
在 Observability 的實踐中,我們儘量透過多樣的工具,讓服務自動提供各類數據,例如 API 請求頻率、執行時間分布等,以便讓服務更透明且便於維護。然而,在實務中,我們會發現某些服務並無此能力。可能是因為該系統過於老舊、缺乏相容工具,或是調整風險過高。這時,OpenTelemetry Collector 的 Span Metrics Connector 功能便能派上用場,它能將 Trace 資料轉換成 Metrics 資料,讓我們能更直觀地掌握服務狀態。
Span Metrics Connector 是 OpenTelemetry Collector 的 Conrib 版本中的一個 Connector,能將 Trace 轉換為 Metrics。使用務必注意要使用 Conrib 版本才能正常啟用,其在 Collector 中的配置範例如下:
# etc/otel-collector-config.yaml
receivers:
otlp:
protocols:
grpc: # enable gRPC protocol, default port 4317
http: # enable http protocol, default port 4318
exporters:
otlp:
endpoint: tempo:4317
tls:
insecure: true
prometheus:
endpoint: "0.0.0.0:8889" # expose metrics on port 8889
connectors:
spanmetrics:
processors:
batch: # Compress spans into batches to reduce network traffic
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [spanmetrics, otlp]
metrics/spanmetrics:
receivers: [spanmetrics]
exporters: [prometheus]
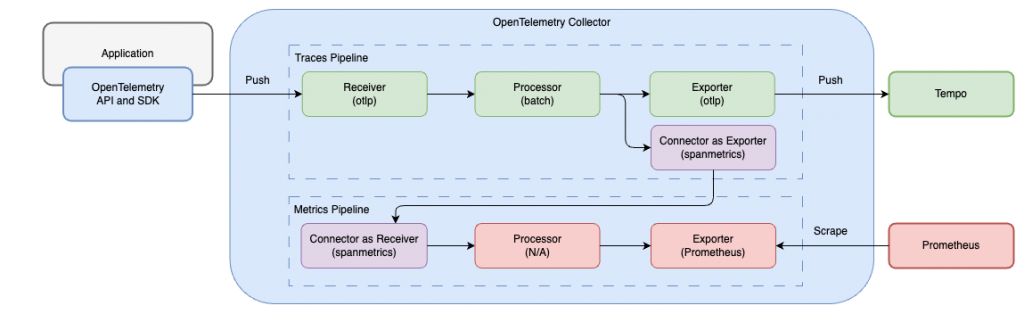
資料處理流程如上圖所示。首先,通過 traces Pipeline 收集 Trace 資料。最後,在輸出至 Tempo 的同時,也會將資料輸出至 spanmetrics Connector。這些輸出的資料會變成 metrics/spanmetrics Pipeline 的輸入,並最終被輸出至 prometheus Exporter,該 Exporter 會在 Collector 的 8889 Port 揭露 Metrics。
預設輸出的 Metrics 資料有四種:
calls_total: 總共呼叫次數duration_milliseconds_bucket: 執行時間分布duration_milliseconds_sum: 執行時間總和duration_milliseconds_count: 執行次數總計預設的 Metrics Label 包括:
service.name 取得name 取得span.kind 取得status.code 取得若需要自訂 Metrics Label,可透過 dimensions 參數進行添加,例如:
connectors:
spanmetrics:
dimensions:
- name: http.method # 增加 http.method 作為 Metrics Label,在 Metrics 中會變成 http_method
- name: http.status_code # 增加 http.status_code 作為 Metrics Label,在 Metrics 中會變成 http_status_code
- name: http.route # 增加 http.route 作為 Metrics Label,在 Metrics 中會變成 http_route
需要注意的是,為避免過度消耗 Collector 的記憶體,Label 的排列組合數量預設為 1000。如果需調整,可以透過 dimensions_cache_size 參數進行設定,例如:
connectors:
spanmetrics:
dimensions_cache_size: 10000 # 調整排列組合的數量為 10000 筆
取得由 Span Metrics Connector 轉換產生的 Metrics 後,我們可以建立 Dashboard 來監控服務狀態,例如:
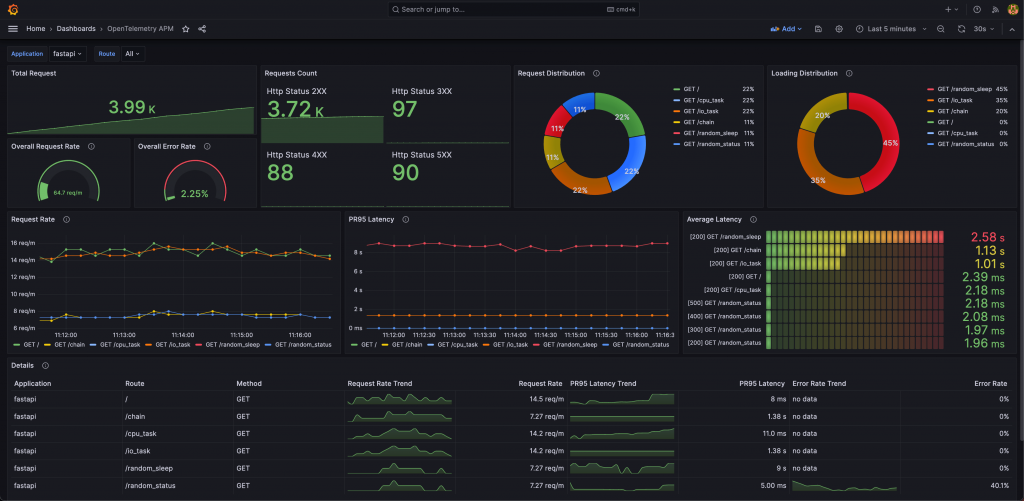
範例專案可參考 OpenTelemetry Application Performance Management 或本篇 Lab
更多參數詳情,請參考 Span Metrics Connector 的 README。
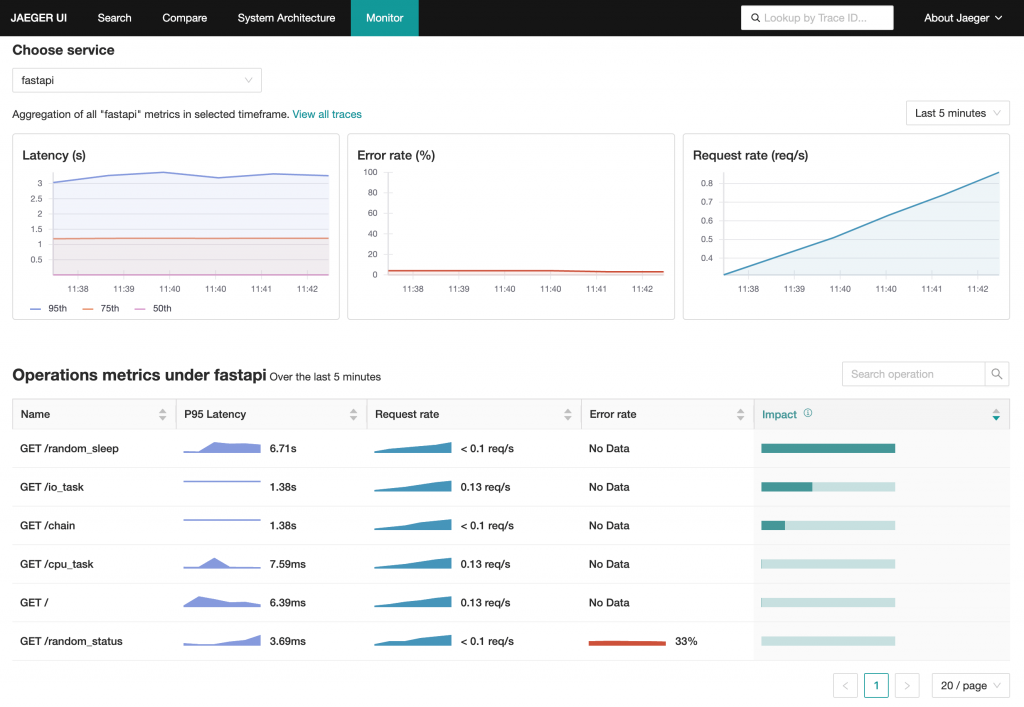
從 Jaeger 1.43 版本起,正式推出了 Jaeger Service Performance Monitoring 功能。此功能同樣利用 OpenTelemetry Collector 的 Span Metrics Connector 將 Trace 轉換成 Metrics,並與 Jaeger UI 相結合,直接提供有關請求、錯誤、執行時間(RED Metrics)的服務狀態分析。資料流程如下圖所示:
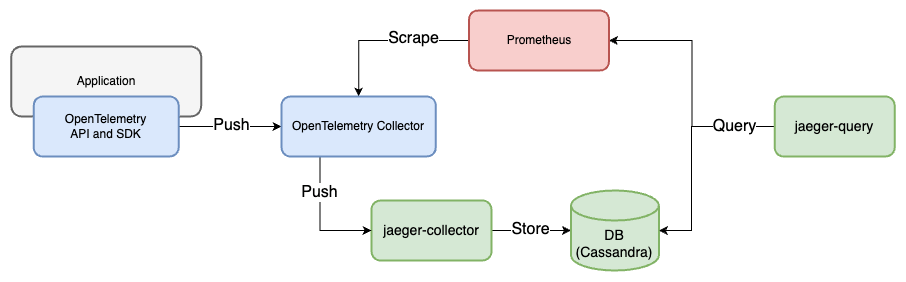
在 Jaeger 1.50 版本和 OpenTelemetry Collector 0.86 版本下運行時,Jaeger Query 必須搭配以下設定,才能從 Prometheus 正確取得 Metrics:
METRICS_STORAGE_TYPE=prometheus
--prometheus.query.support-spanmetrics-connector=true
--prometheus.server-url=http://prometheus:9090
--prometheus.query.normalize-duration=true
--prometheus.query.normalize-calls=true
如果使用 OpenTelemetry Collector 0.80 以上的版本,發生 Service Performance Monitoring 無法顯示 Metrics 的問題,是因為 0.80 版後 Span Metrics Connector 變更了 Metrics 名稱。在Jaeger 1.47 版本的 Support normalized metric names #4555 Commit 中已經支援新的 Metrics 名稱。需同時設定 --prometheus.query.normalize-duration=true 和 --prometheus.query.normalize-calls=true,以正常顯示度量資料。
範例程式碼:24-metrics-from-traces
啟動所有服務
docker-compose up -d
檢視服務
admin/admin
使用 k6 發送 Request
k6 run --vus 1 --duration 300s k6-script.js
點擊左上 Menu > Dashboards > OpenTelemetry APM,即可看到透過 Provisioning 建立的 Dashboard
關閉所有服務
docker-compose down
啟動所有服務
docker-compose -f docker-compose.jaeger.yaml up -d
檢視服務
因 Cassandra 需要一些時間初始化,確認 Jaeger Collector 與 Jaeger Query 已啟動後,再繼續下一步
docker-compose ps
FastAPI App: http://localhost:8000
Spring Boot App: http://localhost:8080
Prometheus: http://localhost:9090
Jaeger UI: http://localhost:16686
使用 k6 發送 Request
k6 run --vus 1 --duration 300s k6-script.js
選擇 Jaeger UI 上方選單 Monitor 頁籤,可查看服務儀表板
關閉所有服務
docker-compose -f docker-compose.jaeger.yaml down
Span Metrics Connector 可將 Trace 轉為 Metrics,這個特性讓服務不必自行提供 Metrics 資料;只要能取得 Trace,就能產生與 Request 相關的 Metrics。這對於無法輕易修改服務或採集數據的環境而言,是一大利多。除了透過 OpenTelemetry 的 Automatic Instrumentation 來快速獲得 Trace,也可以選擇像 Istio 這種 Service Mesh,利用 Sidecar 機制監控網路流量資料就能獲得完整的 Trace。
這個概念與前面的 Tempo 章節介紹的 Metrics-generator 很相似。Tempo 也是直接分析 Trace 以生成 Metrics,甚至能根據 Trace 繪製出服務的關聯圖。這些例子都說明了 Trace 是一種極具價值的資料。它內含豐富的信息和各種潛在的數據,未來可能還會有更多工具能以 Trace 為基礎,產生更多有用的數據,幫助我們更精準地觀察服務狀況。
