在使用物件關聯對應(Object-Relational Mapping, ORM)工具時,對於具有關聯的物件進行批次查詢時可能出現的效能問題,像是 N+1 查詢問題(N+1 Queries Problem)。
當一個ORM查詢要求中包含多個關聯物件時,如果沒有適當處理,就可能產生 N+1 次資料庫查詢的情況。也就是說,執行一次主查詢,有 N 個查詢結果,然後針對這 N 個主查詢結果執行單獨的查詢 1 次來載入關聯物件。這種情況可能會導致大量的資料庫查詢以及額外的網絡延遲,使得應用效能下降。
以部落格應用為例,每個文章都有一個作者的關聯。當我們查詢部落格的所有文章時,如果沒有適當的處理,ORM可能會為每篇文章的作者執行單獨的查詢,這將導致 N+1 次的查詢。
在開發 GraphQL API 時,N+1 查詢問題就很容易凸顯出來。
前面 Strawberry Django 客製化查詢與 Resolvers [1] 這篇,使用strawberry_django.type來建立型態,當時覆寫了get_queryset方法,自定義 ORM 查詢:
# server/app/blog/graph/types.py
@strawberry_django.type(blog_models.Post)
class Post(relay.Node):
@classmethod
def get_queryset(
cls,
queryset: QuerySet[blog_models.Post],
info: Info,
**kwargs: typing.Any,
) -> QuerySet[blog_models.Post]:
return queryset.select_related("author").prefetch_related(
"tags",
"categories",
"comment_set",
)
使用 Django ORM QuerySet 的select_related與prefetch_related來設定需要 SQL Join 的欄位,這是開發 Django 時最常見避免 N+1 查詢問題的方法。
下面將介紹其他處理 N+1 查詢問題的方法,在開始之前我們先安裝一個更方便監看 SQL 查詢記錄的工具,下面先安裝套件:
$ poetry add django-debug-toolbar
設定 Django 設定:
# server/settings.py
# ... 省略
INSTALLED_APPS = [
"daphne",
"django.contrib.admin",
"django.contrib.auth",
"django.contrib.contenttypes",
"django.contrib.sessions",
"django.contrib.messages",
"django.contrib.staticfiles",
"django_extensions",
+ "debug_toolbar",
"strawberry_django",
"server.app.blog",
"server.app.authentication",
]
# ... 省略
MIDDLEWARE = [
"django.middleware.security.SecurityMiddleware",
"django.contrib.sessions.middleware.SessionMiddleware",
"django.middleware.common.CommonMiddleware",
"django.middleware.csrf.CsrfViewMiddleware",
"django.contrib.auth.middleware.AuthenticationMiddleware",
"django.contrib.messages.middleware.MessageMiddleware",
"django.middleware.clickjacking.XFrameOptionsMiddleware",
+ "strawberry_django.middlewares.debug_toolbar.DebugToolbarMiddleware",
]
# ... 省略
+INTERNAL_IPS = [
+ "127.0.0.1",
+ "localhost",
+]
在 Middleware 的地方使用 strawberry_django 的 Middleware [2]。
增加新的路由:
# server/urls.py
from django.contrib import admin
-from django.urls import path
+from django.urls import path, include
from strawberry.django.views import GraphQLView
from server.schema import schema
urlpatterns = [
path("admin/", admin.site.urls),
path("graphql/", GraphQLView.as_view(schema=schema)),
+ path("__debug__/", include("debug_toolbar.urls")),
]
另外 Django Debug Toolbar 不支援 Django Channels 和 Async 的程式。
接下來新增查詢使用者的所有文章功能,好讓我們呈現 N+1 查詢問題。
下面先幫文章模型的作者欄位設定關聯名稱:
# server/app/blog/models.py
# ... 省略
class Post(BaseModel):
slug = models.SlugField("網址代稱", max_length=255, unique=True)
author = models.ForeignKey(
USER_MODEL,
verbose_name="作者",
on_delete=models.CASCADE,
+ related_name="posts",
)
# ... 省略
# ... 省略
在使用者型態上加上文章列表欄位:
# server/app/authentication/graph/types.py
import typing
# ... 省略
+if typing.TYPE_CHECKING:
+ from server.app.blog.graph.types import Post
# ... 省略
@strawberry_django.type(USER_MODEL)
class User:
id: strawberry.ID # noqa: A003
username: str
first_name: str
last_name: str
email: str
+ posts: typing.List[
+ typing.Annotated[
+ "Post",
+ strawberry.lazy("server.app.blog.graph.types"),
+ ]
+ ]
is_superuser: bool = strawberry.field(default=False)
is_staff: bool = strawberry.field(default=False)
is_active: bool = strawberry.field(default=True)
然後重新整理 GraphiQL 頁面,並執行查詢:
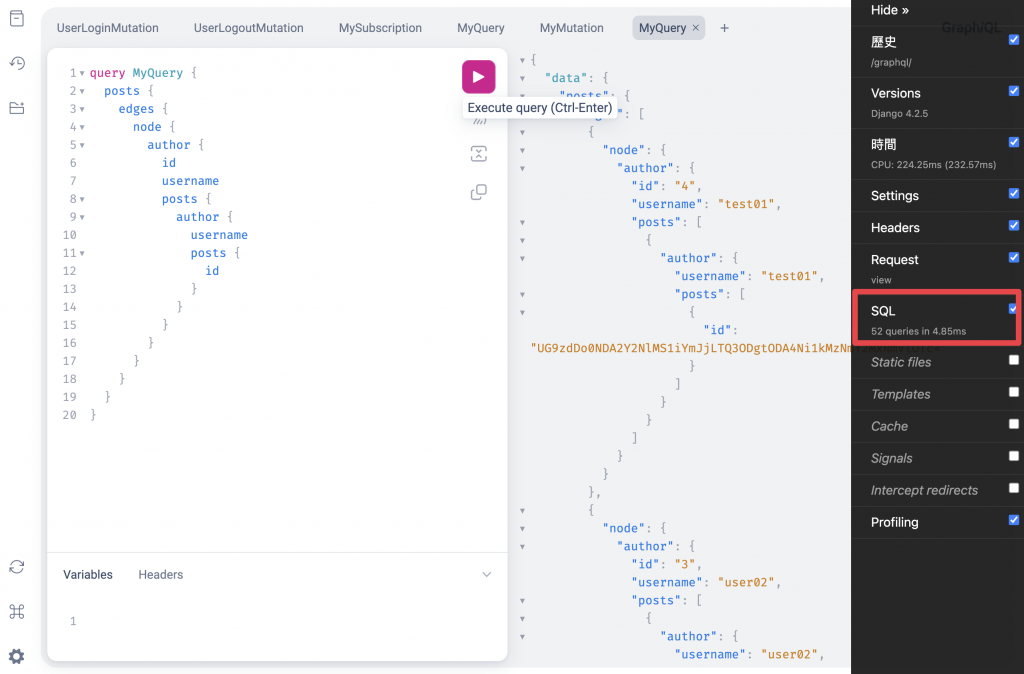
query MyQuery {
posts {
edges {
node {
author {
id
username
posts {
author {
username
posts {
id
}
}
}
}
}
}
}
}
我們執行這個複雜查詢後,可以看到 Django Debug Toolbar 上 SQL 產生了 52 次查詢。
接下來我們使用 GraphQL 官方建議的工具,DataLoader,它是一個在 GraphQL API 中處理資料加載的工具,可以幫助解決 N+1 問題,提高效能。
DataLoader 能夠將多個資料的查詢結果進行批次載入、快取與延遲載入等功能,以減少對資料庫或其他資源的重複查詢次數。
Strawberry 也有提供 DataLoader 的功能 [3],不過它只能在非同步的環境執行,為了後面能夠輕易的同步的環境下執行 DataLoader,所以這邊另外安裝一個同步程式的 DataLoader 套件:
$ poetry add graphql-sync-dataloaders
修改 Schema 的執行類別:
# server/schema.py
import strawberry
import strawberry.tools
from graphql_sync_dataloaders import DeferredExecutionContext
# ... 省略
-schema = strawberry.Schema(query=query, mutation=mutation)
schema = strawberry.Schema(
query=query,
mutation=mutation,
+ execution_context_class=DeferredExecutionContext,
)
接下來我們開始建立使用者的 DataLoader,先新增放 DataLoader 程式碼的檔案:
$ touch server/app/authentication/graph/dataloader.py
編輯dataloader.py:
import typing
from django.contrib.auth import get_user_model, models
from graphql_sync_dataloaders import SyncDataLoader
__all__ = ("user_loader",)
USER_MODEL = get_user_model()
def _load_users(keys: list[int]) -> list[models.AbstractUser]:
return typing.cast(
list[models.AbstractUser],
list(USER_MODEL.objects.prefetch_related("posts").filter(id__in=keys)),
)
user_loader = SyncDataLoader(_load_users)
這邊就只需要建立一個批次載入使用者的函式,keys一定是唯一值的列表,將函式設定到 DataLoader 中。
下面修改文章類型的作者欄位,作者的資料改從 DataLoader 中載入:
# server/app/blog/graph/types.py
# ... 省略
from server.app.authentication.graph import types as auth_types
+from server.app.authentication.graph.dataloader import user_loader
from server.app.blog import models as blog_models
from server.app.blog.graph import filters as blog_filters
from server.app.blog.graph import orders as blog_orders
# ... 省略
class Post(relay.Node):
id: relay.NodeID[uuid.UUID] # noqa: A003
slug: str
- author: auth_types.User
+ author_id: strawberry.Private[int]
# ... 省略
+ @strawberry_django.field
+ def author(self) -> auth_types.User:
+ user = user_loader.load(self.author_id)
+ return typing.cast(auth_types.User, user)
然後再執行一次查詢:
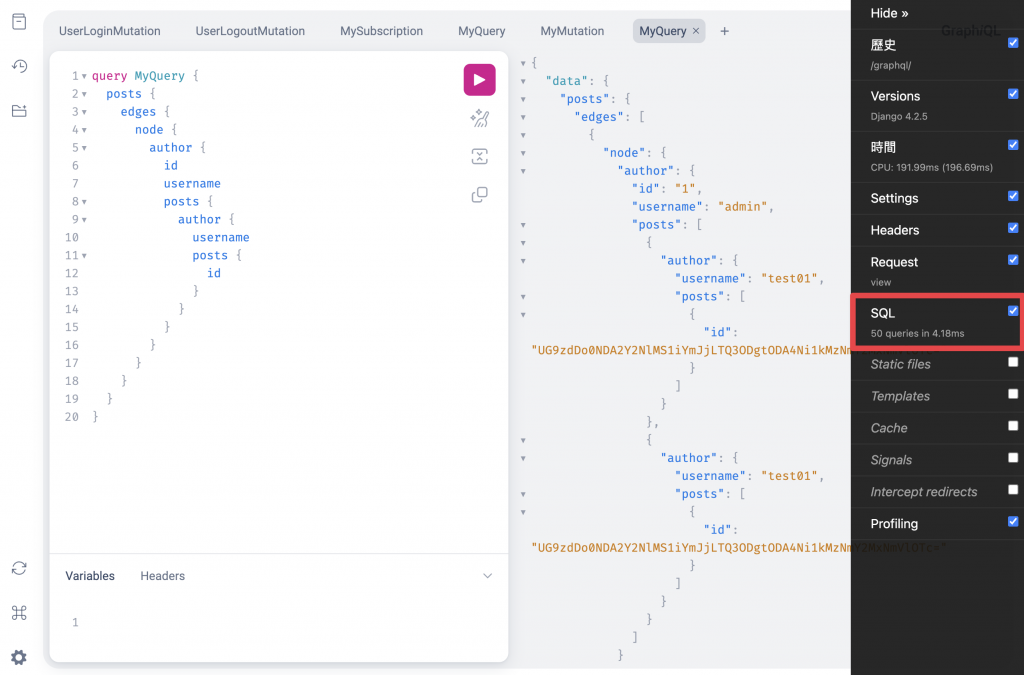
奇怪!怎麼還是這麼多次查詢,我們可以點開 Django Debug Toolbar 的 SQL 記錄,會發現重複查詢除了作者以外的關聯欄位,這是因為我們在get_queryset自定義了 ORM 查詢,那把它註解掉看看吧!
# server/app/blog/graph/types.py
# ... 省略
class Post(relay.Node):
# ... 省略
+ # @classmethod
+ # def get_queryset(
+ # cls,
+ # queryset: QuerySet[blog_models.Post],
+ # info: Info,
+ # **kwargs: typing.Any,
+ # ) -> QuerySet[blog_models.Post]:
+ # return queryset.select_related("author").prefetch_related(
+ # "tags",
+ # "categories",
+ # "comment_set",
+ # )
再執行一次查詢:
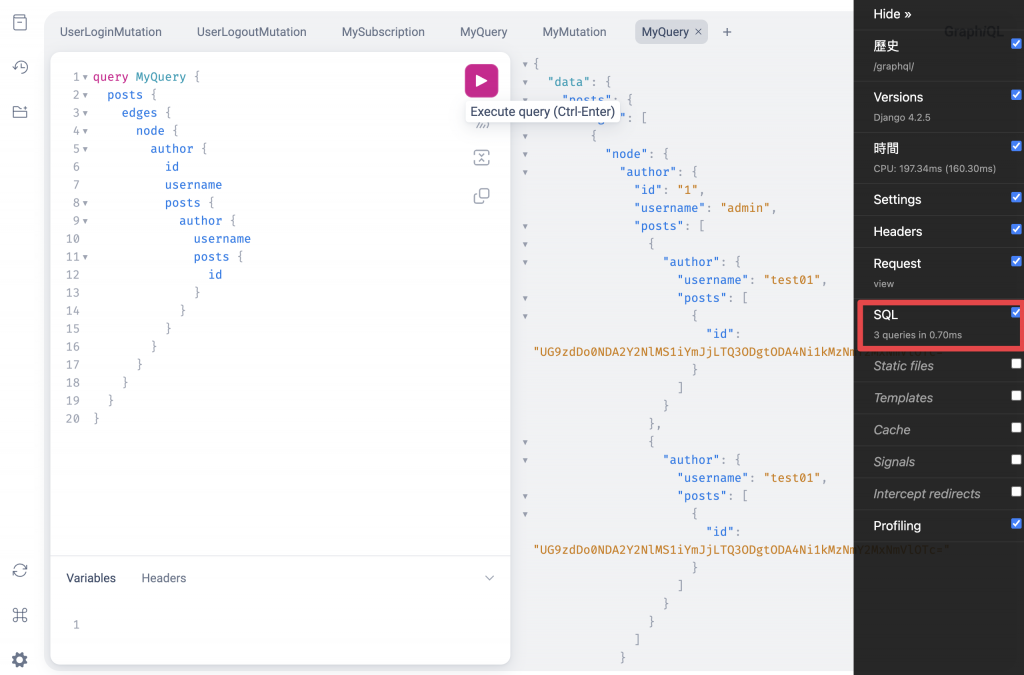
可以看到現在 SQL 剩三次了。
這個時候仔細想想,那我有一堆關聯欄位是不是只能寫一堆 DataLoader?其他的框架我不敢說,在 Django 我們還是可以使用 Django ORM QuerySet 的select_related與prefetch_related之類預載資料的方法,但是我們怎麼那些關聯欄位每次查詢都有被用到呢?每次預載一堆資料會不會很慢呢?幸好 strawberry_django 提供一個查詢優化擴充工具只要是跟 Django ORM 有關的欄位都可以自動判斷預載 ORM 查詢。
前面我們所做的練習都是圍繞在 Django ORM 模型上,所以我們可以全部改成 strawberry_django 的型態與欄位,不需要使用 DataLoader。
下面我們設定 strawberry_django 的查詢優化擴充工具,以及修改那些另外寫的關聯欄位的查詢:
# server/schema.py
import strawberry
import strawberry.tools
from graphql_sync_dataloaders import DeferredExecutionContext
+from strawberry_django.optimizer import DjangoOptimizerExtension
# ... 省略
schema = strawberry.Schema(
query=query,
mutation=mutation,
execution_context_class=DeferredExecutionContext,
+ extensions=[DjangoOptimizerExtension],
)
# ... 省略
設定留言的文章欄位的關聯名稱:
# server/app/blog/models.py
# ... 省略
class Comment(BaseModel):
post = models.ForeignKey(
Post,
verbose_name="文章",
on_delete=models.CASCADE,
+ related_name="comments",
)
# ... 省略
# ... 省略
# server/app/blog/graph/types.py
# ... 省略
class Post(relay.Node):
id: relay.NodeID[uuid.UUID] # noqa: A003
slug: str
- author_id: strawberry.Private[int]
+ author: auth_types.User
# ... 省略
+ comments: list["Comment"]
# ... 省略
- @strawberry_django.field
- def author(self) -> auth_types.User:
- user = user_loader.load(self.author_id)
- return typing.cast(auth_types.User, user)
- @strawberry_django.field
- def comments(self) -> list["Comment"]:
- return self.comment_set.all() # type: ignore
+ # @strawberry_django.field
+ # def comments(self) -> list["Comment"]:
+ # return self.comment_set.all() # type: ignore
下面執行查詢:
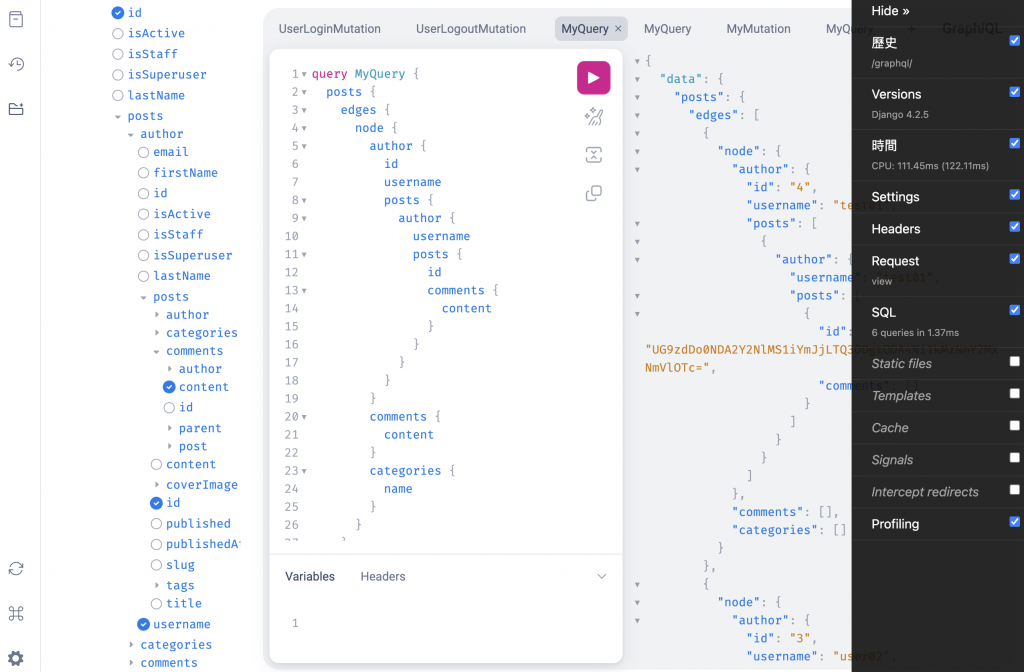
query MyQuery {
posts {
edges {
node {
author {
id
username
posts {
author {
username
posts {
id
comments {
content
}
}
}
}
}
comments {
content
}
categories {
name
}
}
}
}
}
我們可以打開 Django Debug Toolbar 的 SQL 記錄,會看到幫我們處理好 ORM 查詢預載。
這次修改內容可以參考 Git commit:

