
今天最後一天就要來實做這個語音訓練的模型啦!
一樣先放上專案連結:https://github.com/Plachtaa/VITS-fast-fine-tuning
以及作者連結:https://github.com/Plachtaa
在開始訓練之前,我們要先準備訓練用的資料集,也就是一些訓練用的音檔,這邊就要回去看一下專案裡寫的檔案格式的規範
若是短音訊的話長度要在2-10秒,且一個模型(角色)至少要十個檔案,效果要比較好要二十個以上。且要裝在以角色名稱為名的資料夾裡壓縮成ZIP檔。
長音訊的話長度要在20分鐘內,不然可能會爆內存,命名格式須為{CharacterName}_{random_number}.wav, 且檔案格式要式WAV檔。
我這邊打算用短音訊來做資料集,短音訊的格式是不限制的,我的資料夾大概是長這樣!
之後再把他壓成zip就好
首先直接執行Step1,等它複製專案及安裝下載一下環境套件等等。可能需要一小段時間。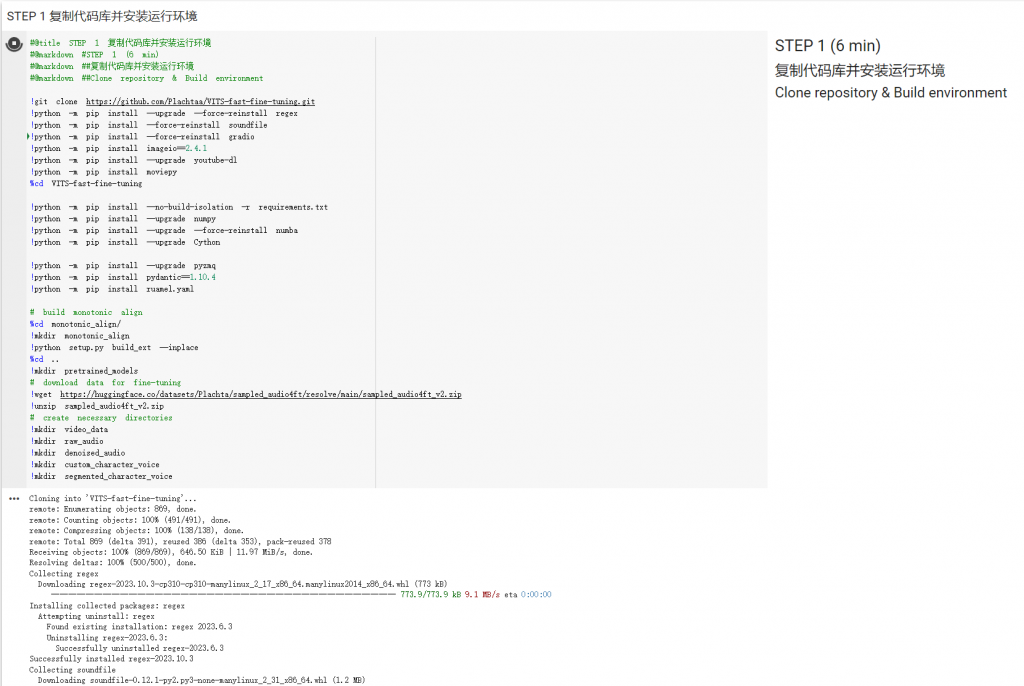
然後繼續到Step1.5 選擇語言模型,也就是前面講過的三種語言,我是只有用到中文,所以就直接用預設的CJ,不動她。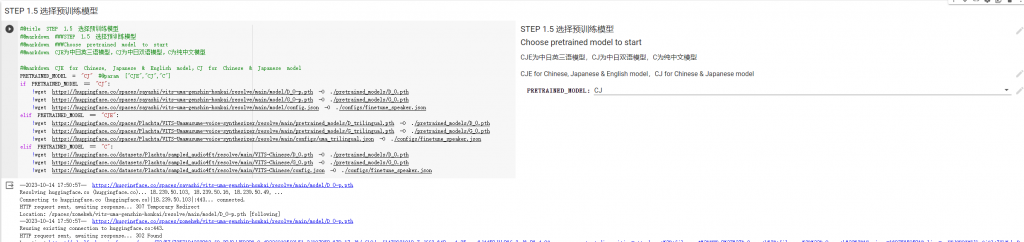
接著step2到了上傳你的訓練資料集的時候了,這邊可以根據你準備的資料集形式選擇執行列,像我的就是短音訊,而且我直接用google drive連接上傳,所以選擇2.1的第二個執行列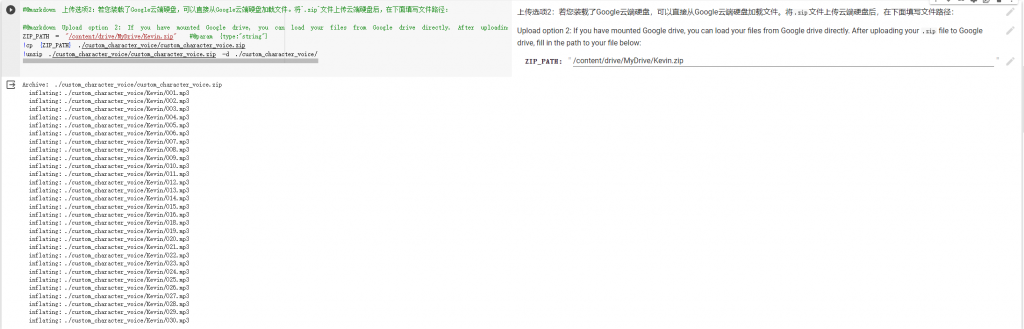
接著step3會將上傳的檔案進行預處理,像是去躁、採樣率等等。這邊也會把你的音檔轉成文本喔,假如你認為文本有錯在這邊要進行修改。我自己是覺得很準啦。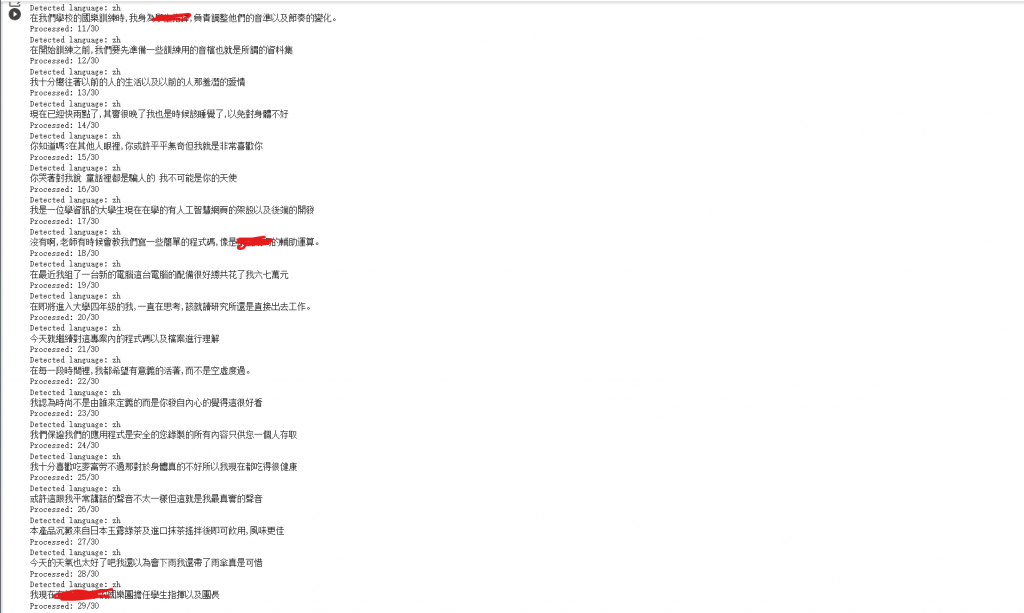
繼續執行Step3.5這邊就是訓練前的一些調整,這邊可以勾選作者推薦的一個輔助訓練的數據,就依條件看你認為要不要勾。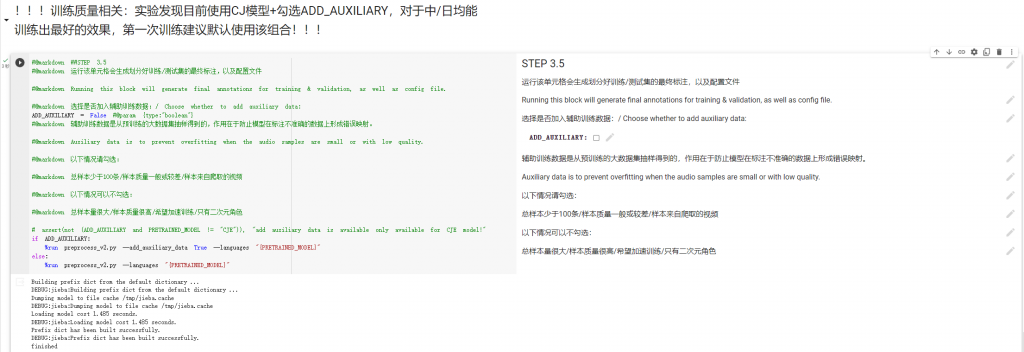
Step4就是訓練模型啦,這邊可以調整訓練的epoch,我自己是寫100,但其實不用到100效果就很不錯了,在訓練時,底下還會生成一個tensorboard讓你可以試聽效果怎麼樣,你認為可以的話其實就可以停了。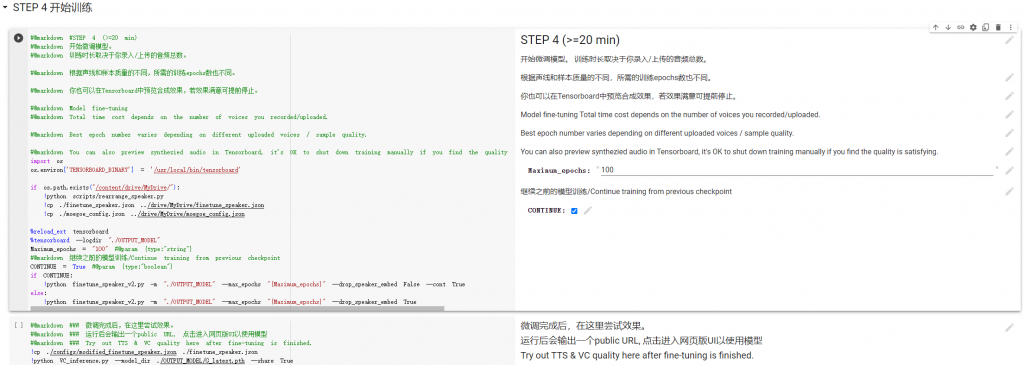
最後step5就是下載模型啦,下載完後找到G_latest.pth和finetune_speaker.json兩個檔案就是你的模型了!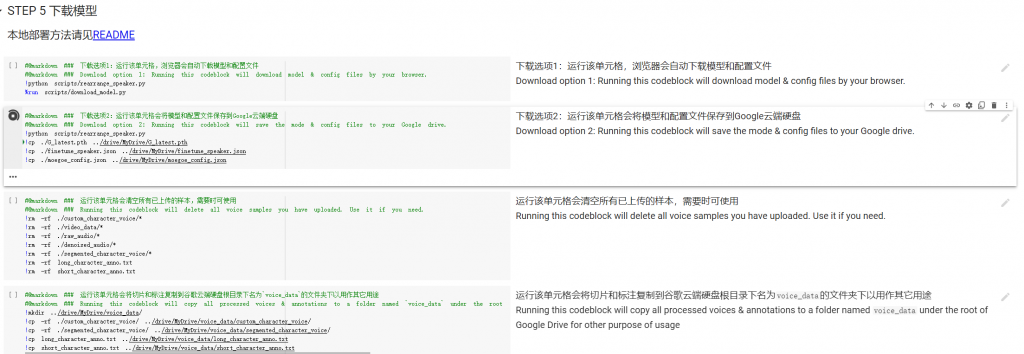
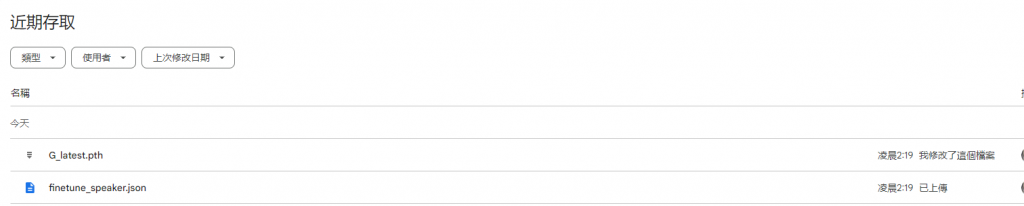
想要直接在本地執行這個模型的話,就去這個專題的release那邊下載inference,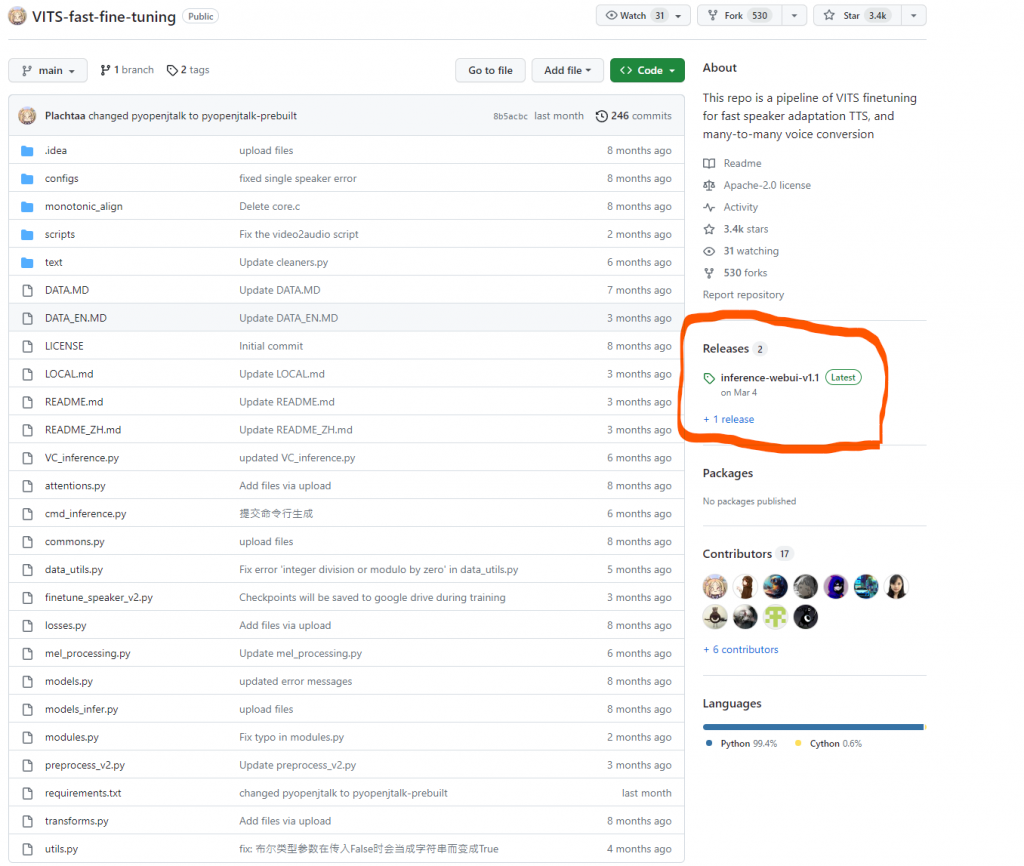
之後將這包解壓縮,在將G_latest.pth和finetune_speaker.json丟進去資料夾裡,然後執行資料夾裡的inference,等他跑出一個網頁,就可以玩你的模型了!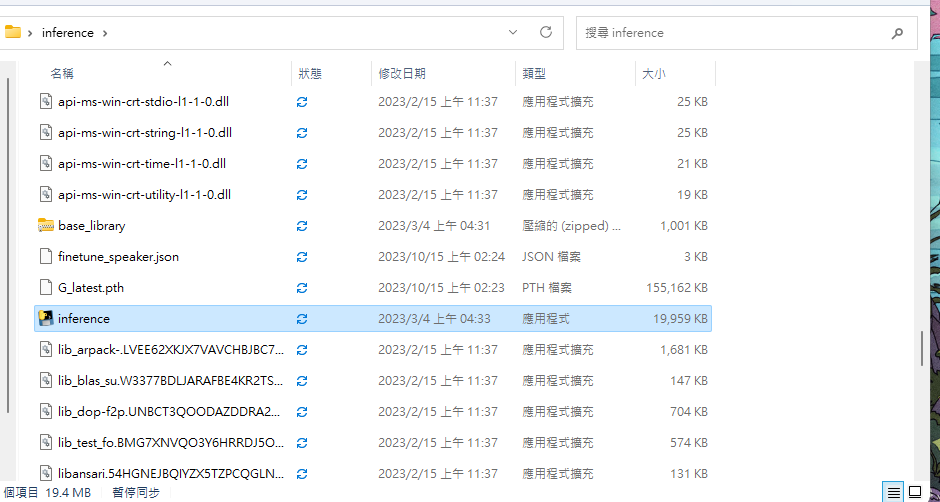
這樣就可以玩啦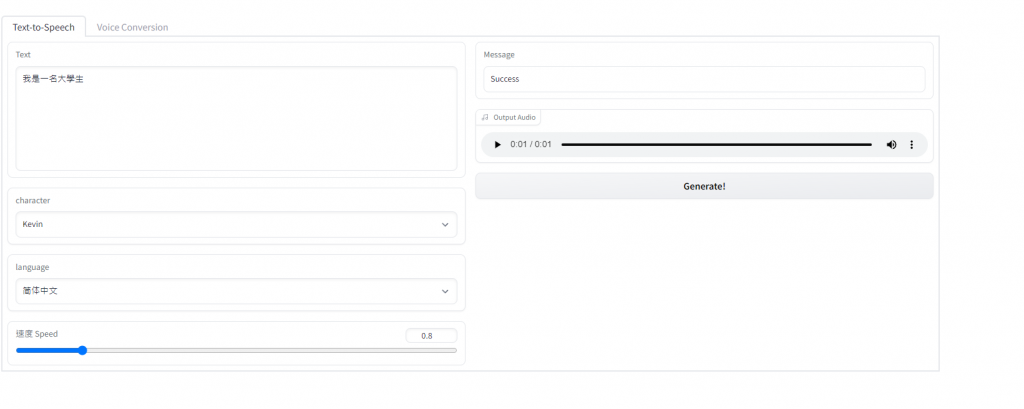
VITS語音模型專題實作就到這邊結束~
最後這邊想講一下這三十天鐵人一路寫過來的心得,講實話三十天不短,也沒長到哪裡去,但這一個月若是有好好的學習,不僅能夠學到豐富的東西,更是養成了自主學習的習慣,讓大腦習慣每天的去接收新知識,我認為這是無比珍貴的。
總之,這個鐵人賽的經驗確實很特別,在這次完賽後,我也會盡量保持每天的自主學習,去嘗試新東西。並在明年再次參加這個鐵人賽!

 iThome鐵人賽
iThome鐵人賽