技術文章
技術問答
iT 徵才
聊天室
2026 鐵人賽
登入/註冊
文章
問答
Tag
邦友
鐵人賽
搜尋
2023 iThome 鐵人賽
DAY
28
0
AI & Data
AI白話文運動系列之「A!給我那張Image!」
系列 第
28
篇
AI研究趨勢討論(二)--遷移學習、領域自適應與領域泛化
15th鐵人賽
理工哈士奇嗷嗚嗷嗚
2023-10-13 23:02:53
1307 瀏覽
分享至
前言
今天我們跳脫理論,用輕鬆的方式帶大家看看如果要實際應用AI模型會遇到怎樣的問題,以及有哪些相關的研究領域在處理這些問題。
先備知識
一顆放鬆的心
看完今天的內容你可能會知道......
AI模型遇到訓練資料與實際應用資料不一致怎麼辦
遷移學習是甚麼
領域自適應和領域泛化是甚麼
一、遷移學習概述
參考資料與延伸閱讀:
https://arxiv.org/pdf/1702.05374.pdf
我們之前介紹過的很多模型、應用情境,都是利用訓練資料訓練好模型後,使用在實際資料上,聽起來好像很正常,沒什麼不對的,但是這樣的過程有個很致命的問題:如果訓練用的資料與實際要用的資料差很多的話怎麼辦?又或者,兩者的標註(Label)也不一樣該怎麼辦?這就是我們今天要聊的第一個領域:遷移學習(Transfer Learning,簡稱TL)。
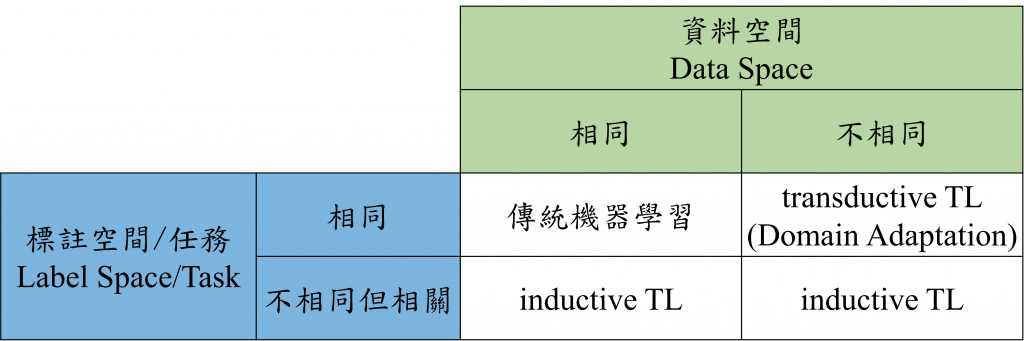
在往下展開討論之前,我們一樣要先把問題定義清楚,今天有兩個域(Domain),一個稱為源域(Source domain),另一個稱為目標域(Target domain),前者指的是我們在訓練時所使用的資料分布的空間,後者則是指我們要應用的資料分布的空間,這種域又可以再往下細分成資料(Data)空間與標註(Lable)空間,如果源域的資料空間和目標域的資料空間不相同的話,或者兩者的標註空間不相同,就是遷移學習的問題。如果只有資料空間不相同,但是標註空間相同的話,就是領域自適應(Domain adaptation)的問題,而標註空間不同的話,就是歸納式遷移學習(Inductive transfer learning)。
以上的這些內容可以用下圖來概述:
有個也是相當熱門的研究領域:領域泛化(Domain generalization),可以理解成是領域自適應的特例,通常在討論領域自適應時,我們的源域只有一個,如果有很多個源域的話,在訓練時可以更好的提升模型的泛化性,這就是領域泛化在討論的問題。
二、歸納式遷移學習(Inductive transfer learning)
為甚麼遷移學習很重要也很熱門,因為訓練一個好的、厲害的、強大的AI模型需要很強大的運算資源,除了需要好的設備以外,也要花很多錢跟時間來訓練模型,因此,如果我們能把大公司訓練好的模型借過來使用的話,是不是就可以免去很多煩惱了?這樣的動作聽起來有沒有很熟悉?如果有的話,沒錯!這就是我們之前一直在做的事情,在幾乎每個實戰的章節中,我都會介紹Pytorch中預訓練模型的使用方法,也有提到過這些預訓練模型幾乎都是訓練在大型資料集ImageNet上的,可以用來處理1000類的分類任務,可是,之前我們的任務幾乎都是10個類別的分類任務,那時候我們是怎麼做的呢?我們稍微修改了一下最後一層的參數,接著在我們的訓練資料集上,稍微訓練一下帶有預訓練權重的模型,這個動作其實就是我們很常聽到的「微調(Fine-tune)」,而這就是在我們同時有兩個域的資料與標註時最常使用的手法。
雖然一個是1000個類別的,另一個是10個類別的任務,但是這兩者的任務是具有相關性的(可見下圖,場景類似,分類的類別也有重疊),所以我們可以通過微調的方式,將已經學習到的知識「遷移」到新的應用情境中。或許有人會想問說,那甚麼是不相關的任務呢?我想,大概就像一個任務是要學習英文到中文的翻譯,另一個任務是學習辨識貓狗的圖片一樣。
更詳細的資料集介紹可以看:
https://paperswithcode.com/dataset/imagenet
與
https://paperswithcode.com/dataset/cifar-10
三、領域自適應(Domain adaptation)與領域泛化(Domain generalization)
因為領域自適應和領域泛化的假設與情境類似,所以我們暫且放在一起討論。上面有提到同時有來自原域與目標域的所有資訊時,可以使用微調來修正模型,但是,如果很不幸的,我們只有來自源域的資料與標註,以及來自目標域的無標註資料,那麼我們能怎麼處理呢?
第一種作法是學習一些不會隨著Domain改變的特徵,讓模型在判斷時更加穩定。甚麼意思呢?可以回憶一下,我們在學習數學的時候,有沒有曾經在遇到新的題型或觀念的時候,好像能夠抓到某種技巧,讓你比別人更快理解的經驗?如果有的話,恭喜!這種技巧可以說是對於不同的題型或觀念都是不變的,所以如果掌握了這樣的技巧的話,我們對於新的題目或觀念會更有彈性,更加游刃有餘。AI中也有這樣的東西,我們稱之為「域不變特徵(Domain-invariant features)」,顧名思義,就是指那些,對於不同域的輸入也不會偏移太多的特徵。透過讓模型學習這些特徵,我們可以使模型同時運作在源域與目標域上。
第二種做法是通過某種轉換的方式,將來自目標域的缺乏標註的資料轉對應到源域的資料,這麼一來,因為我們有源域的標註,所以也可以藉此得到目標域的虛假標註(Pseudo-label),雖然不見得這樣的標註是正確的,但是有總比沒有好,所以我們可以利用這些虛假標註跟可信度更高的源域資料一起學習或微調,讓模型逐步學習目標域的知識。
礙於篇幅問題,有些更深入的內容沒辦法一一拿出來討論,以下提供幾篇參考論文,感興趣的人可以嘗試延伸閱讀看看:領域泛化
https://arxiv.org/pdf/2103.03097.pdf
;領域自適應
http://www.whdeng.cn/papers/18_Wang_Deng_DA_Survey.pdf
、
https://aclanthology.org/C18-1111/
四、總結
今天我們討論了AI這幾年很多人在進行的研究領域,因為模型越來越強大且運算環境越來越好,對模型的應用需求也隨之增加,相較於我們前兩天討論的模型壓縮與加速,今天的研究是著重在「弭平模型訓練到應用的落差」,也是個非常值得好好研究的方向!
留言
追蹤
檢舉
上一篇
AI研究趨勢討論(一)--模型壓縮與加速(Model Compression and Acceleration)後篇
下一篇
AI研究趨勢討論(三)--強強聯手打造新世代里程碑(CNN與ViT結合)
系列文
AI白話文運動系列之「A!給我那張Image!」
共
30
篇
目錄
RSS系列文
訂閱系列文
2
人訂閱
26
AI研究趨勢討論(一)--模型壓縮與加速(Model Compression and Acceleration)前篇
27
AI研究趨勢討論(一)--模型壓縮與加速(Model Compression and Acceleration)後篇
28
AI研究趨勢討論(二)--遷移學習、領域自適應與領域泛化
29
AI研究趨勢討論(三)--強強聯手打造新世代里程碑(CNN與ViT結合)
30
AI研究趨勢討論(四)--AI圖像生成(以Diffusion Model為例)
完整目錄
熱門推薦
{{ item.subject }}
{{ item.channelVendor }}
|
{{ item.webinarstarted }}
|
{{ formatDate(item.duration) }}
直播中
立即報名
尚未有邦友留言
立即登入留言
iThome鐵人賽
參賽組數
902
組
團體組數
37
組
累計文章數
19838
篇
完賽人數
528
人
看影片追技術
看更多
{{ item.subject }}
{{ item.channelVendor }}
|
{{ formatDate(item.duration) }}
直播中
熱門tag
15th鐵人賽
16th鐵人賽
13th鐵人賽
14th鐵人賽
17th鐵人賽
12th鐵人賽
11th鐵人賽
鐵人賽
2019鐵人賽
javascript
2018鐵人賽
python
2017鐵人賽
windows
php
c#
linux
windows server
css
react
熱門問題
趣味SQL,給了一組編號後,用SQL產生亂數編碼的結果(更新Copilot及Google AI見解,SQL只能貼圖)
關於ASUS RS100-E11-PI2的磁碟陣列
已解決已解決
AI會議轉錄如何盡可能縮小明文攻擊面?
熱門回答
關於ASUS RS100-E11-PI2的磁碟陣列
趣味SQL,給了一組編號後,用SQL產生亂數編碼的結果(更新Copilot及Google AI見解,SQL只能貼圖)
熱門文章
從注入攻擊到詐騙防護:@martin_yeung/llm-up-guardrail 為你的 AI 打造生產級安全防線
AI 推論正在吞噬雲端
從企業導入 AI Agent 現況,到 AI 投資市場敘事的差異
用 AI 寫 MCP server 很快就會跑,但「會跑」不等於「安全」——多租戶隔離的五條 best practice
Memory 系統 — 讓 Claude 不只記得「專案」,還記得「你」
IT邦幫忙
×
標記使用者
輸入對方的帳號或暱稱
Loading
找不到結果。
標記
{{ result.label }}
{{ result.account }}



 iThome鐵人賽
iThome鐵人賽