
今天要繼續講解前一篇未講完的CNN網路的程式碼
一樣先把完整的程式碼貼上來
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1)).astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1)).astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5, batch_size=64, validation_data=(test_images, test_labels))
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(f'Test accuracy: {test_acc}')
上一篇講到模型內層的建置,今天從模型的編譯開始講~
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
在編譯模型時,我們需要先設定三個值,分別是優化器、損失函數、和評估模型的標準。
optimizer(優化器) 是模型在訓練過程中使用的優化算法。優化器的作用是最小化或最大化損失函數,從而使模型的預測更接近實際值。
損失函數(Loss Function) 是深度學習模型中的一個重要組件,他衡量了模型預測的輸出與實際目標的差異,用來衡量模型在訓練過程中的性能。優化器的目標就是最小化損失函數的值,使得模型的預測盡可能接近實際目標。
接著就開始講解程式碼
// optimizer='adam': 指定了優化器的類型,使用 Adam 優化器。Adam 是一種常用的自適應學習率優化算法,能夠有效地調整每個權重的學習率,進而加速收斂過程。Adam 優化器是深度學習中的一個常見選擇,通常能夠在不同類型的任務中表現良好。
//loss='categorical_crossentropy' : 指定了損失函數的類型,使用了 categorical crossentropy。對於多類別分類問題,特別是使用 softmax 激活函數的情況,categorical crossentropy 是一個常見的選擇。它衡量模型預測的概率分佈與實際標籤的差異,並將這個差異作為訓練過程中的損失。
在多類別分類的情況中,常使用 softmax 激活函數來產生每個類別的概率分佈。softmax 函數將模型的輸出轉換成一個概率分佈,使所有類別的概率總和為 1。而 categorical crossentropy 正是針對這種概率分佈設計的損失函數,可以很好的衡量預測概率分佈與實際標籤的差異。
categorical crossentropy 能夠處理多類別分類的問題,並對每個類別進行區分。對於每個樣本,損失函數計算模型預測的概率分佈與實際的 one-hot 編碼標籤之間的差異。
// metrics=['accuracy'] : 在訓練時,我們通常會follow一些指標來評估模型的性能。這裡使用 accuracy 作為評估指標,就是模型在訓練集上的準確率。
model.fit(train_images, train_labels, epochs=5, batch_size=64, validation_data=(test_images, test_labels))
這裡使用 Keras 中的 fit 方法,這個方法可以訓練(fit)模型。一樣需要設定一些參數。
// epochs: ,模型訓練的次數。每一次 epoch 模型就會完整經歷一次訓練數據集。這個值通常是整數。
// batch_size: 每次更新模型權重所使用的樣本數。在每個 epoch 中,數據集將被分為多個批次,每個批次包含指定數量的樣本。
// 用於在訓練過程中評估模型性能的驗證數據。這是一個元組,裡面要放驗證數據的輸入特徵和對應的標籤(test images and labels)。每個 epoch 結束時,模型根據這些數據的性能進行評估。
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(f'Test accuracy: {test_acc}')
// evaluate 方法的return值是一個包含兩個值的元組,第一個值是測試數據上的損失(test loss),第二個值是模型在測試數據上的指定評估指標(這裡是準確度,test accuracy)。
請注意,這邊的test_acc和前面的accuracy是不一樣的!
test_acc是在模型訓練結束後,使用測試數據集計算的準確度。這個值用於評估模型對於未見過的數據(測試數據)的泛化性能。
accuracy是在模型訓練過程中,使用訓練數據集計算的準確度。這個值用於監控模型在訓練過程中對訓練數據的擬合程度。
//最後print就是將test_acc給印出來啦
以下是程式碼截圖和執行終端結果
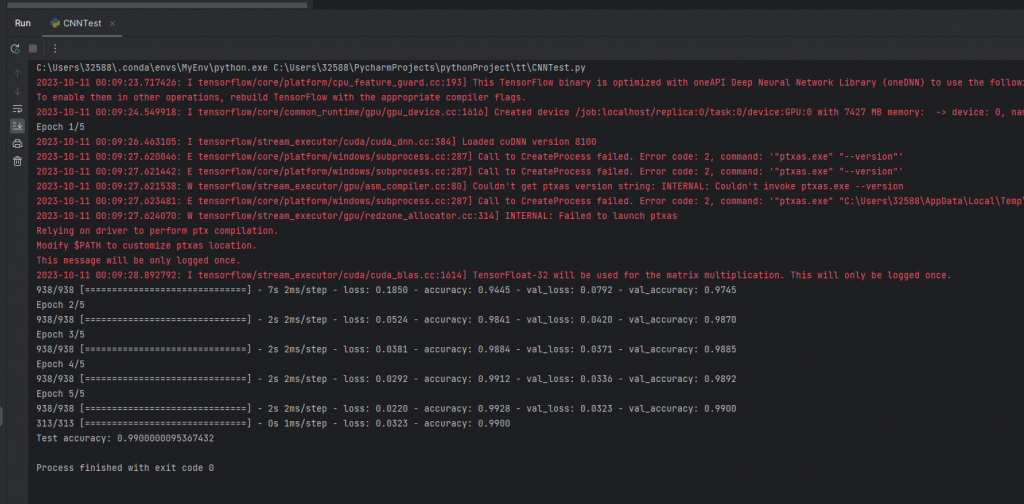
這邊前面import出現了幾個errors,我自己猜可能是因為新版本中, Keras 已經被整合到 TensorFlow 中。或者是PyCharm沒有讀到我的環境中有tensorflow keras,因為程式碼其實是可以順利執行的!
至於執行完終端的應該紅字是在講一些CUDA和cuDNN某個函數的小問題,不過執行這種很簡單的cnn網路基本上是不會有什麼影響的!
那這個辨識手寫數字的簡單cnn網路就告一段落~

 iThome鐵人賽
iThome鐵人賽