技術文章
技術問答
iT 徵才
聊天室
2026 鐵人賽
登入/註冊
文章
問答
Tag
邦友
鐵人賽
搜尋
2023 iThome 鐵人賽
DAY
26
0
AI & Data
AI白話文運動系列之「A!給我那張Image!」
系列 第
26
篇
AI研究趨勢討論(一)--模型壓縮與加速(Model Compression and Acceleration)前篇
15th鐵人賽
理工哈士奇嗷嗚嗷嗚
2023-10-11 20:32:33
1803 瀏覽
分享至
前言
今天我們會開始討論一些新的內容,預計會先聊聊AI接下來有哪些研究方向可以做,接著再聊聊最近比較熱門的AI技術。
先備知識
一顆放鬆的心
看完今天的內容你可能會知道......
大模型的侷限性
模型壓縮與加速的目標是甚麼
量化與知識蒸餾怎麼做到模型壓縮與加速
一、概述
跟著我們的腳步一路走到現在的人,應該可以感受到,AI模型越變越強大是離不開它們越來越複雜的設計的,這些設計除了讓模型有更好的表現以外,也讓模型需要更強大的硬體配合,才能正常運行。上圖是近年來熱門的CNN模型,顏色代表年分,圈圈的面積代表模型大小,而越往右邊的模型代表它們需要更多的計算量。
如果這些厲害的模型只能用在很厲害的電腦上的話,應用範圍就非常侷限。或許有人會說,可以把這些厲害的模型放到大型電腦架起來的雲端上運行,需要的時候再把輸入資料傳上去就好,這確實也是一種解決方式,不過這種方式會受限於傳輸速度與傳輸的容量,舉例來說,因為需要把資料丟到雲端上面,如果在網路比較不好的地方,就需要傳很久,或是檔案太大的話,也要傳很久。更具體一點,如果是自駕車應用的話,這樣做是不是就挺危險的?在真實道路上,多延遲一秒的決定時間,或許就會引發車禍。
如果最近有嘗試使用chatGPT的人或許會更有感觸,因為我們使用chatGPT的時候就是將資料輸入給openAI他們的電腦資源運算,運算完之後再把輸出結果回傳給每個使用者,這個過程如果遇到人太多或是我們輸入的資料太多時,就會需要等待比較久才能得到回應。
因此,在追求模型表現的同時,有一些研究領域應運而生,這些領域專門在處理AI模型的壓縮與加速,讓這些好的模型可以應用在硬體設備沒那麼好的裝置上面,如此就可以拓展AI模型的應用情境了。
在往下介紹這些方法之前,請讓我們把問題定義得更清楚一點,所謂的「壓縮」指的是「模型的參數量減少」,如果一個模型有非常多的參數的話,有些儲存空間不大的硬體設備就沒辦法承載這樣的模型;所謂的「加速」則是指「模型的計算複雜度減少」,如果我們要衡量運行一個系統所需的計算量的話,用時間來衡量似乎不太對勁,畢竟不同的電腦運行通個程式的時間本來就會不太一樣,所以「計算複雜度」是一個理論值,用來估計運行一個系統所需要的計算量,這樣的概念也可以被我們用來衡量AI模型:計算複雜度較少的模型,意味著它可以運行在硬體條件受限的環境。
模型壓縮與加速總共有四種常見的方法,通過不同的角度出發,試圖減少模型的參數量與計算複雜度,這些方法我們雖然是分開介紹的,不過實際使用他們的時候可以並用,換句話說就是「這些方法彼此不互相衝突」,分開介紹只是因為他們的設計概念不相同,不代表他們是互斥的。
二、模型壓縮與加速方法一:量化(Quantization)
在電腦中,我們會用特定數量的單位儲存一個數字,以Pytorch為例,通常是用32個單位儲存一個數字,會許有人會納悶為甚麼需要這麼多單位,因為AI模型的訓練是很嚴謹的,裡面會有很多的小數點,所以能夠越精準越好。
這樣的話,有一個很直覺的想法就是:如果我可以減少儲存一個數字所需要的單位數量,是不是就可以縮小儲存整個模型所需要的儲存空間?
沒錯!這就是我們要介紹的第一個模型壓縮與加速的方法:量化(Quantization)
以上圖為例,如果是一般情況,每個參數都需要32個單位負責記錄,可是如果我們改成使用8個單位,整個模型就會直接縮小。
三、模型壓縮與加速方法二:知識蒸餾(Knowledge Distillation)
在說明這個方法之前,我們可以想一下,如果今天你是一個數學系的教授,你需要教你3歲的小孫子微積分,你會怎麼教?3歲小孩的記憶力與理解能力有限,可能沒辦法聽懂很複雜又很龐大的知識基礎,所以,你應該會挑一些重點跟關鍵來教吧?這樣,雖然你孫子沒辦法理解非常完整的脈絡,可是如果你讓他做一些微積分習題,他也有可能可以作答的非常好。
這就是知識蒸餾的概念,在AI的世界中,我們也有許多教授級的大模型,這些模型很大很複雜,可以處理很多的問題,但是這些教授們要請出場的代價太高了,所以我們可以讓這些教授教我們這種3歲的初學者,讓我們模仿他們的作答過程,如果學習的很好的話,我們就能夠像教授一樣把特定的問題處理得很好,可是我們的出場費用又比較低,真是皆大歡喜(?
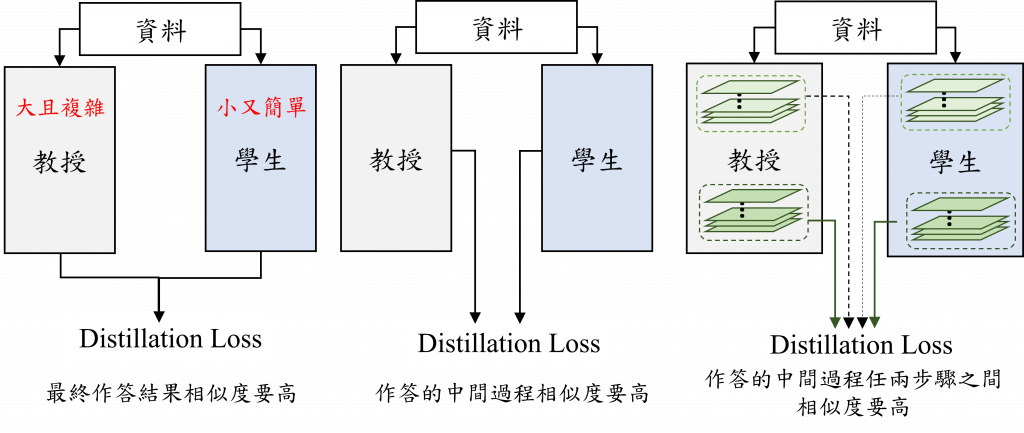
為了讓3歲小孩也可以作答微積分習題,我們可以使用三種常見的訓練方式,第一種是要求最終作答的結果要跟教授的作答結果類似,這樣的話,雖然小孩不懂中間的作答過程在做甚麼,可是也能把題目做對;第二種的話,是限制小孩子中間的作答過程要跟教授的過程類似,這種方式會促使小孩的思考與判斷過程要跟教授的類似,有助於理解問題;最後一種則是我們先找出整個作答過程中最關鍵的幾個步驟,然後希望小孩子的這些步驟能夠做的很教授的類似,就像做數學題一樣,我們的解題過程可能會有一些彎彎繞繞的想法,這種方式是希望小孩子的重要轉折點要跟教授的一樣。
如果以分類任務的CNN來理解的話,第一種方法是希望分類結果要相同,第二種方法是希望中間提取出的特徵要類似,這樣說明兩個模型提取關鍵資訊的能力類似,最後一種方法是希望特定捲積層處理關鍵資訊的方式類似。
四、總結
今天我們開了個頭,和大家介紹模型壓縮與加速的動機與必要性,並且分享了兩種知名的模型壓縮與加速方法:量化與知識蒸餾。礙於另外兩種方法需要更多的數學描述,所以我們會放到明天再繼續說明,預計也會利用一些程式實戰輔助介紹,再請大家拭目以待!
留言
追蹤
檢舉
上一篇
CNN經典論文實戰(五)--DenseNet
下一篇
AI研究趨勢討論(一)--模型壓縮與加速(Model Compression and Acceleration)後篇
系列文
AI白話文運動系列之「A!給我那張Image!」
共
30
篇
目錄
RSS系列文
訂閱系列文
2
人訂閱
26
AI研究趨勢討論(一)--模型壓縮與加速(Model Compression and Acceleration)前篇
27
AI研究趨勢討論(一)--模型壓縮與加速(Model Compression and Acceleration)後篇
28
AI研究趨勢討論(二)--遷移學習、領域自適應與領域泛化
29
AI研究趨勢討論(三)--強強聯手打造新世代里程碑(CNN與ViT結合)
30
AI研究趨勢討論(四)--AI圖像生成(以Diffusion Model為例)
完整目錄
熱門推薦
{{ item.subject }}
{{ item.channelVendor }}
|
{{ item.webinarstarted }}
|
{{ formatDate(item.duration) }}
直播中
立即報名
尚未有邦友留言
立即登入留言
iThome鐵人賽
參賽組數
902
組
團體組數
37
組
累計文章數
19838
篇
完賽人數
528
人
看影片追技術
看更多
{{ item.subject }}
{{ item.channelVendor }}
|
{{ formatDate(item.duration) }}
直播中
熱門tag
15th鐵人賽
16th鐵人賽
13th鐵人賽
14th鐵人賽
17th鐵人賽
12th鐵人賽
11th鐵人賽
鐵人賽
2019鐵人賽
javascript
2018鐵人賽
python
2017鐵人賽
windows
php
c#
linux
windows server
css
react
熱門問題
趣味SQL,給了一組編號後,用SQL產生亂數編碼的結果(更新Copilot及Google AI見解,SQL只能貼圖)
關於ASUS RS100-E11-PI2的磁碟陣列
已解決已解決
AI會議轉錄如何盡可能縮小明文攻擊面?
熱門回答
關於ASUS RS100-E11-PI2的磁碟陣列
趣味SQL,給了一組編號後,用SQL產生亂數編碼的結果(更新Copilot及Google AI見解,SQL只能貼圖)
熱門文章
從注入攻擊到詐騙防護:@martin_yeung/llm-up-guardrail 為你的 AI 打造生產級安全防線
AI 推論正在吞噬雲端
從企業導入 AI Agent 現況,到 AI 投資市場敘事的差異
用 AI 寫 MCP server 很快就會跑,但「會跑」不等於「安全」——多租戶隔離的五條 best practice
Memory 系統 — 讓 Claude 不只記得「專案」,還記得「你」
IT邦幫忙
×
標記使用者
輸入對方的帳號或暱稱
Loading
找不到結果。
標記
{{ result.label }}
{{ result.account }}




 iThome鐵人賽
iThome鐵人賽