我們之前在討論CNN架構以及各種CNN模型的時候,有提到CNN因為幾項獨特的優勢,成為了電腦視覺或影像處理中的霸主,然而,從2017年Google提出的「Attention Is All You Need」開始,霸主寶座換人了,論文(https://arxiv.org/pdf/1706.03762.pdf)裡面介紹了一種使用注意力機制的模型架構,而這樣的架構後來被衍伸使用在影像任務上,也就是大名鼎鼎的Vision Transformer,簡稱ViT(https://arxiv.org/pdf/2010.11929v2.pdf),今天就讓我們從注意力機制開始,談談ViT是甚麼,以及現在熱門的發展趨勢:CNN與ViT的結合。

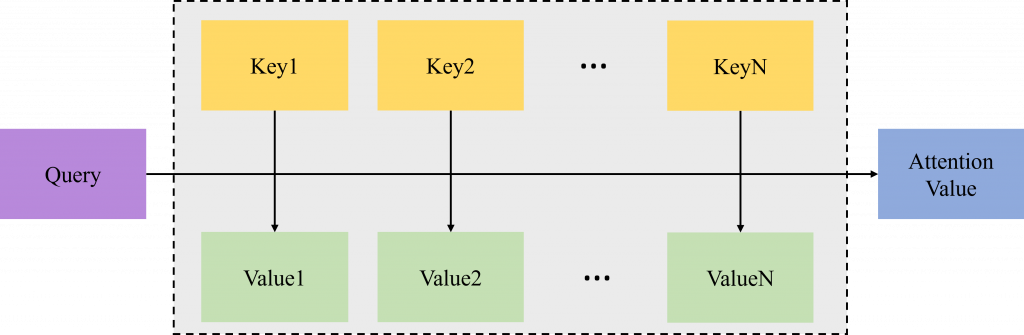
Query, Keys, Values之後,我們先計算Query與所有Key的相似度,接著將這個結果當作權重分別乘上對應的Value計算加權總合,出來的結果就是我們需要的注意力數值。先不考慮上面的Query, Keys, Values是怎麼出來的,我們來思考一下這樣的過程是甚麼意思,假設我今天去圖書館想要看跟希臘神話有關的書(Query),那麼我要怎麼找呢?圖書館都會按照書籍的種類進行分群編號,對於我想要看的書,出現在「歷史」與「西洋文學」這種類別(Key)的機率特別高,而出現在「數學」、「中國史」等類別的機率會比較低,所以我應該要在「歷史」與「西洋文學」之類的類別之下的所有書籍(Value)中找到我需要的書。這個例子中,我想要找的目標就是Query,書籍的分類或編號就是Key,而對應分類或編號下面的書就是Value(或是也可以理解成圖書館中的所有書統稱Value,但是書籍都會分類編號,所以是同個意思),為了能夠找到我想要的書,我要先確認我的目標與不同類別或編號的相似度有多高,確定好之後,我應該更加關注那些相似度高的類別下面的書籍。

Query, Keys, Values是怎麼來的,這邊我們就來談談這個問題。Query, Keys, Values都是通過某種方式,從輸入資訊本身「學」出來的。具體來說,就是我們通過模型學出三個不同的矩陣,r接著分別乘上輸入資訊之後就可以得到Query, Keys, Values。
a是由輸入訊號x經過矩陣運算後得出來的。這時候我們可以嘗試把位置資訊P疊加在x的後面看看,也就是新的x',因為訊號維度增加的關係,我們的矩陣也要跟著變大,所以我們根據P的維度建立出另一個矩陣Wp,接著與原先的矩陣W組合在一起形成新的矩陣。然後我們就會發現,新的矩陣核心的訊號x'的運算結果恰好就是a+x。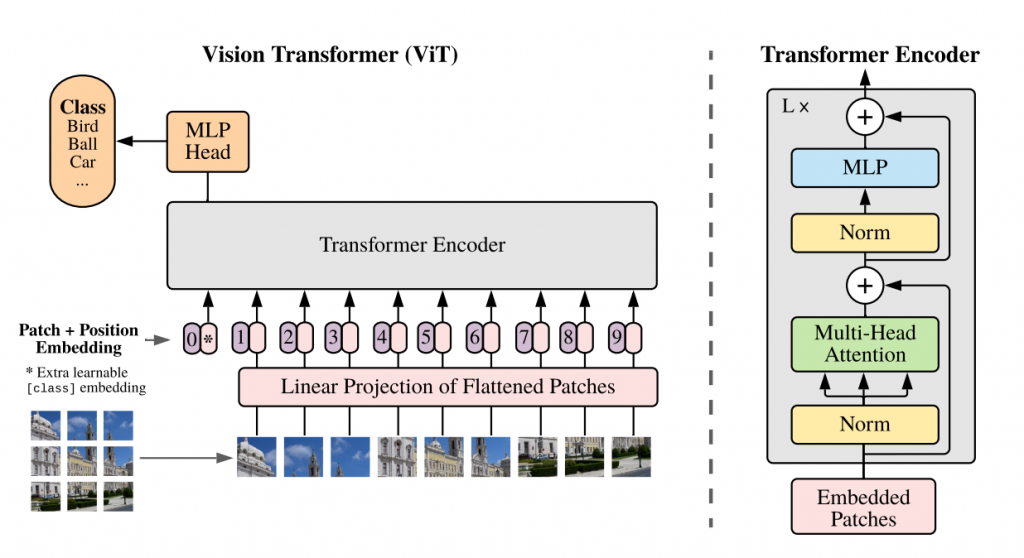
CNN擅長處理局部資訊,所以在少量數據上能有好的表現,而ViT則剛好相反,擅長提取全局的資訊,在大量數據上能夠不錯的表現,那麼為何不結合兩種方法的優點開發新的架構呢?這就是目前很熱門的研究方向,我們稍微列出幾個來介紹一下:




 iThome鐵人賽
iThome鐵人賽