在介紹完所有的 functions 後,今天就用我之前參加 台灣棒壘球科學會主辦的 2023 台灣棒球數據分析競賽的作品當例子,來看看要如何使用 pybaseball 做數據分析。
我參賽的作品的主題是:
Cody Bellinger回春的原因,並分析這樣的好表現是否有辦法維持
主要目的是分析今年球季從洛杉磯道奇轉戰到芝加哥小熊的 Cody Bellinger,成績跟前兩季低潮相比又回穩的原因,我這次想分析的主要有兩點:
要完成第一項,我們可以使用 Statcast 的 statcast_batter function 來取得 Bellinger 今年的 Statcast 數據。
from pybaseball import statcast_batter
# 獲得 2022 賽季 Bellinger Statcast 數據
bellinger_2022 = statcast_batter("2022-03-31", "2022-10-31", 641355)
# 獲得 2023 賽季 Bellinger Statcast 數據
bellinger_2023 = statcast_batter("2023-03-31", "2023-10-31", 641355)
取得數據後,因為 Statcast 是逐球數據,而如果我們想要整個對戰結果,就要只留下留有結果的那顆球資料,這樣才能算出他對各球隊的打擊成績。Statcast 有 events 這個欄位可以來當作篩選條件,如果他是空值代表他那個打席還尚未結束,除了 events 之外,我們還會需要 Statcast 提供的 woba_value、babip_value 與 iso_value 來計算打擊成績,他們一樣是要有 result 才會有數值,他們代表那個打擊所造成的數值增減。最後會需要篩選出該打席的主客隊,因為回傳資料不是直接跟我們說打者面對的球隊是誰,所以會需要主客隊名稱來篩選資料。
# 收集打席結果與打擊數據和主客隊並移除 events 是空的資料
# 需要使用 dropna() 來移除還有空的 events 資料
bellinger_stats_22_batting = bellinger_2022[['pitcher', 'events', 'woba_value', 'babip_value', 'iso_value', 'home_team', 'away_team']].dropna()
bellinger_stats_23_batting = bellinger_2023[['pitcher', 'events', 'woba_value', 'babip_value', 'iso_value', 'home_team', 'away_team']].dropna()
處理完後,我們需要自行判斷對手球隊是誰,就會需要使用 Bellinger 2022 待的道奇隊代碼 LAD 與 2023 待的小熊隊代碼 CHC 來判斷出對手球隊,這邊我寫了一個 function 去判斷並使用 Pandas 的 apply function 來處理整個 DataFrame 的資料並獲得新的欄位 opponent_team。
# 道奇隊的對手球隊
def get_opponent_lad(row):
if row['home_team'] == 'LAD':
return row['away_team']
else:
return row['home_team']
# 小熊隊的對手球隊
def get_opponent_chc(row):
if row['home_team'] == 'CHC':
return row['away_team']
else:
return row['home_team']
bellinger_stats_22_batting['opponent_team'] = bellinger_stats_22_batting.apply(get_opponent_lad, axis=1)
bellinger_stats_23_batting['opponent_team'] = bellinger_stats_23_batting.apply(get_opponent_chc, axis=1)
整理完對手球隊,再來使用 Pandas 的 groupby、agg、rename 來獲得打擊成績與頻率後,使用 merge 來顯示這兩年的數據。沒有重複的球隊會被排除。
matchup_2022 = bellinger_stats_22_batting[['woba_value', 'babip_value', 'iso_value', 'opponent_team']] \
.groupby('opponent_team') \
.agg({'woba_value': 'mean', 'babip_value': 'mean', 'iso_value': 'mean', 'opponent_team': 'size'}) \
.rename(columns={'woba_value':'woba', 'babip_value': 'babip', 'iso_value': 'iso', 'opponent_team':'count'})
matchup_2023 = bellinger_stats_23_batting[['woba_value', 'babip_value', 'iso_value', 'opponent_team']] \
.groupby('opponent_team') \
.agg({'woba_value': 'mean', 'babip_value': 'mean', 'iso_value': 'mean', 'opponent_team': 'size'}) \
.rename(columns={'woba_value':'woba', 'babip_value': 'babip', 'iso_value': 'iso', 'opponent_team':'count'})
# 顯示 2022 與 2023 的各球隊
display(matchup_2022.merge(matchup_2023, on='opponent_team'))
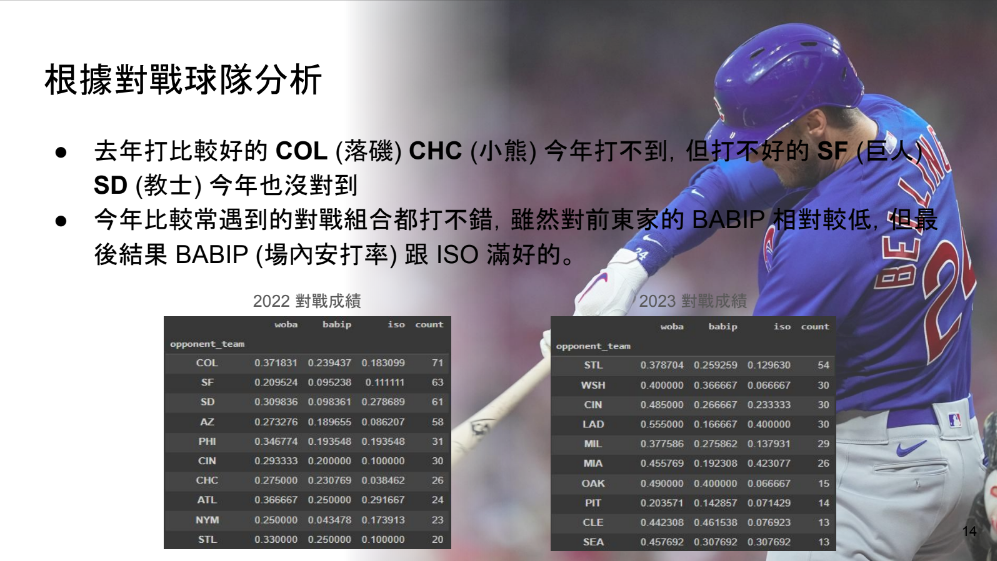
最後比賽那時候的結果,我自己的結論是看不岀甚麼太大的差異,所以不是主因:

後來我在這次鐵人賽發現 Baseball Reference 的 get_splits 可以抓到打者對戰各隊的分項數據,其實使用這個可以更輕鬆的取得各球隊的對戰數據,大家之後也可以試試:
from pybaseball import get_splits
# 用 BR get_splits 獲得各年分項數據
bellinger_22_splits = get_splits("bellico01", 2022)
bellinger_23_splits = get_splits("bellico01", 2023)
# 從分項數據獲得對戰紀錄
matchup_22 = bellinger_22_splits.loc[['Opponent']]
matchup_23 = bellinger_23_splits.loc[['Opponent']]
另一個思考方向是換隊後遇到的投手不同,想要知道這個結果就要先來把對戰過的投手來分類。要怎麼分類我這裡是用到一個機械學習的技巧,K-means Clustering,這邊文章重點是 pybaseball 所以我多做說明,詳情可以看我的簡報裡的介紹。簡單的來說是我用各投手的變化球使用比率,去算各投手的相似度後把他們分成各群。
那麼要知道各投手的球種使用比例,就又只能參考 Statcast 裡的資料了。這裡會需要先使用 Pandas 的 unique 知道總共對戰哪些投手的球員 ID,之後在一個一個使用 statcast_pitcher 來知道它們的投球比例。為了篩選掉這季只上來一下下的大聯盟投手所以我設了一個至少投 100 球以上的條件。
import pandas as pd
pitchers_faced_22 = pd.unique(bellinger_2022["pitcher"])
pitchers_faced_23 = pd.unique(bellinger_2022["pitcher"])
之後在一個一個使用 statcast_pitcher 來知道它們的投球比例。為了篩選掉這季只上來一下下的大聯盟投手所以我設了一個至少投 100 球以上的條件。不過每個投手都要從 Statcast 那邊重新獲得一次資料,所以會需要大概 10 - 20 分鐘的處理時間,我後來就用 to_csv 存成 csv 檔後直接使用。
df = pd.DataFrame()
for pitcher in pitchers_faced_22:
current = statcast_pitcher("2022-03-31", "2022-10-31", pitcher)
# 投球數不超過就不處理儲存
if len(current) > 100:
# 使用 pitch_type 的 value_counts 獲得各球種球數
pitch_type_occ = current['pitch_type'].value_counts(dropna=True, normalize=True)
# 獲得百分比
percentage = pd.DataFrame({"%":pitch_type_occ*100})
pitch_type_df = pd.DataFrame(columns=percentage.index, data=np.array([percentage['%'].to_list()]))
pitch_type_df.insert(0, 'player_id', [current['pitcher'][0]])
pitch_type_df.insert(1, 'player_name', [current['player_name'][0]])
df = pd.concat([df, pitch_type_df])
df = df.replace(np.nan, 0)
處理完資料後我們就交給機械學習去處理,接下來會依據 2022 年的數據來分成五種投手,再把 2023 年的球種分布資料丟進我們建好的 model 去得到 2023 年的這五種類投手分布,最後去比較這兩年各種類投手對戰 Bellinger 的打擊成績。
最後結果也是關係不大,雖然很可惜兩個猜想都沒有結果,但是數據分析有時候就是這樣,要去驗證是否有用:

以上是我這次參加棒球數據競賽使用 pybaseball 的部分,我認為在獲得資料後並使用在機械學習上,pybaseball 十分方便,也可以使用他們去組合出一些客製化的數據,像是我這次整裡的投手使用球種,雖然 Baseball Savant 有類似的 頁面 可以下載 csv 檔,但如果想知道這些投手對決 Bellinger 都投甚麼球種就只能使用 pybaseball 去整理了。
今天以我的參賽作品做為 pybaseball 的實際操作例子,獻醜了,感謝大家耐心地看完。這次比賽有很多好作品,也有很多我意想不到的點子,很推薦大家去看看各個簡報,官方也有提供在 Google Drive 上面給大家觀賞。下次有機會我也一定會再參加,也期待看到更多有趣的作品。
題外話,這次 Bellinger 的主題有其他兩組也有做相關的分析,推薦大家去看看,有一位甚至得到了第二名,真的很厲害!
本日程式碼:
https://colab.research.google.com/drive/1Z5iPAmEdb29NDm38PBKEyG0lHNErHe4v?usp=sharing

