

到目前為止,我們基本上談完了四種經典哦模型壓縮與加速方法。在這個章節中,我們將會用簡單的方式帶大家嘗試一下這四種不同的模型壓縮與加速方法,並且延伸討論每個方法在研究上的方向或難處。
import torchvision
import os
import torch
model = torchvision.models.vgg16(pretrained=True)
# 先將模型保存起來,接著讀取檔案大小來判斷模型大小
def print_model_size(mdl):
torch.save(mdl.state_dict(), "tmp.pt")
print("%.2f MB" %(os.path.getsize("tmp.pt")/1e6))
os.remove('tmp.pt')
# 設定量化參數
backend = "qnnpack"
model.qconfig = torch.quantization.get_default_qconfig(backend)
torch.backends.quantized.engine = backend
model_static_quantized = torch.quantization.prepare(model, inplace=False)
model_static_quantized = torch.quantization.convert(model_static_quantized, inplace=False)
# 比較量化前後的模型大小
print_model_size(model)
print_model_size(model_static_quantized)
backend = "qnnpack"是表示我們的模型需要應用在哪種裝置上,如果是x86架構上的話就是fbgemm,如果是ARM架構的話就是qnnpack。通過上面這樣的方式,可以將預訓練模型從需要32個單位儲存的Float32型態換成只需要8個單位儲存的int8型態,模型大小也會大幅縮減:553.44 MB # 量化前
138.42 MB # 量化後
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision
# Check if GPU is available, and if not, use the CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Below we are preprocessing data for CIFAR-10. We use an arbitrary batch size of 128.
transforms_cifar = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 載入與包裝資料集
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transforms_cifar)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transforms_cifar)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=2)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=128, shuffle=False, num_workers=2)
# 定義學生模型
class LightNN(nn.Module):
def __init__(self, num_classes=10):
super(LightNN, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(16, 16, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(1024, 256),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(256, num_classes)
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
# 定義一般訓練用的函數
def train(model, train_loader, epochs, learning_rate, device):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
model.train()
for epoch in range(epochs):
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}/{epochs}, Loss: {running_loss / len(train_loader)}")
# 定義模型評估函數
def test(model, test_loader, device):
model.to(device)
model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f"Test Accuracy: {accuracy:.2f}%")
return accuracy
# 微調教授模型
vgg = torchvision.models.vgg16(pretrained=True)
vgg.classifier[-1] = nn.Linear(4096, 10)
train(vgg.to(device), train_loader, epochs=5, learning_rate=0.0001, device=device)
test_accuracy_deep = test(vgg, test_loader, device)
# 定義學生模型的訓練函數
def train_knowledge_distillation(teacher, student, train_loader, epochs, learning_rate, T, soft_target_loss_weight, ce_loss_weight, device):
ce_loss = nn.CrossEntropyLoss()
optimizer = optim.Adam(student.parameters(), lr=learning_rate)
teacher.eval() # Teacher set to evaluation mode
student.train() # Student to train mode
for epoch in range(epochs):
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
with torch.no_grad():
teacher_logits = teacher(inputs)
student_logits = student(inputs)
soft_targets = nn.functional.softmax(teacher_logits / T, dim=-1)
soft_prob = nn.functional.log_softmax(student_logits / T, dim=-1)
soft_targets_loss = -torch.sum(soft_targets * soft_prob) / soft_prob.size()[0] * (T**2)
label_loss = ce_loss(student_logits, labels)
loss = soft_target_loss_weight * soft_targets_loss + ce_loss_weight * label_loss
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}/{epochs}, Loss: {running_loss / len(train_loader)}")
# 初始化學生模型後開始訓練
nn_light = LightNN(num_classes=10).to(device)
train_knowledge_distillation(teacher=vgg, student=nn_light, train_loader=train_loader, epochs=10, learning_rate=0.001, T=2, soft_target_loss_weight=0.25, ce_loss_weight=0.75, device=device)
test_accuracy_light_ce_and_kd = test(nn_light, test_loader, device)
print(f"Teacher accuracy: {test_accuracy_deep:.2f}%")
print(f"Student accuracy with CE + KD: {test_accuracy_light_ce_and_kd:.2f}%")
train_knowledge_distillation),最後評估模型表現。from torchvision import models
from torchsummary import summary
summary(models.vgg16().to('cuda'), (3, 224, 224))
import torch
import torch.nn as nn
import torchvision.models as models
# Load a pretrained VGG16 model
vgg16 = models.vgg16(pretrained=True)
# Define the compression ratio (e.g., retain the top 50% singular values)
compression_ratio = 0.5
new_linear_layer = []
# Iterate through the layers of the model and apply SVD to weight matrices
for layer in list(vgg16.classifier):
if isinstance(layer, nn.Linear):
# Retrieve the weight tensor
weight_tensor = layer.weight.data
# Perform SVD on the weight matrix
U, S, V = torch.svd(weight_tensor, some=False)
# Calculate the number of singular values to retain
k = int(S.size(0) * compression_ratio)
# Truncate U, S, and V matrices
U = U[:, :k]
S = S[:k]
V = V.t()[:k, :]
SV = torch.mm(torch.diag(S), V)
new_linear_layer.append(nn.Sequential(
nn.Linear(SV.shape[1], SV.shape[0]),
nn.Linear(U.shape[1], U.shape[0]),
))
# Create a new model with the compressed weights
compressed_vgg16 = models.vgg16()
flag = 0
temp = 0
for layer in list(vgg16.classifier):
if isinstance(layer, nn.Linear):
compressed_vgg16.classifier[temp] = new_linear_layer[flag]
flag+=1
temp +=3
from torchsummary import summary
print(compressed_vgg16)
summary(compressed_vgg16.to('cuda'), (3, 224, 224))
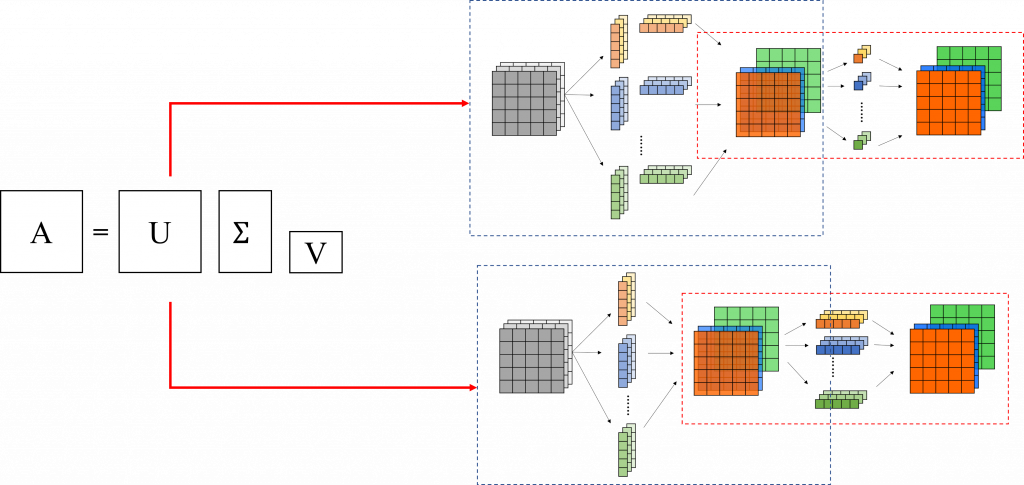
torchsummary這個工具幫我們統計模型的參數,藉此觀察壓縮前後的變化。A個輸入B個輸出的線性層的參數量是A*B,所以如果我們想要把這樣的步驟拆成兩個小的線性層的話,參數量就會是(A*k)+(k*B)=(A+B)*k,只需要稍微把數字帶入計算一下就可以知道k最多可以是多少了。import os
import torch
import torchvision
import torch_pruning as tp
def print_model_size(mdl):
torch.save(mdl.state_dict(), "tmp.pt")
print("%.2f MB" %(os.path.getsize("tmp.pt")/1e6))
os.remove('tmp.pt')
model = models.vgg16(pretrained=True)
example_inputs = torch.randn(1, 3, 224, 224)
print_model_size(model)
# 1. Importance criterion
imp = tp.importance.GroupTaylorImportance() # or GroupNormImportance(p=2), GroupHessianImportance(), etc.
# 2. Initialize a pruner with the model and the importance criterion
ignored_layers = []
for m in model.modules():
if isinstance(m, torch.nn.Linear) and m.out_features == 1000:
ignored_layers.append(m) # DO NOT prune the final classifier!
pruner = tp.pruner.MetaPruner( # We can always choose MetaPruner if sparse training is not required.
model,
example_inputs,
importance=imp,
ch_sparsity=0.5,
ignored_layers=ignored_layers,
)
# 3. Prune & finetune the model
base_macs, base_nparams = tp.utils.count_ops_and_params(model, example_inputs)
if isinstance(imp, tp.importance.GroupTaylorImportance):
loss = model(example_inputs).sum()
loss.backward() # before pruner.step()
pruner.step()
print_model_size(model)
553.44 MB # 剪枝前
142.48 MB # 剪枝後
GroupTaylorImportance),在設定剪枝工具的步驟2則是可以看到我們設定的剪枝比例是0.5。
 iThome鐵人賽
iThome鐵人賽