前一篇介紹如何用 LDA 的 R 程式碼,製作主題模型,這篇文章則要展示如何利用變化版的 STM。
想像一下,LDA 就像是一個喜歡「貼標籤」的人,就像台灣社會一樣(?)給他一堆文章,他會很高興地告訴你:「嗨,我發現這些文章主要在談論政治、科技、和健康!」他很擅長於這一點,但如果你問他「這些政治文章是偏左還是偏右?」,他就會抓狂了,因為他只懂得把文章分成不同的主題。
那麼,如果 LDA 是那個喜歡標籤東西的人,那STM 就像是他的更聰明的表兄弟。不僅能告訴你文章的主題,還能加入更多的層次。他會說:「這些政治文章主要是偏右的,而且大部分都是在選舉期間發表的。」或者「這些健康相關的文章多數是關於營養,而且多是由專業營養師寫的。」
簡單來說,如果你只想知道你的文章集是在談論哪些主題,LDA 就足夠好了。但如果你想要更多,像是怎樣的人寫了這些文章,或者這些文章在什麼情境下被寫出來的,那你可能會更喜歡 STM。他就像是一個帶有超能力的LDA,能讓你更深入地了解你的數據。
技術上來說,LDA 是一個相對簡單的模型,它的主要目標是從一堆文件中找出主題。在 LDA 裡面,每一篇文章都被看作是由多個主題混合而成的,而每個主題則是由多個單詞組成。LDA 並不考慮文章之間或者單詞之間的其他相關屬性或結構。
至於 STM,它在某種程度上是 LDA 的一個擴展。STM 不僅僅是找出文件中的主題,它還試圖理解這些主題是如何與文件的其他屬性(比如作者、出版時間等)相關聯的。換句話說,STM 考慮了「結構」— 它試圖了解主題和其他變量之間是如何相互影響的。
這是主要的技術差異。STM 通常需要更多的計算資源和更複雜的算法來運行,因為它試圖解決一個更複雜的問題。我們直接來看一下 STM 的官網簡介。介紹中,有這樣一段程式碼:
poliblogPrevFit <- stm(documents = out$documents, vocab = out$vocab, K = 20, prevalence = ~rating + s(day), max.em.its = 75, data = out$meta, init.type = "Spectral")
其中有一段 prealence = ~rating + s(day),就是上面說的,將外部變量納入考慮的意思。
另外來看視覺化的時候,它能夠發揮這樣的效果:
plot(prep, covariate = "rating", topics = c(6, 13, 18), model = poliblogPrevFit, method = "difference", cov.value1 = "Liberal", cov.value2 = "Conservative", xlab = "More Conservative ... More Liberal", main = "Effect of Liberal vs. Conservative", xlim = c(-0.1, 0.1), labeltype = "custom", custom.labels = c("Obama/McCain", "Sarah Palin", "Bush Presidency"))
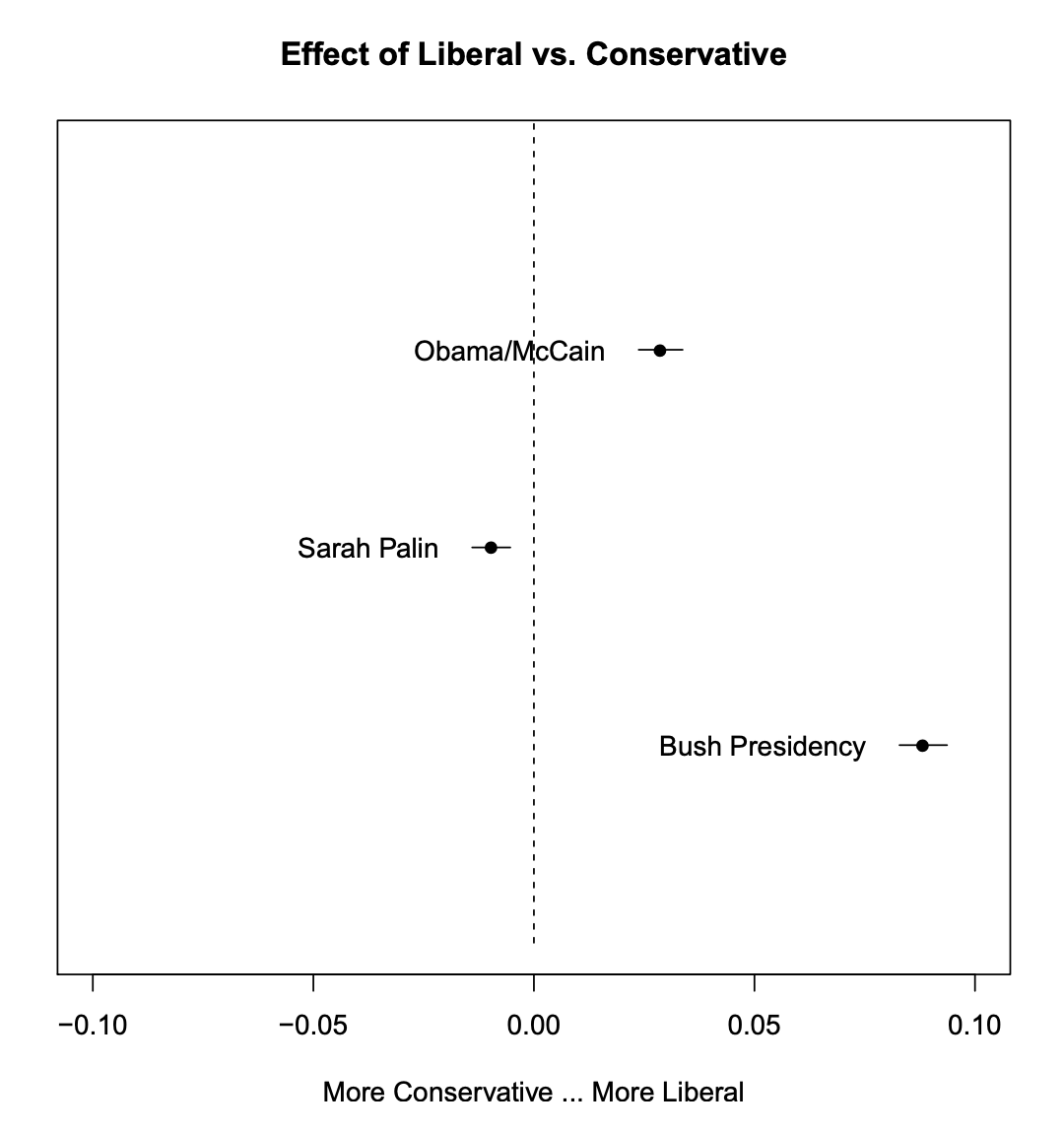
其中,圖裡面有呈現出偏向自由派,還是偏向保守派,程式碼中有一個covariate,就是代表上述的外部變量。
plot(poliblogPrevFit, type = "perspectives", topics = c(16, 18))
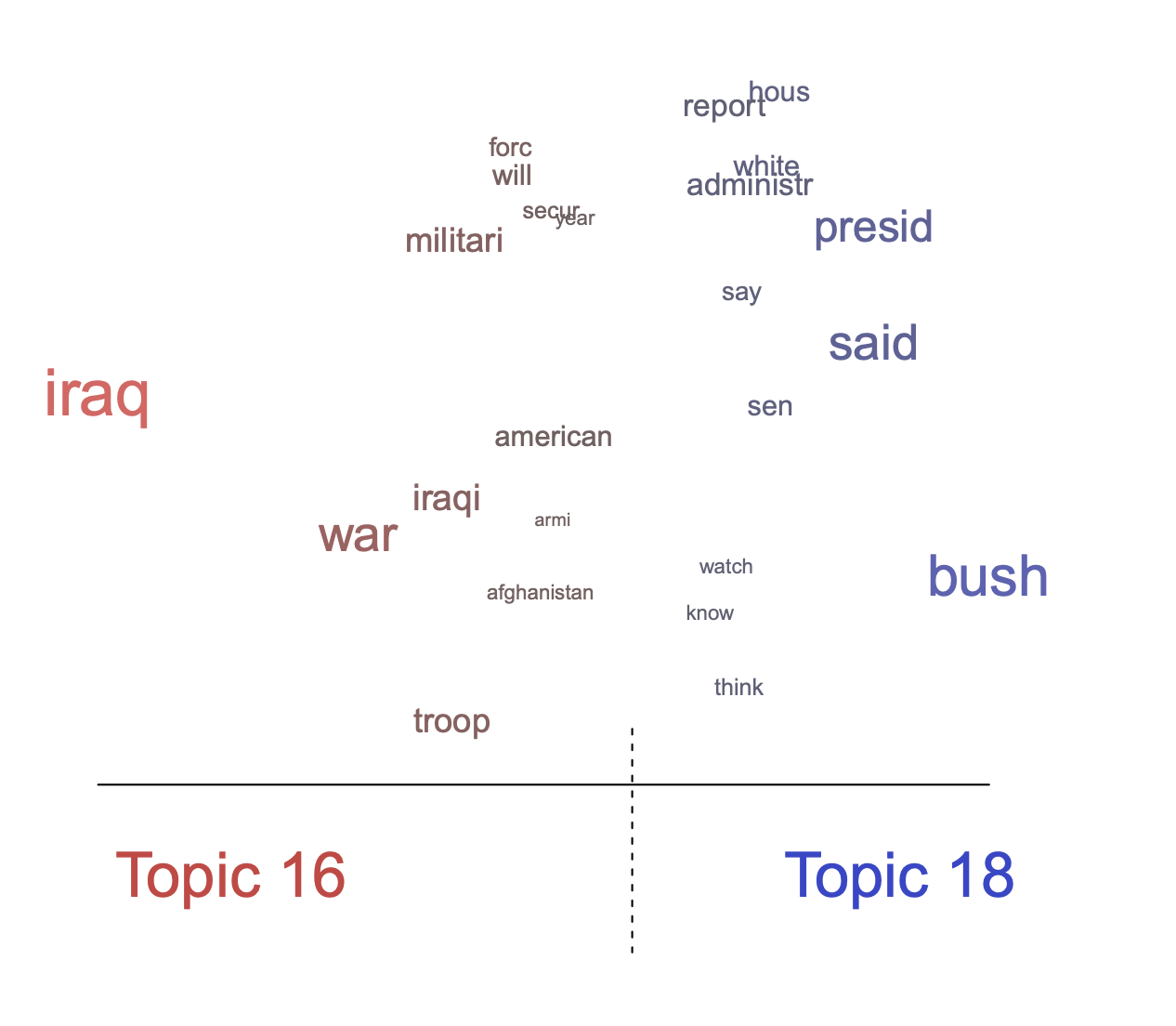
上面這張圖,則方便我們比較兩個不同主題之間的差異。
一開始先載入套件。
library(tidyverse)
library(tidytext)
library(topicmodels)
df_article <- read_csv("data/df_article.csv")
df_article_top <- df_article %>% filter(n > 20)
### 轉換成前面教過的 DTM
dtm <- df_outlet_clean_seg_clean %>%
inner_join(df_outlet_clean_seg_top) %>%
count(id, text_segment) %>%
cast_dtm(id, text_segment, n)
### 利用 tidy 函數
dtm_clean <- dtm %>% tidy() %>% filter(str_length(term) > 1) %>%
cast_dtm(document, term, count)
dtm_remove <- dtm_clean %>% tm::removeSparseTerms(0.999)
dfm_stm <- convert(dtm_remove, to = "stm")
stm <- stm(dfm_stm$documents, dfm_stm$vocab,
K = 10, max.em.its = 140, init.type = "Spectral", seed = 1, prevalence = ~ source, data = dfm_stm[["meta"]])
test_labels_gamma <- labelTopics(stm, n = 20)
gamma_terms <- data.frame(topic= paste0("topic ", 1:ncol(stm[["theta"]]) ),
gamma=colMeans(stm[["theta"]]),
terms=NA)
for (i in 1:ncol(stm[["theta"]])) {
gamma_terms$terms[i] <- paste(test_labels_gamma[["prob"]][i,], collapse = " ")
}
gamma_terms$topic <- factor(gamma_terms$topic, levels = gamma_terms$topic[order(gamma_terms$gamma, decreasing = F)])
dfm_stm$meta$source_main <- as.factor(dfm_stm$meta$source_main)
findThoughts(stm, texts = dfm_stm$meta$title, topics = 25, n = 20)$docs[[1]]
findThoughts(stm, texts = dfm_stm$meta$title, n = 15, topics = 25)
這就是完整的一個主題分類結果囉!

