把資料匯入 bigquery 是 Data Engineer 很常做的事,而很常碰到的資料來源就是 csv 檔案。
一個使用 bq command 沒有錯誤的匯入 csv 檔案到 bigquery 的語法如下
bq load --project_id {your_project} --source_format=CSV --skip_leading_rows 1
--replace
--schema {schema_path} {destination_table}
gs://{gcs_path}/{file_name}.csv
但現實不會一直很美好,不論你是用 bigquery 介面或 bq load 指令從 GCS 方式匯入,遲早會碰到幾個問題
碰到以上的問題,就需要了解 bigquery 的匯入機制及各項參數設定意思
bigquery 支援的預設 encoding 是 utf-8,另一個是拉丁語系的 ISO-8859,不是我們熟悉的 big5。所以資料匯入後若是亂碼就是 encoding 不對,要轉成 utf-8
如何解決:
# 確認檔案編碼
file -i {path}/{input_file_name}.csv # 若是 mac 要用 file -I
iconv -f {file_encoding} -t utf-8 {path}/{input_file_name}.csv > {path}/{output_file_name}.csv"
設定 schema 有幾種方式
在 —schema 後面加上每個欄位的型態
--schema=Member_ID:STRING,Line_ID:STRING,TEL:INTEGER, Birthday:DATE
若欄位太多,可以把 schema 寫在一個 json 檔中,並指定檔案連結
--schema=/tmp/table.json
格式如下範例
[
{
"name": "member_id",
"mode": "",
"type": "STRING",
"description": null,
"fields": []
},
{
"name": "line_uid",
"mode": "",
"type": "STRING",
"description": null,
"fields": []
},
{
"name": "tel",
"mode": "",
"type": "STRING",
"description": null,
"fields": []
},
{
"name": "birth",
"mode": "",
"type": "DATE",
"description": null,
"fields": []
}
]
--autodetect
不帶 schema 參數,用參數**--autodetec=true**讓 bigquery 自動偵測 CSV 的欄位型態,但除非你只是想稍微看資料懶得設定欄位,不建議用這個方式,因為基本上 bigquery 很容易偵測不是你認為的型態,他就會報錯誤
使用 GUI 匯入請參考圖片上對應下方的編號
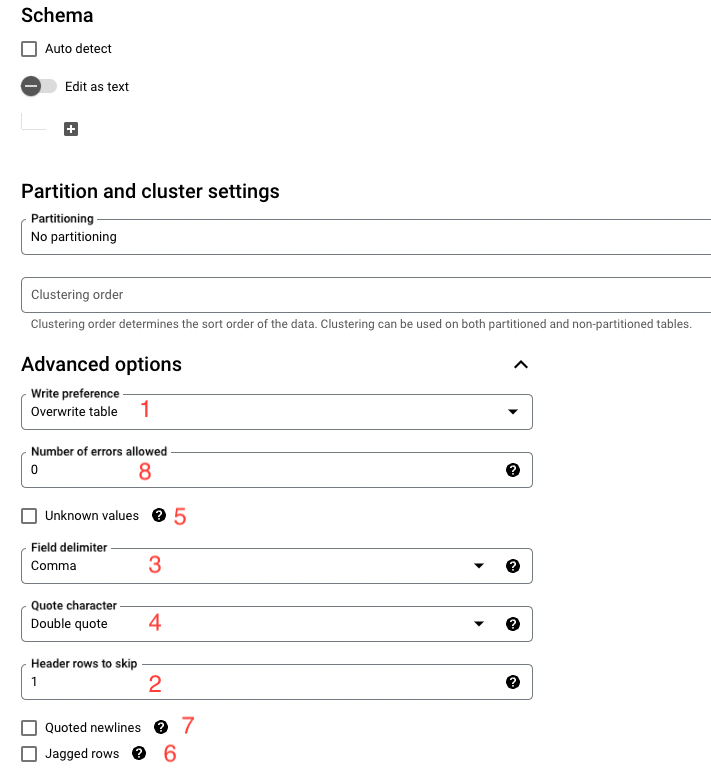
--replace
--replace 參數會覆蓋 BigQuery 表格中現有的資料。如果不指定 -replace,則 BigQuery 會將新資料新增到表格中
--skip_leading_rows
--skip_leading_rows 參數會跳過 CSV 檔案的前幾行。
如果 CSV 檔案的第一行包含欄位名稱,則可以使用此參數來跳過這些行 -skip_leading_rows 1
--field_delimiter
--field_delimiter 參數會指定 CSV 檔案中的欄位分隔符號,預設且也是最常使用的是逗點 ’,’,
如果 CSV 檔案中的欄位分隔符不是逗號,則需要使用此參數,常見的還有 pipe ‘|’, tab ‘tab’,
如果是 tab 分隔就會看到每一欄會空很大一段
--quote
--quote 參數會指定 CSV 檔案中的欄位值的引用字元,若不填的話預設是雙引號 ‘ “ ’
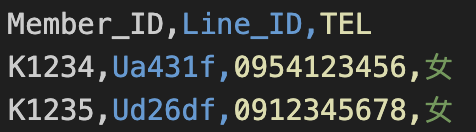
如果 CSV 檔案中的欄位值有被其他符號括起來,則需要使用此參數
為何以下參數為進階? 因為這些參數都是你資料匯入有問題時才需考慮是否要加
--ignore_unknown_values={true|false}
--ignore_unknown_values 參數會指定 BigQuery 是否忽略 CSV 檔案中無法轉換為根據 schema 對應的欄位資料。如果設定為 true,則 BigQuery 會將這些值視為空值。以下圖為例:你的 schema 指定 4 個欄位,但 CSV 檔案因為欄位的逗號分隔有4個,被判斷有5個欄位,則最後兩個欄位的資料會被視為 null
情況1: schema 設定錯誤,你設定 3欄,但資料實際上有4欄。你若使用此參數則匯入資料時不會報 error 而會忽略第4欄
情況2: schema 設定正確,但資料有錯誤
如下圖的第2列因為最後多一個逗號,若使用這個參數就不會報 error,且第2列的”女”就不會被匯入
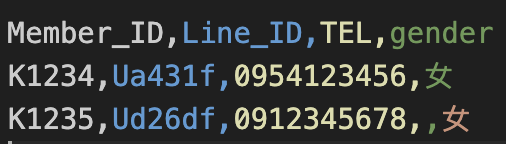
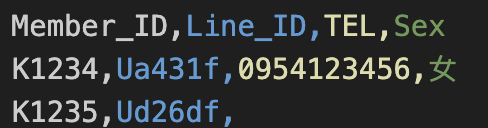
--allow_jagged_rows
-allow_jagged_rows 參數會指定 BigQuery 是否允許 CSV 檔案中缺少的欄位。如下範例:你的 schema 設定4個欄位,但第2列只有2個逗號3欄位,後面欄位消失,若加上此參數則不會報 error
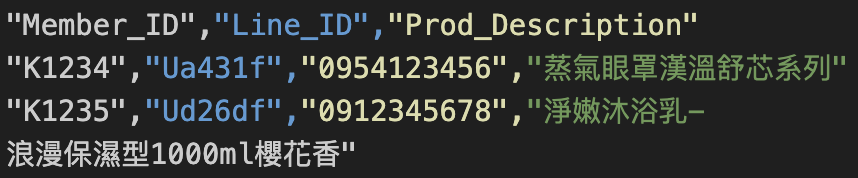
--allow_quoted_newlines
--allow_quoted_newlines 參數會允許 BigQuery 讓 CSV 檔案中的欄位值包含換行符號,如下範例,第2列的 Prod_Description 的文字有斷行符號,若沒加上**--allow_quoted_newlines** 會報 error
--max_bad_records
參數會指定 BigQuery 在匯入資料時允許的錯誤數量。如果錯誤數量超過此限制,則匯入作業將失敗。建議此參數當作無法解決資料問題的最後手段,因為它會讓你遺失錯誤資料
下一篇介紹常見的資料匯入錯誤解決步驟、用以上哪些參數解決以及匯入 CSV 的 best practice 格式

