今天就要來進入這個專案啦
這邊先付上這個github專案的網址:
https://github.com/Plachtaa/VITS-fast-fine-tuning/tree/main
還有這個專案的作者大佬:
https://github.com/Plachtaa
那就開始操作專案啦
點進來專案後,首先先去看README file,有中英文版兩個檔案,裡面其實就會直接開始教你使用這個專案了。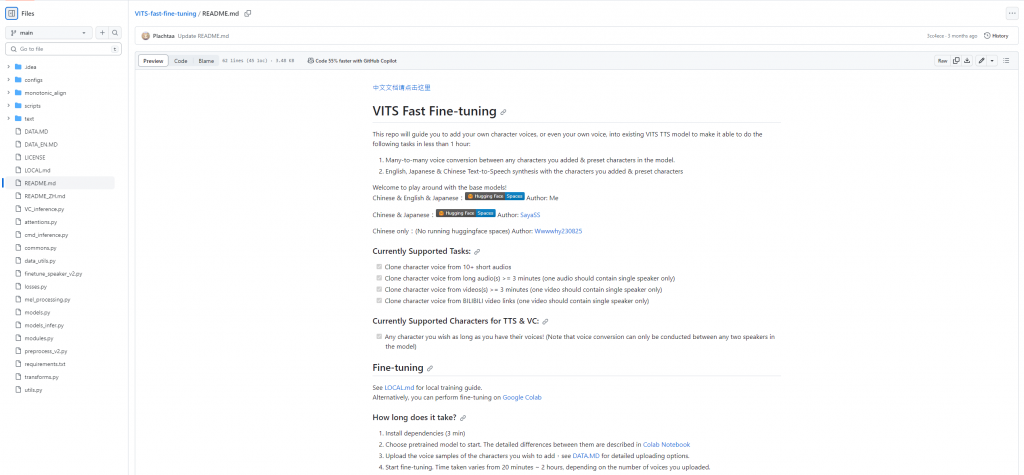
裡面介紹到目前有三種base models可以選擇,不過目前只支援中英日三種語言。
接下來就是選擇你運行這個專案的地方啦,可以選擇在自己本地的環境運行,也可以在Google Colab上直接運行。我這邊原本想嘗試在自己本地環境嘗試看看,畢竟前面都把環境架起來了,不過他要求環境的python版本和CUDA版本又是不一樣的,絕對是要在建一個環境,還需要安裝非常多套件、輔助數據,和預訓練模型,十分麻煩,而且建環境的過程中絕對不會那麼的順利,簡直是吃力不討好,因此我最後決定直接在Colab上運行!(假如你想在local執行的話,作者也有提供一個文件檔教你大概的流程)
在Colab上執行的話,作者這邊有直接提供一個ipynb檔,連結點進去整個專案就都在裡面,而且還有簡單的教學,超級讚!
另外專案內還有一個叫做DATA的文檔,裡面是在跟你講你自己準備的訓練資料集應該要是什麼格式、音訊長度、檔案的結構等等。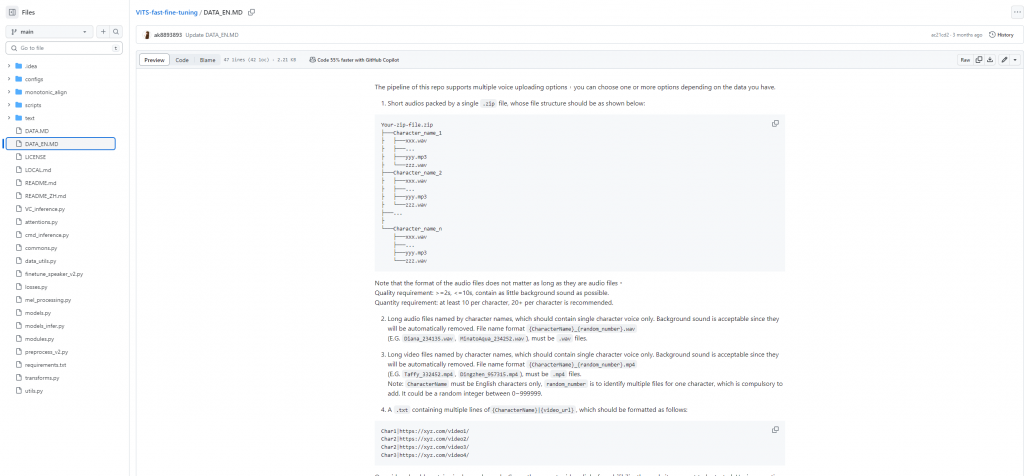
在進入colab之前,我會先簡單了解整個專案的資料夾,程式碼檔案等等,畢竟大佬的專案手刻不出來,多少還是要理解一下的。
configs/modified_finetune_speaker.json
configs/uma_trilingual.json
設定模型語音生成相關參數和相關配置。像是eval_interval: 控制每多少個訓練步驟執行一次模型評估、epochs: 訓練的總時期數、segment_size: 用於訓練的音訊片段大小、max_wav_value: 音訊數值的最大值 等等。
這兩個檔案應該都是語音生成的參數配置,我自己判斷差別應該是一個是只針對中文的,而第二個則是中英日三種語言的。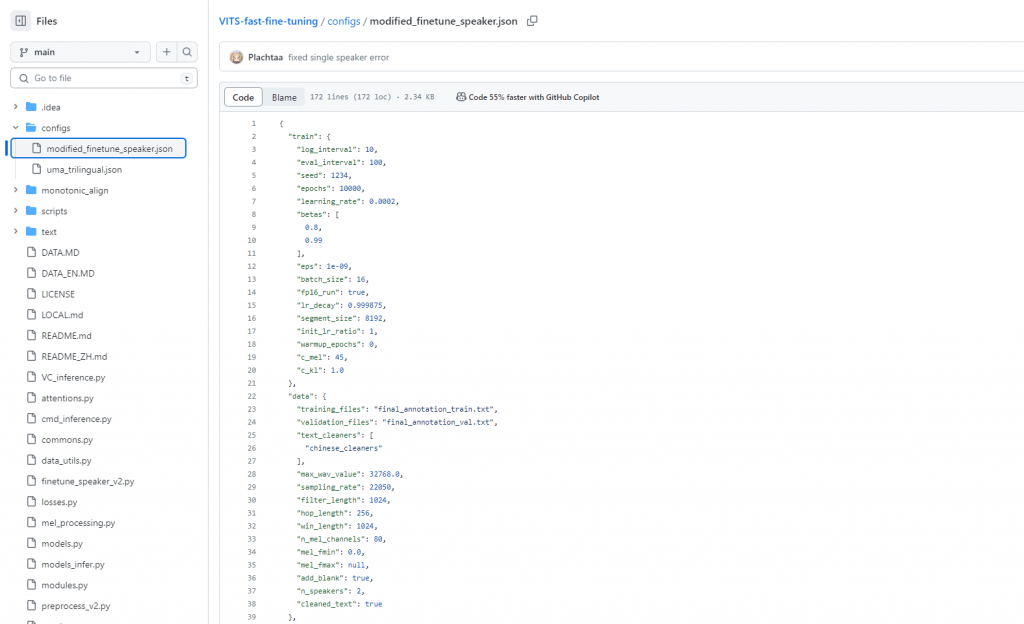
接下來的篇幅會將剩下的部分都理解一遍,就會開始執行專案訓練模型啦


 iThome鐵人賽
iThome鐵人賽