早安安!
基於統計模型的演算法主要依賴幾個子頻內預設的能量分布模型,對語音、雜訊進行區分,這在訊號雜訊低、非平穩雜訊的環境中,就容易出現誤檢率較高的情況,如使用WebRTC的VAD演算法會在雜訊處出現大量偽陽性的結果。
隨著深度學習的蓬勃發展,基於神經網絡的VAD演算法受到了廣泛的應用(Sainath,2016;Tong,2016;Kim,2018)。由於神經網絡是從大量訓練資料中學習語音視譜和雜訊頻譜的規律,來加以區分,因此訓練後的模型能夠準確的區分語音及非語音的頻譜,從而提高VAD演算法的抗雜訊、抗干擾的性能。很多地方都已經搭載了基於神經網絡的VAD演算法,用來進行第一級的啟動檢測。
對於神經網絡,VAD可以被理解為二分類問題,就是對每一幀的語音輸入進行「0」或「1」的結果判別,由於VAD對功耗和即時性有比較高的要求,因此使用的模型都會比較簡單一點,如下圖: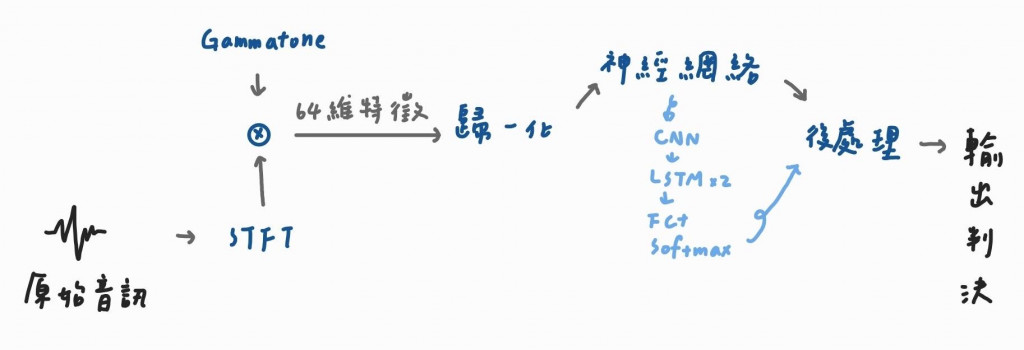
我們先看一下這張圖,該演算法的具體步驟,首先透過一個滑動窗將輸入的時域波形分幀,並進行STFT得到訊號的頻譜。滑動窗的設定通常與常用語音辨識模型的設定相同(寬度為25ms,幀移為10ms)。然後使用一個包含64個通道的Gammatone濾波器組(Segbroeck,2013)對每一幀訊號頻譜進行頻域濾波,並得到一組64維的特徵,Gammatone濾波器組也可換成Mel等其他的頻域特徵提取方法,這些的共同點是根據人耳特性有不同的頻域解析度,低頻處的子頻多、子頻寬窄、顆粒度細,高頻處則反之。
參考書籍:Hey Siri及Ok Google原理:AI語音辨識專案真應用開發
參考網站:今日無
學習對象:ChatGPT

