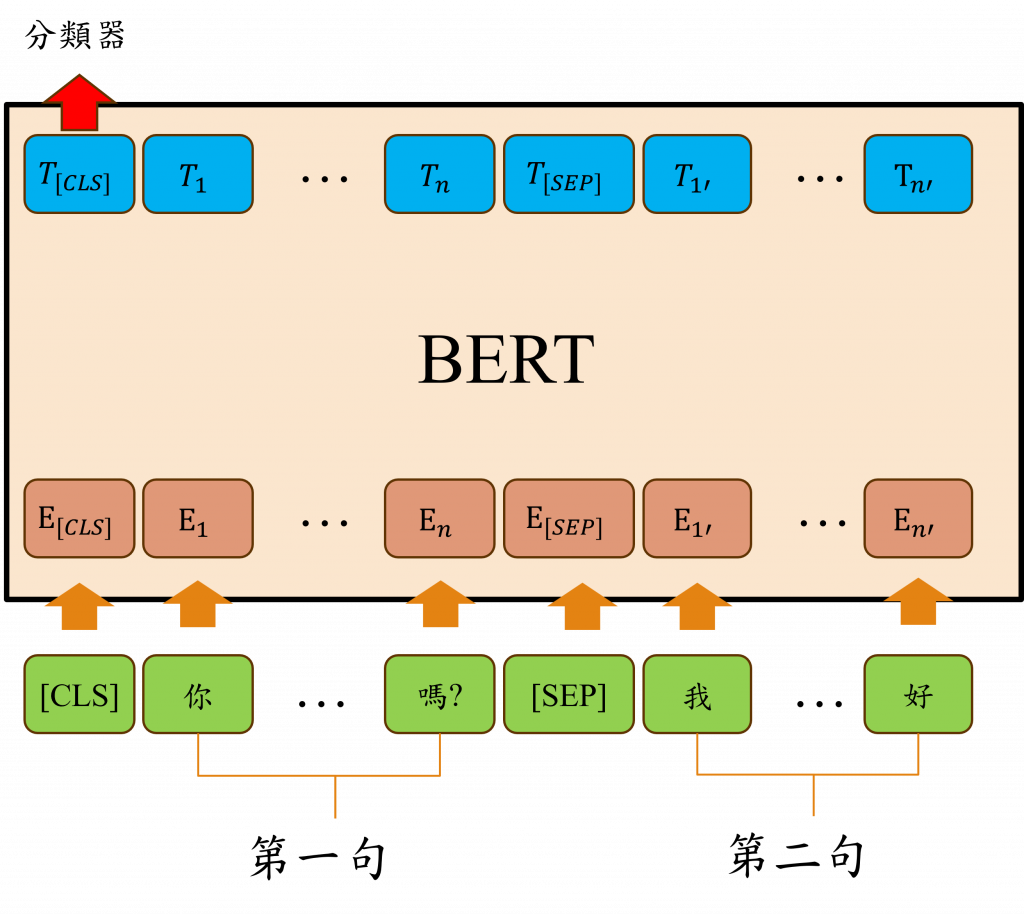
NSP(Next Sentence Prediction)是BERT模型的預訓練任務之一,這項任務的目的是讓模型理解文本中,特別是兩個句子之間的主要邏輯關係,透過該方式我們可以判斷兩個輸入句子是否是連貫的,也就是「下一句」是否是「前一句」的延續,而在BERT中採用了Segment Embedding的方式來進行編碼,將屬於第一個句子或段落的部分標為0,而屬於第二個句子或段落的部分則標記為1,並且透過神經網路來訓練已理解這些文本之間的關係。
小提示:
在BERT中有三層詞嵌入層,第一層對應到Transformer的Token Embedding這邊兩者是相同的,不過第二層的Position Embedding與Transformer中的Positional Encoder有些不同,雖然兩者看起來相似,但其實有著重要的不同之處。主要的區別在於BERT的位置編碼是可以進行訓練的,然而在Transformer中的位置編碼卻是固定的(Embedding與sin()、cos(),的轉換差距)。至於第三層的Segment Embedding,它其實就是我們上述所提到的NSP任務中的訊息資訊。

Masked Language Model (MLM) 的主要特點是其能夠預測句子中遺失部分的詞語或標記,在訓練過程中,BERT會隨機選取輸入文本中的15%詞彙替換成特殊的[MASK] 標記,並要求模型去預測被替換掉的詞彙,這樣的設計能讓模型能夠學習詞彙間的相依性,同時強化對未見過單詞的泛化能力。
不過在微調階段中並沒有[MASK]這樣的標記,因此BERT並不是完全使用[MASK],而是將其替換為其他的詞彙,使其能夠更貼近微調時的效果。而這樣的預訓練方式在後繼的預訓練模型中幾乎已成為必使用的關鍵技術,甚至有很多研究著重在改進這種方法。
在BERT的特殊標籤中,主要有兩個我們可能不太熟悉的標籤,分別是[CLS]和[SEP]。
| 名稱 | 說明 |
|---|---|
| [CLS] | 用於捕獲整個序列的語義信息 |
| [SEP] | 區隔句子的前後文 |
| [MASK] | 遮蔽文字字元,僅出現在預訓練階段 |
| [UNK] | 表示未知字元 |
| [PAD] | 表示填充字元 |
[CLS]標籤的主要用途是提供一種方式,讓模型能夠利用這個單一標籤來理解整個句子的訊息,例如:我們輸入[CLS]今天天氣好嗎?給模型,BERT的設計者希望模型能夠僅透過[CLS]這個標籤就能理解今天天氣好嗎?這句話的意義,這樣設計的原因在於BERT的輸出結構會在這個[CLS]標籤的序列位子上添加一個簡單的線性分類器,以此作為模型的輸出,而不是將整個語意訊息融合後再輸出。 |
而[SEP]標籤則類似於<EOS>的用途,它可以幫助模型識別出第一個句子的結尾,並擔任第一句和第二句之間的分隔標記,並通過神經網路訓練的方式來得到文本之間的前後訊息與關聯性。
以上就是強大的預訓練模型BERT所運用的關鍵技巧,如你所見這一理論與我們先前所學的模型有密切的聯繫,這也正是我想要傳達的核心訊息:在學習自然語言處理的過程中,理解這些理論的重要性不容小覷,而BERT模型的成效,證明了我們先前所學的技術並非在自然語言處理領域中是種短暫性的技術,反而是其基石之一,因此在學習自然語言處理時,溫故知新是至關重要的!
至此你應該對自然語言處理的技術用途有更深的理解,而先前我在整個過程中不斷使用程式碼的目的,是希望你能了解這些技術在實踐過程中可能遇到的問題,這些問題在專業論文或理論中並不會提及,透過這種方式你對相關模型的理解將更為深入,不過再次提醒文章中的程式碼只包含重要片段,因此你需要前往我的GitHub查看完整的程式碼,而明天我還是會以這種方式進行學習,所以明天將會是程式碼實作環節,而這次我會教你如何實現使用BERT進行QA問答的任務。
那麼我們明天再見!
內容中的程式碼都能從我的GitHub上取得:
https://github.com/AUSTIN2526/iThome2023-learn-NLP-in-30-days


 iThome鐵人賽
iThome鐵人賽