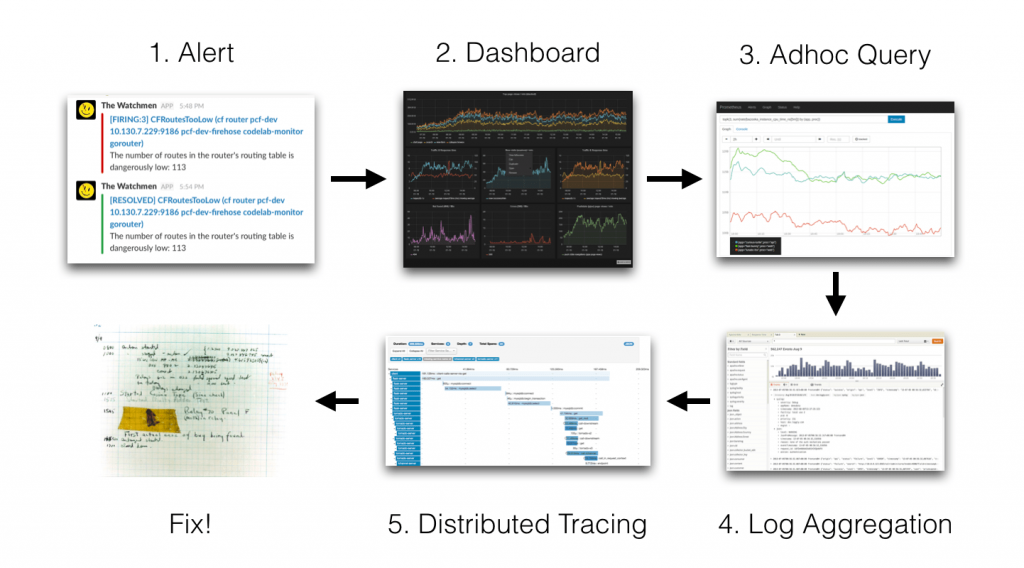
在 2018 年的 DevopsdaysIndia 活動中,Goutham Veeramachaneni 在其講題「Loki, Prometheus but for logs」裡分享了他解決問題的流程圖:
圖片來源:Loki: Prometheus-inspired, open source logging for cloud natives
第一步是透過 Alert 發現問題,接著透過二、三、四、五步利用各種 Observability Signals 排查與定位問題,最後第六步修復問題。通常最不可控的就是中間排查問題的階段,除了資訊可能不足外,還牽涉到多個不同的工具,而這兩個潛在問題,其實就是本系列文章開頭所提到的 Observability 的兩個目標,提供更多資訊以及解決 Data Silo。經過前面一連串的介紹,我們已經了解了如何收集更多的 Metrics、Logs、Traces,接下來就讓我們來看看如何在解決 Data Silo 的同時,讓這三個 Signal 互相關聯搭配產生綜效吧!
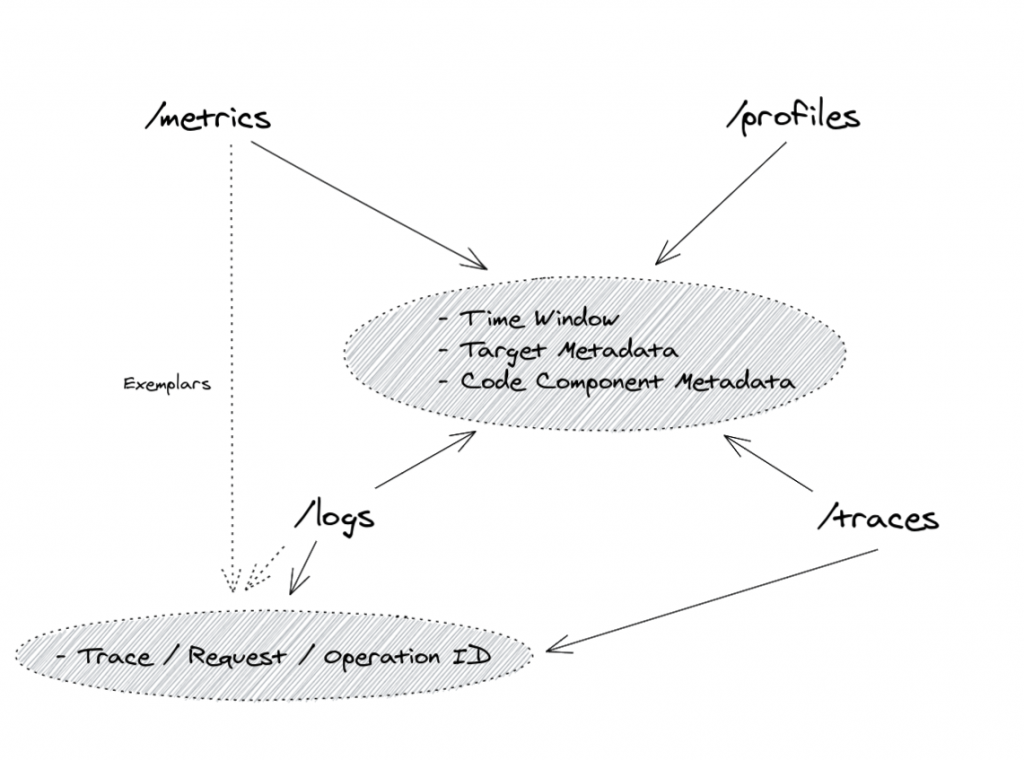
在 CNCF 的 Observability Whitepaper 中描述了如何讓 Observability Signals 交互搭配,主要是透過 Trace ID 和時間讓 Signals 之間建立關聯。
然而,Whitepaper 僅是描述其概念,要實際達到這樣的效果,則需要配合使用特定的工具。在 Grafana 發表的一篇介紹 Exemplar 的文章中,除了解釋 Exemplar 外,也展示了一張圖,簡要說明如何 Grafana 在讓 Metrics、Logs 和 Traces 三者互相搭配。
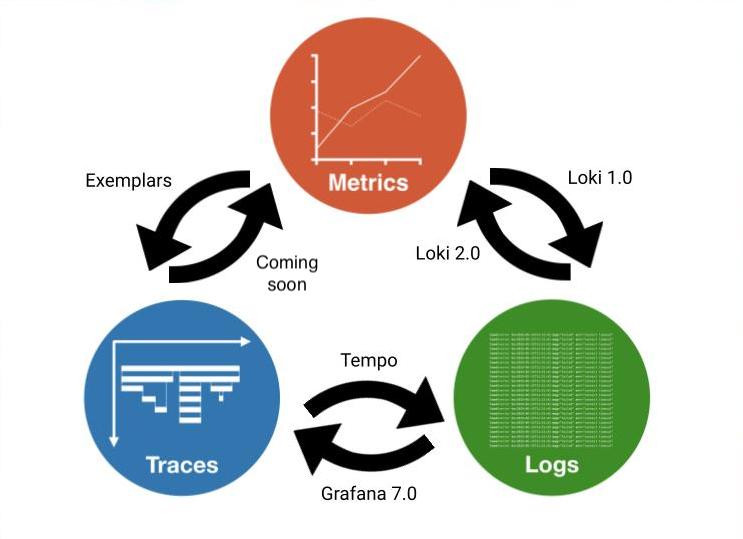
圖片來源:Grafana
接下來,將介紹如何在 Grafana 中設定這三者的互相協作。由於會用到多張圖片,可以直接搜尋以下標題快速跳到感興趣的章節。
Metrics 和 Logs 的關聯是時間。在 Grafana 的 Explore 功能中,可以同時開啟 Metrics 和 Logs,再透過時間同步的功能,鎖定左右兩側 Panel 的時間,從而查看相同時間區段的 Metrics 與 Logs。此外,透過 Metrics 圖表的時間框選功能,也可以快速鎖定查詢的時間範圍。
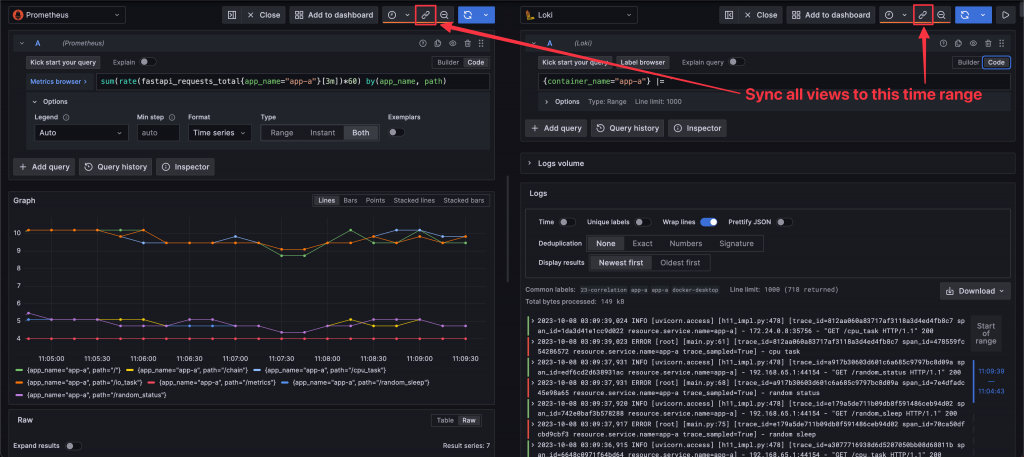
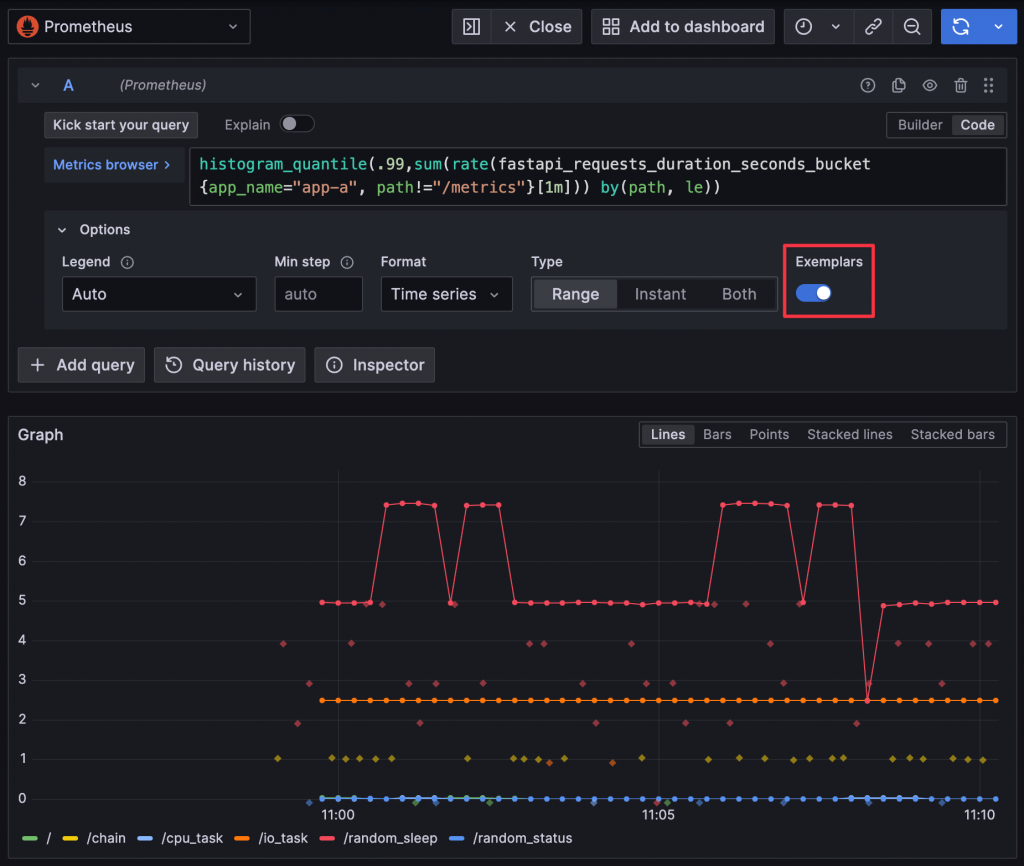
Exemplar 是 OpenMetrics 提出的一個新資料類型。它在 Metrics 中以註記的形式紀錄某筆資料的 Metrics 值和 Trace ID,從而實現 Metrics 和 Traces 的關聯。目前,Prometheus 和 Grafana 都已支援 Exemplar 功能。啟用 Exemplar 之後,在 Metrics 圖表中點選代表 Exemplar 的點,就可以查看該 Exemplar 的 Trace ID。再透過 Grafana 的 Explore 功能,便可以查詢到相關的 Trace 資料。
若要使用 Exemplar 功能,請確保完成以下設定:
Application 搭配的 Prometheus Client 需生成 OpenMetrics 格式的 Metrics,並支援 Exemplar。
在 Python 中,使用 prometheus_client.openmetrics.exposition 的 CONTENT_TYPE_LATEST、generate_latest 產生 Metrics,將 Metrics 改為 OpenMetrics 格式,並將 Trace ID 加入 Histogram 或 Counter Metrics 中
# 揭露 openmetrics 格式的 Metrics
from prometheus_client import REGISTRY
from prometheus_client.openmetrics.exposition import CONTENT_TYPE_LATEST, generate_latest
def metrics(request: Request) -> Response:
return Response(generate_latest(REGISTRY), headers={"Content-Type": CONTENT_TYPE_LATEST})
# Histogram 增加 Exemplar
from opentelemetry import trace
from prometheus_client import Histogram
REQUESTS_PROCESSING_TIME = Histogram(
"fastapi_requests_duration_seconds",
"Histogram of requests processing time by path (in seconds)",
["method", "path", "app_name"],
)
# retrieve trace id for exemplar
span = trace.get_current_span()
trace_id = trace.format_trace_id(
span.get_span_context().trace_id)
REQUESTS_PROCESSING_TIME.labels(method=method, path=path, app_name=self.app_name).observe(
after_time - before_time, exemplar={'trace_id': trace_id}
)
在 Java Spring Boot 中,至少需要 Spring Boot 2.7 和 Micrometer 1.10,並且增加 Exemplar Sampler:
package com.example.app;
import io.prometheus.client.exemplars.tracer.otel_agent.OpenTelemetryAgentSpanContextSupplier;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class PrometheusExemplarSamplerConfiguration {
@Bean
public OpenTelemetryAgentSpanContextSupplier openTelemetryAgentSpanContextSupplier() {
// OpenTelemetryAgentSpanContextSupplier is from the opentelemetry agent jar, without using the agent will cause class not found error when running.
return new OpenTelemetryAgentSpanContextSupplier();
}
}
同時設定 application.yaml:
management:
metrics:
distribution:
percentiles-histogram:
http:
server:
requests: 'true'
設定完成後,是用瀏覽器連覽 Metrics 預設路經 /actuator/prometheus 取得的指標仍為 Prometheus Metrics 格式,要取得服務 OpenMetrics 格式的 Metrics 必須增加 Accept: application/openmetrics-text 的 Header,例如使用 curl:
curl 'http://localhost:8080/actuator/prometheus' -i -X GET \
-H 'Accept: application/openmetrics-text; version=1.0.0; charset=utf-8'
但 Prometheus 會自動抓取 OpenMetrics 格式的 Metrics,因此 Prometheus 的爬取設定不用額外調整。
Prometheus 必須啟用收集 Exemplar 的功能。可以透過 --enable-feature=exemplar-storage 參數啟用:
# docker-compsoe.yml
prometheus:
image: prom/prometheus:v2.28.1
command:
- "--enable-feature=exemplar-storage"
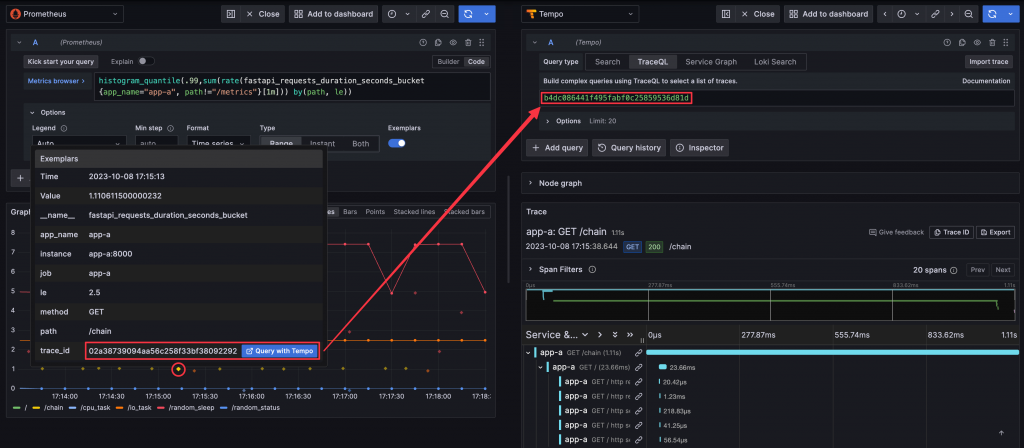
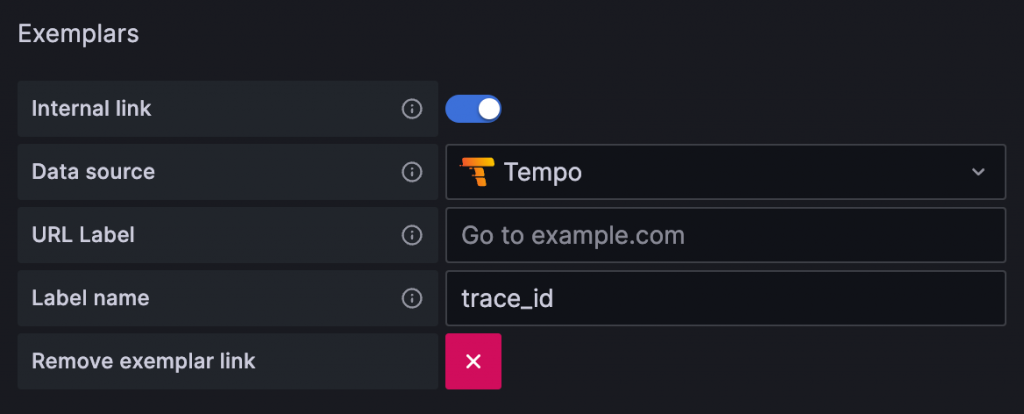
在 Grafana 中,Prometheus 的 Data Source 需設定 Exemplar 要連結的 Trace Backend,例如 Tempo 或 Jaeger,並指定 Metrics 中的 Trace ID 的 label 名稱,例如 trace_id

Metrics 後面附註的 Exemplar 的 Trace ID label 必須要與 Prometheus Data Source 一致,才能取得 Trace ID
於 Grafana 查詢 Metrics 時,需要啟用 Exemplar
OpenMetrics 是一個基於 Prometheus Metrics 設計的開源 Metrics 格式標準。它旨在容納更多非 Prometheus Metrics 格式的資料,例如早在 Prometheus 之前就已存在的 SNMP Metrics。這些傳統業界廠商更傾向遵循完全開放、廠商中立、無商標含義的標準,為了可以容納更多非 Cloud Native 的監控服務,出於政治因素 OpenMetrics 就誕生了。在 Kubernetes Podcast 的 Prometheus and OpenMetrics, with Richard Hartmann 中,同時是 OpenMetrics 的創立者以及 Prometheus team member 的 Richard Hartmann 也提到了建立 OpenMetrics 的緣由:
ADAM GLICK: Given all the work that you're doing with Prometheus, how did that lead you into creating the OpenMetrics Project?
RICHARD HARTMANN: Politics. It's really hard for other projects, and especially for other companies, to support something with a different name on it. Even though Prometheus itself doesn't have a profit motive, so we don't have to have sales or anything, it was hard for others to accept stuff which is named after Prometheus in their own product. And this is basically why I decided to do that.
Traces 和 Logs 的關聯是 Trace ID。在 Grafana 的 Loki 和 Tracing Backend Data Source 設定完成後,有兩種方式可以達成這種關聯:
檢視 Trace 時,可以透過連結查詢含有 Trace ID 的 Log。
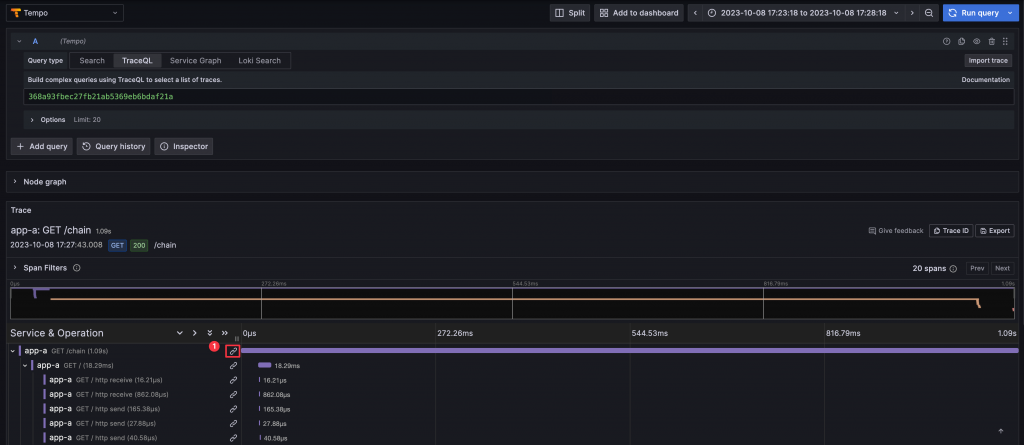
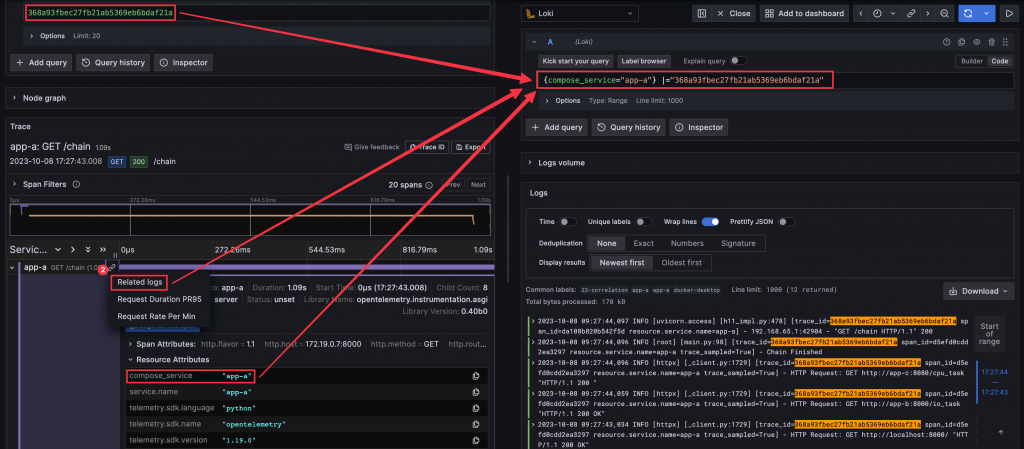
檢視 Log 時,可以透過連結查詢 Log 中 Trace ID 對應的 Trace。
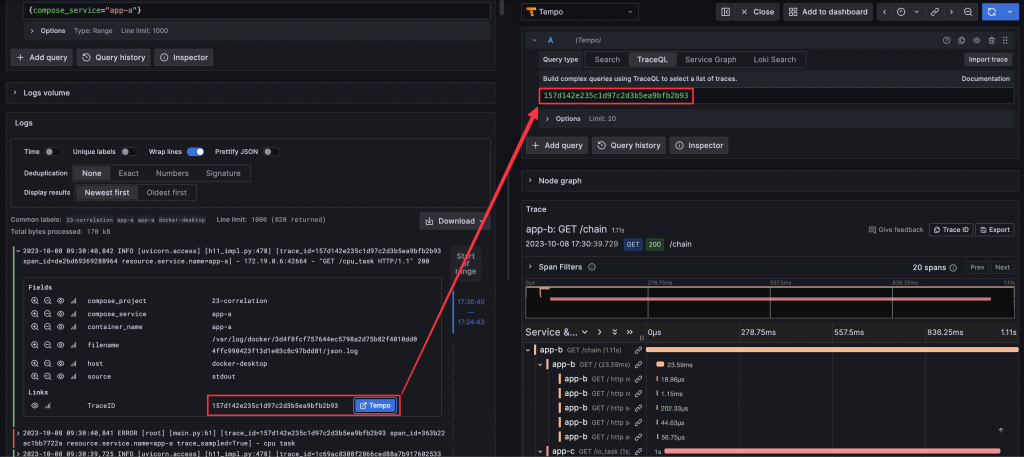
若要建立 Log 和 Trace 的關聯,請確保完成以下設定:
Application 的 Log 必須包含 Trace ID。
在 Python 中可以利用 OpenTelemetry logging integration 將 Trace ID 加入 Log,有兩種方式:
使用 OpenTelemetry Automatic Instrumentation 並設定 OTEL_PYTHON_LOG_CORRELATION="true" 環境變數,就可以自動將 Trace ID 加入 Log 中,詳細設定可參考官方文件
使用 OpenTelemetry Manual Instrumentation 方式:
from opentelemetry.instrumentation.logging import LoggingInstrumentor
LoggingInstrumentor().instrument(set_logging_format=True)
在 Java 中,使用 OpenTelemetry Automatic Instrumentation 後可以搭配 Log4j 和 Logback,再利用 Logger MDC auto-instrumentation 和 MDC 機制,將 Trace ID 加入 Log Pattern 中。例如:
logging:
pattern:
level: "trace_id=%mdc{trace_id} span_id=%mdc{span_id} trace_flags=%mdc{trace_flags} %p"
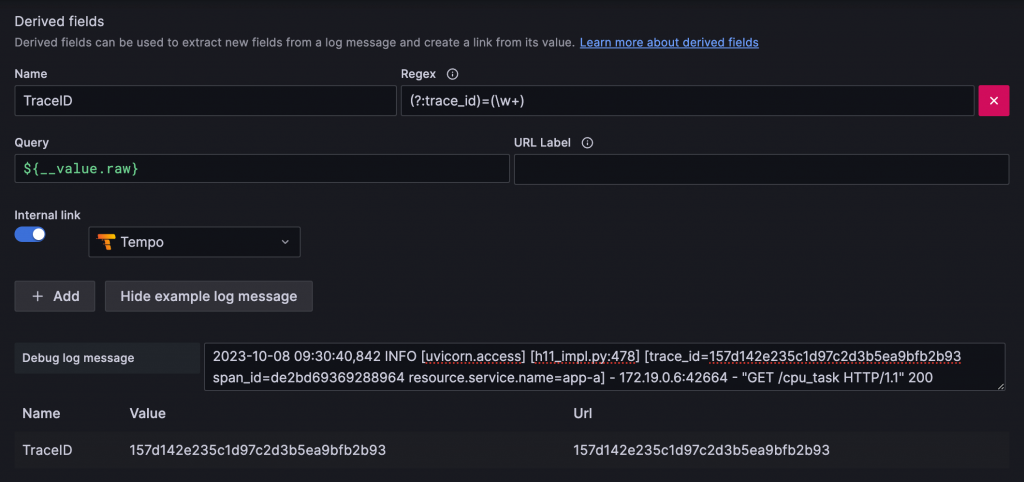
Log 中的 Trace 連結:Grafana 中 Loki Data Source 必須設定要連結的 Tracing Backend,以及定義正規表達式來抓取 Log 內容中的 Trace ID,例如 (?:trace_id)=(\w+)。在設定畫面中可以貼上實際 Log 內容,用於驗證是否能正確抓取到 Trace ID。
Trace 中的 Log 連結:Grafana 中 Tracing Backend Data Source 必須設定要連結的 Loki Data Source,並且至少定義一組 Trace 中的 Attribute 作為查詢 Loki 時使用的 Label,例如 compose_service
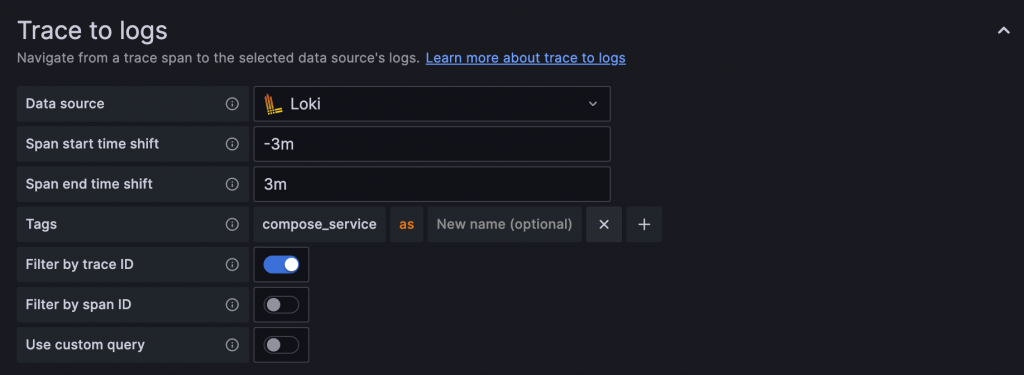
可以觀察前面範例圖中,該筆 Span 的 Attribute compose_service pair 變成 Loki 的查詢參數之一
Grafana 9.1 版中新增了 Trace 連結到 Metics 的功能。透過預先設定好的 PromQL,可以將 Traces 的 Attribute 帶入 PromQL 中,進而查詢出相關的 Metrics 資料。例如,可以搭配 Tempo 中 Metrics-generator 的 Span Metrics 功能所產生的 Metrics。
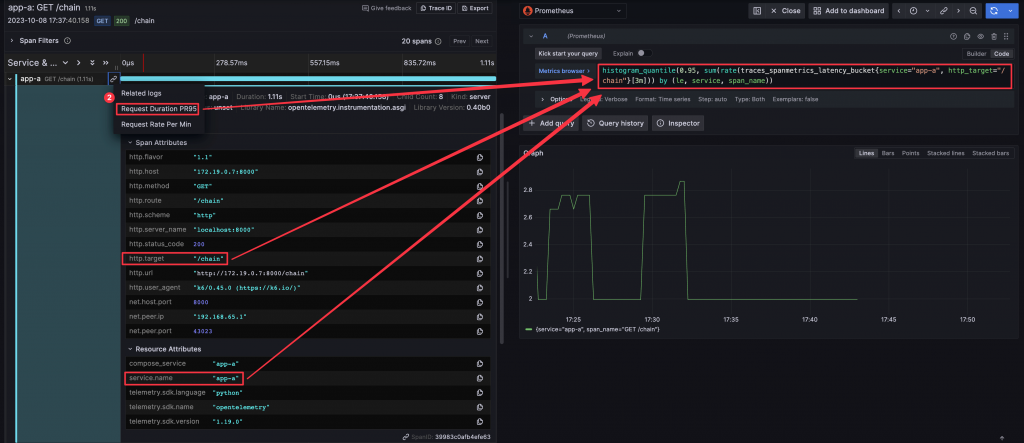
查詢該筆 Span 的 Request Duration PR95 Metrics
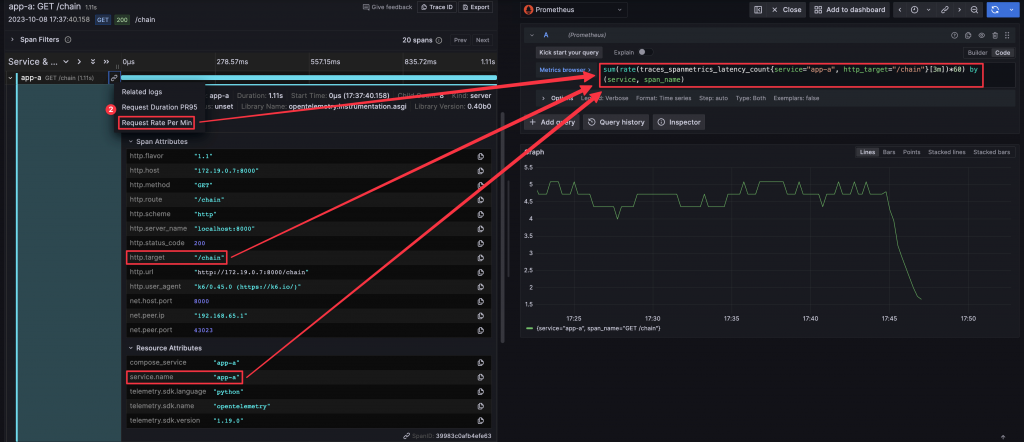
查詢該筆 Span 的 Request Rate Per Min Metrics
若要讓 Trace 能與 Metrics 連結,必須確保完成以下設定:
Grafana 需要啟用 traceToMetrics 功能,可以透過環境變數啟用:
# docker-compose.yml
grafana:
image: grafana/grafana:10.1.0
environment:
GF_FEATURE_TOGGLES_ENABLE: "traceToMetrics"
Tracing Backend Data Source 的設定需要連結到存有相關 Metrics 的 Prometheus Data Source,並設定 Metrics 的 PromQL
動態查詢條件的設定方式為,透過設定選擇指定的 Traces Attributes,Grafana 會將其轉換為 Label-Value Pair 放入 $__tags 變數中,PromQL 可以在利用 $__tags 作為 Label Selector
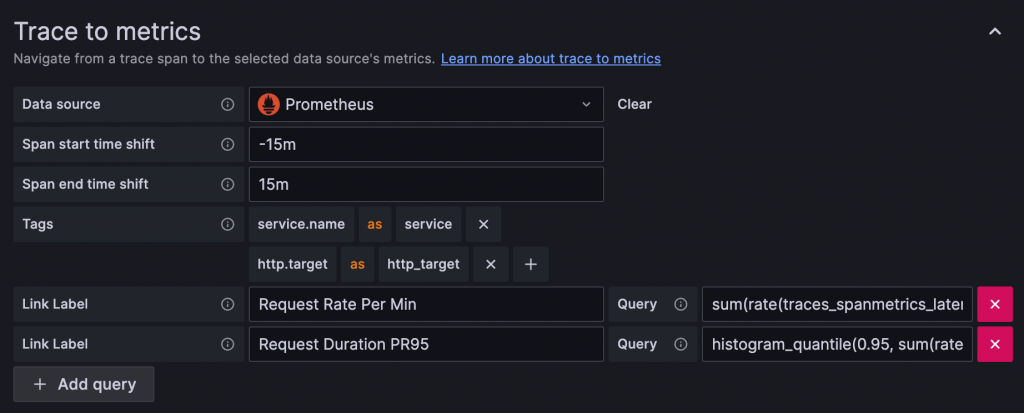
圖中設定了兩個動態參數,分別為將 Span 中的 Attribute service.name 變為 PromQL 中的 servcie,以及 http.target 變為 PromQL 中的 http_target
範例程式碼:23-correlation
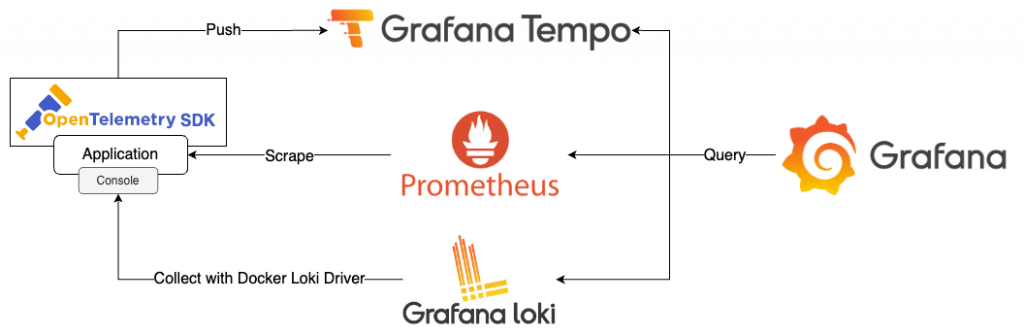
Lab 架構圖
docker plugin install grafana/loki-docker-driver:latest --alias loki --grant-all-permissions
啟動所有服務
docker-compose up -d
檢視服務
admin/admin
使用 k6 發送 Request
k6 run --vus 1 --duration 300s k6-script.js
使用 Explore 檢視 Tempo、Loki、Prometheus 資料
關閉所有服務
docker-compose down
/metrics endpoint/actuator/prometheus endpointsum(rate(fastapi_requests_total{app_name="app-a"}[3m])*60) by(app_name, path),計算出每分鐘的 Request 數量container_name=app-a,查詢出 app-a 的 Loghistogram_quantile(.99,sum(rate(fastapi_requests_duration_seconds_bucket{app_name="app-a", path!="/metrics"}[1m])) by(path, le)),並展開 Options 選單啟用 Exemplarscontainer_name=app-a,查詢出 app-a 的 Log,點擊某筆 Log 展開 Log 明細,可以看到該筆 Log 的 Trace id,點擊 Tempo 可以查詢該 Trace 的資料{resource.service.name="app-a" && name="GET /chain"}
Related logs,可以查詢該 Span 對應的 Service 與 Trace id 的 Log{resource.service.name="app-a" && name="GET /chain"}
Request Duration PR95 或 Request Rate Per Min,可以查詢使用該 Span Attributes 作為查詢條件的 Metrics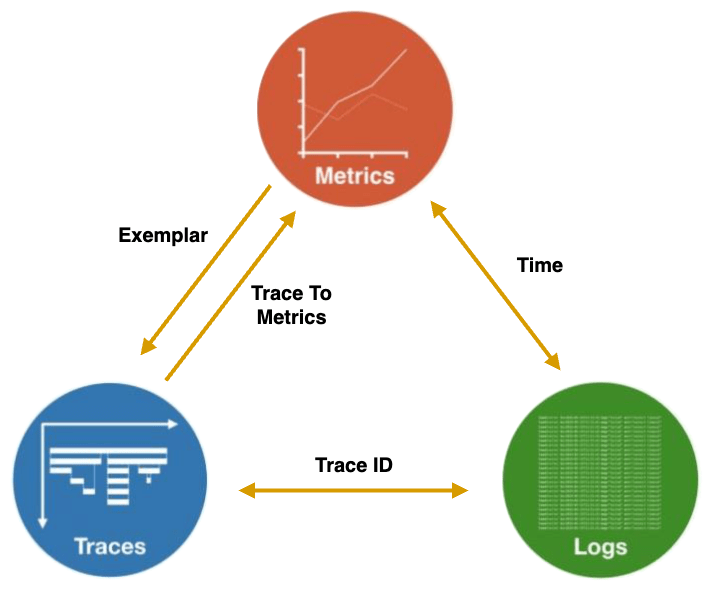
將 Metrics、Logs、Traces 三者互相關聯,能讓我們在問題排除時更迅速地找到根源,並了解問題的具體上下文。這種多維度的資訊整合不僅加速了問題解決,也能夠透過這樣的架構更快找出系統瓶頸點提高效能與穩定性。
Grafana 作為一個多功能的可觀測性平台,在同一個介面內統一呈現 Metrics、Logs 和 Traces,並透過各種內建功能實現這些資訊的互相關聯。不僅是解決了資訊分散各處的 Data Silo 問題,更進一步讓資訊搭配產生綜效,讓 1 + 1 + 1 呈現遠大於 3 的效果。