在上一篇當中,ChatGPT提及SQL的入門學習項目中
除了基礎的SQL語法之外,還有以下這幾點是在上一篇沒有討論的
OK! 這一篇就一起來一個一個探討了解!聽聽ChatGPT怎麼介紹這些主題
另外因為各家SQL語言還是有些微差距,所以這篇會以MySQL為主
Go Go!

當然可以!我來詳細介紹一下 SQL 中的資料型態,並且針對 MySQL 中常用的資料型態提供列舉和範例。
1. 資料型態是什麼?
在資料庫中,資料型態決定了可以存儲的資料的類型和範圍。每個資料型態都有特定的特性,例如整數、浮點數、文字等。
2. MySQL 常用的資料型態
整數型態
TINYINT - 1 個位元組,範圍是 -128 到 127(無符號為 0 到 255)。
CREATE TABLE example ( id TINYINT, ... );SMALLINT - 2 個位元組,範圍是 -32,768 到 32,767(無符號為 0 到 65,535)。
CREATE TABLE example ( id SMALLINT, ... );INT - 4 個位元組,範圍是 -2,147,483,648 到 2,147,483,647(無符號為 0 到 4,294,967,295)。
CREATE TABLE example ( id INT, ... );BIGINT - 8 個位元組,範圍是 -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807(無符號為 0 到 18,446,744,073,709,551,615)。
CREATE TABLE example ( id BIGINT, ... );浮點數型態
FLOAT(M,D) - 單精度浮點數,M 是總位數,D 是小數位數。
CREATE TABLE example ( price FLOAT(8,2), ... );DOUBLE(M,D) - 雙精度浮點數,M 是總位數,D 是小數位數。
CREATE TABLE example ( price DOUBLE(16,4), ... );字符型態
CHAR(N) - 固定長度字串,N 是字符數量,範圍是 0 到 255。
CREATE TABLE example ( name CHAR(50), ... );VARCHAR(N) - 可變長度字串,N 是最大字符數量,範圍是 0 到 65,535。
CREATE TABLE example ( description VARCHAR(255), ... );日期和時間型態
DATE - 日期,格式為 'YYYY-MM-DD'。
CREATE TABLE example ( dob DATE, ... );TIME - 時間,格式為 'HH:MM:SS'。
CREATE TABLE example ( checkin_time TIME, ... );DATETIME - 日期和時間,格式為 'YYYY-MM-DD HH:MM:SS'。
CREATE TABLE example ( created_at DATETIME, ... );3. 範例
以一個簡單的表格來展示:
CREATE TABLE users ( id INT PRIMARY KEY, username VARCHAR(30), email VARCHAR(50), birthdate DATE );這個表格名為
users,包括了id(整數型態)、username(可變長度字串)、birthdate(日期型態)。希望這份介紹對你有所幫助!如果有任何疑問,隨時提問。

是的,MySQL 還有一些其他的資料型態,讓我們繼續介紹:
1. 列舉型態(ENUM)
列舉型態允許你在一個特定的範圍中選擇一個值。你可以使用列舉型態來限制一個欄位只能接受特定的值之一。
CREATE TABLE example ( status ENUM('active', 'inactive', 'pending'), ... );2. 集合型態(SET)
集合型態類似於列舉型態,但它可以接受多個值。
CREATE TABLE example ( options SET('option1', 'option2', 'option3'), ... );3. 二進制型態(BLOB)
BLOB 用於存儲二進制數據,例如圖像或多媒體文件。
CREATE TABLE example ( image BLOB, ... );4. 文字型態(TEXT)
文字型態用於存儲長度可變的文本數據,有四種變體:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT,分別表示不同範圍的文本長度。
CREATE TABLE example ( description TEXT, ... );5. 日期和時間型態的變體
除了前面提到的 DATE、TIME 和 DATETIME,還有以下變體:
- TIMESTAMP - 日期和時間,受到時區影響。
- YEAR - 年份,可以是 2 位或 4 位數字。
CREATE TABLE example ( last_updated TIMESTAMP, release_year YEAR(4), ... );這些是一些常用的 MySQL 資料型態以及它們的一些變體。如果你需要進一步的資訊或有任何疑問,請隨時告訴我!

好的,讓我來為你介紹一些常用的 MySQL 內建函數,並附上相應的範例和執行結果。
1. 字串函數
CONCAT()將多個字串連接在一起。
範例:
SELECT CONCAT('Hello', ' ', 'World') AS Result;
| Result |
|---|
| Hello World |
LENGTH()取得字串的長度。
範例:
SELECT LENGTH('MySQL') AS Length;
| Length |
|---|
| 5 |
2. 數值函數
ROUND()對數值進行四捨五入。
範例:
SELECT ROUND(3.14159, 2) AS RoundedNumber;
| RoundedNumber |
|---|
| 3.14 |
ABS()取得數值的絕對值。
範例:
SELECT ABS(-10) AS AbsoluteValue;
| AbsoluteValue |
|---|
| 10 |
3. 日期和時間函數
NOW()取得當前日期和時間。
範例:
SELECT NOW() AS CurrentDateTime;
| CurrentDateTime |
|---|
| 2023-10-20 14:30:15 |
DATE_FORMAT()格式化日期和時間。
範例:
SELECT DATE_FORMAT(NOW(), '%Y-%m-%d') AS FormattedDate;
| FormattedDate |
|---|
| 2023-10-20 |
這些是一些常用的 MySQL 內建函數以及相應的範例和執行結果。如果你對特定函數或其他相關函數有任何疑問,請隨時告訴我!

當然!還有許多其他常用的 MySQL 內建函數,以下是一些例子:
4. 數學函數
SUM()計算數值的總和。
範例:
SELECT SUM(salary) AS TotalSalary FROM employees;
| TotalSalary |
|---|
| 50000 |
AVG()計算數值的平均值。
範例:
SELECT AVG(age) AS AverageAge FROM users;
| AverageAge |
|---|
| 30.5 |
5. 條件函數
IF()根據條件返回不同的值。
範例:
SELECT name, IF(score >= 60, 'Pass', 'Fail') AS Result FROM students;
| name | Result |
|---|---|
| Alice | Pass |
| Bob | Fail |
| Carol | Pass |
CASE更通用的條件判斷函數,可以處理多個條件。
範例:
SELECT name, CASE WHEN score >= 90 THEN 'A' WHEN score >= 80 THEN 'B' WHEN score >= 70 THEN 'C' ELSE 'D' END AS Grade FROM students;
| name | Grade |
|---|---|
| Alice | A |
| Bob | C |
| Carol | B |
6. 聚合函數
COUNT()計算符合條件的行數。
範例:
SELECT COUNT(*) AS TotalUsers FROM users;
| TotalUsers |
|---|
| 100 |
這些是另外一些常用的 MySQL 內建函數以及相對應的範例和執行結果。如果你對特定函數或其他相關函數有任何疑問,請隨時告訴我!
比貪心還要更貪心
當然!還有許多其他有用的 MySQL 內建函數,以下是一些例子:
7. 字串函數
UPPER()將字串轉換為大寫。
範例:
SELECT UPPER('hello') AS UppercaseString;
| UppercaseString |
|---|
| HELLO |
LOWER()將字串轉換為小寫。
範例:
SELECT LOWER('WORLD') AS LowercaseString;
| LowercaseString |
|---|
| world |
SUBSTRING()取得字串的子串。
範例:
SELECT SUBSTRING('Hello World', 7, 5) AS SubstringResult;
| SubstringResult |
|---|
| World |
8. 日期和時間函數
DATEDIFF()計算兩個日期之間的差異。
範例:
SELECT DATEDIFF('2023-10-20', '2023-10-15') AS DateDifference;
| DateDifference |
|---|
| 5 |
DATE_ADD()將指定的時間增加到日期或時間中。
範例:
SELECT DATE_ADD('2023-10-20', INTERVAL 7 DAY) AS NewDate;
| NewDate |
|---|
| 2023-10-27 |
9. 進階函數
COALESCE()返回第一個非 NULL 值。
範例:
SELECT COALESCE(NULL, 'Hello', 'World') AS Result;
| Result |
|---|
| Hello |
IFNULL()如果第一個參數為 NULL,返回第二個參數。
範例:
SELECT IFNULL(NULL, 'Not Null Value') AS Result;
| Result |
|---|
| Not Null Value |
這些是更多常用的 MySQL 內建函數以及相對應的範例和執行結果。如果你對特定函數或其他相關函數有任何疑問,請隨時告訴我!

當然!讓我為你詳細介紹
GROUP BY和HAVING的語法,並附上相應的範例和說明。GROUP BY
GROUP BY是一個 SQL 指令,用於對結果進行分組。通常會配合聚合函數(如COUNT()、SUM())使用,以便對每個分組應用函數。語法:
SELECT column_name(s), aggregate_function(column_name) FROM table_name GROUP BY column_name(s);範例:
假設我們有一個
orders表格,其中包含了product_id和quantity兩個欄位:
| order_id | product_id | quantity |
|---|---|---|
| 1 | 101 | 5 |
| 2 | 102 | 3 |
| 3 | 101 | 2 |
| 4 | 102 | 7 |
| 5 | 101 | 4 |
現在,如果我們想計算每個產品的銷售總量,可以使用
GROUP BY:SELECT product_id, SUM(quantity) AS total_quantity FROM orders GROUP BY product_id;這會得到:
| product_id | total_quantity |
|---|---|
| 101 | 11 |
| 102 | 10 |
HAVING
HAVING子句允許你在GROUP BY後進一步過濾結果集。語法:
SELECT column_name(s), aggregate_function(column_name) FROM table_name GROUP BY column_name(s) HAVING condition;範例:
假設我們希望僅顯示銷售總量大於 10 的產品,可以使用
HAVING:SELECT product_id, SUM(quantity) AS total_quantity FROM orders GROUP BY product_id HAVING total_quantity > 10;這會得到:
| product_id | total_quantity |
|---|---|
| 101 | 11 |
在這個範例中,只有產品 101 的銷售總量超過 10,因此它符合
HAVING條件。總結來說,
GROUP BY用於對結果進行分組,而HAVING用於在分組後進一步過濾結果。如果你對這兩個語法或範例有任何疑問,請隨時告訴我!

當然!讓我為你詳細介紹 SQL 中的子查詢(也稱為內部查詢)以及如何使用它們。
什麼是子查詢?
子查詢是一個 SQL 查詢嵌套在另一個查詢中的查詢。它允許你在一個查詢的
WHERE、FROM或HAVING子句中使用另一個查詢的結果。基本語法:
SELECT column_name(s) FROM table_name WHERE column_name OPERATOR (SELECT column_name(s) FROM table_name WHERE condition);在上述語法中,子查詢的結果將作為外部查詢的條件之一。
範例:
假設我們有兩個表格:
students和grades:
students表格:
| student_id | name |
|---|---|
| 1 | Alice |
| 2 | Bob |
| 3 | Carol |
grades表格:
| student_id | grade |
|---|---|
| 1 | A |
| 2 | B |
| 3 | C |
如果我們想找到得到 A 等級的學生,可以使用子查詢:
SELECT name FROM students WHERE student_id IN (SELECT student_id FROM grades WHERE grade = 'A');這將返回:
| name |
|---|
| Alice |
子查詢的種類
- 單行子查詢:返回單一值,通常與單一行比較。
- 多行子查詢:返回多行結果,通常與多行比較。
- 標量子查詢:返回單一值,可以用於任何需要單一值的地方。
- 相關子查詢:使用外部查詢的資料作為內部查詢的條件。
- 存在子查詢:檢查內部查詢是否返回了任何結果。
範例:
1. 單行子查詢
SELECT name FROM students WHERE student_id = (SELECT MAX(student_id) FROM students);2. 多行子查詢
SELECT name FROM students WHERE student_id IN (SELECT student_id FROM grades WHERE grade = 'A');3. 標量子查詢
SELECT name, (SELECT grade FROM grades WHERE student_id = s.student_id) AS grade FROM students s;4. 相關子查詢
SELECT name FROM students s WHERE EXISTS (SELECT 1 FROM grades WHERE student_id = s.student_id AND grade = 'A');5. 存在子查詢
SELECT name FROM students WHERE EXISTS (SELECT 1 FROM grades WHERE student_id = students.student_id);這些範例展示了不同種類的子查詢以及如何在 SQL 中使用它們。如果你對特定類型的子查詢或相關概念有任何疑問,請隨時告訴我!

當然!讓我為你詳細介紹 MySQL 中的 JOIN 操作,並提供相應的範例以及創建初始表格的查詢語法。
什麼是 JOIN?
在 SQL 中,JOIN 用於將兩個或多個表格的行結合在一起,基於它們之間的關聯。這使得我們可以從多個表格中擷取相關聯的數據。
常見的 JOIN 類型:
- INNER JOIN:返回兩個表格中符合條件的匹配行。
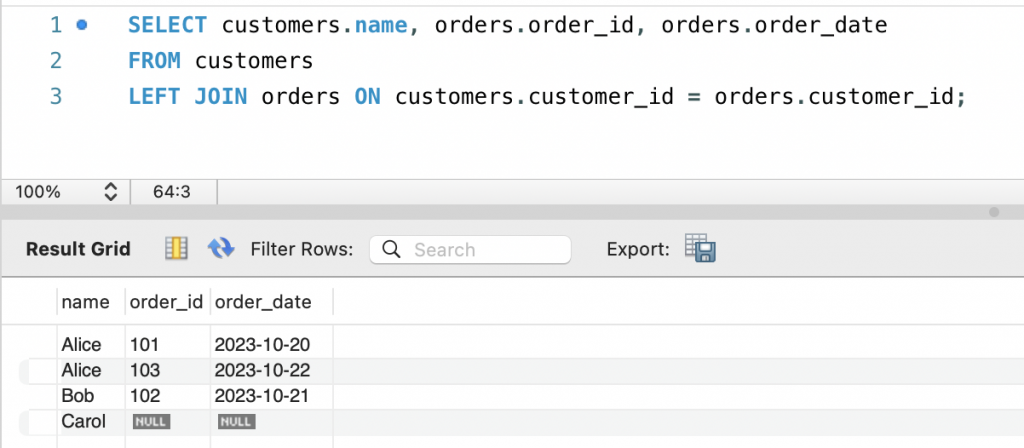
- LEFT JOIN (或 LEFT OUTER JOIN):返回左表格中的所有行,以及右表格中符合條件的匹配行。如果右表格中沒有匹配的行,則結果中會包含 NULL 值。
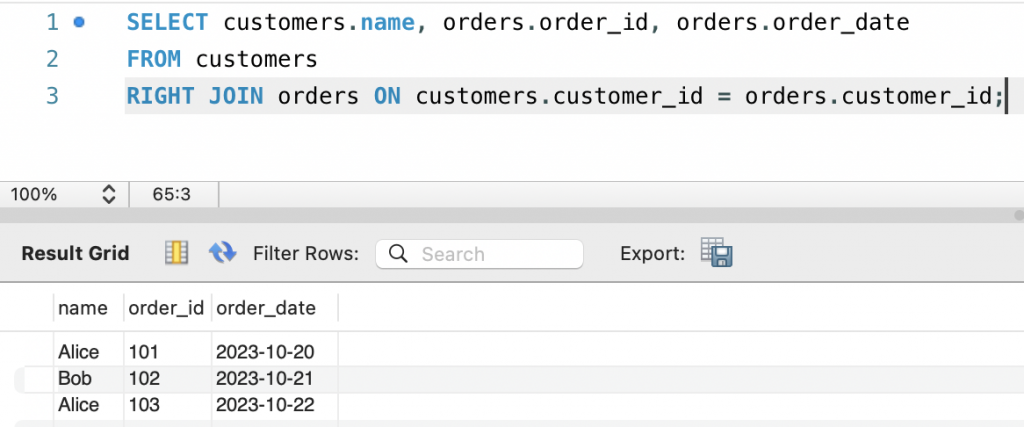
- RIGHT JOIN (或 RIGHT OUTER JOIN):返回右表格中的所有行,以及左表格中符合條件的匹配行。如果左表格中沒有匹配的行,則結果中會包含 NULL 值。
- FULL JOIN (或 FULL OUTER JOIN):返回兩個表格中的所有行,並在必要時使用 NULL 值填充未匹配的行。
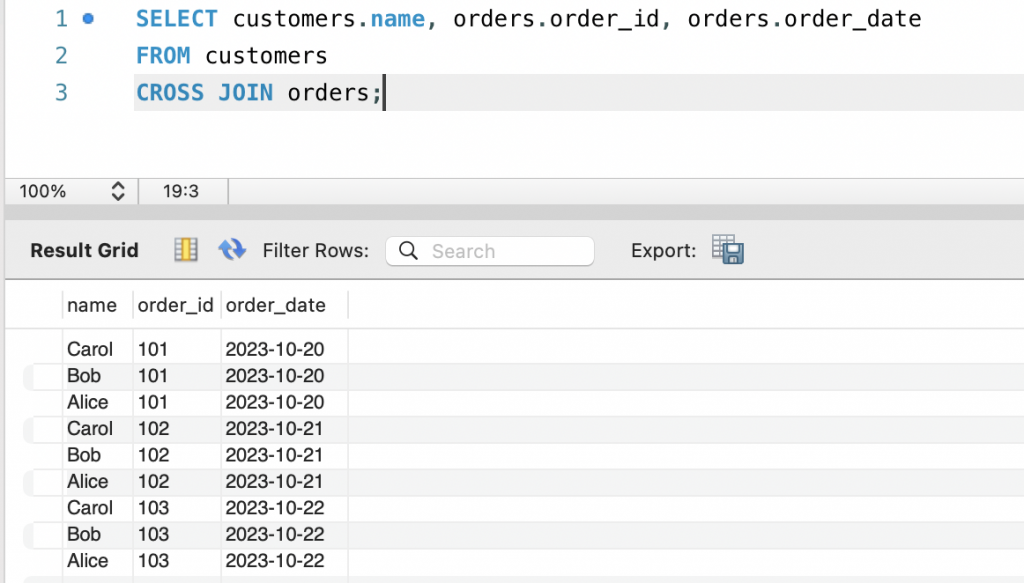
- CROSS JOIN:返回兩個表格的笛卡爾積,即左表格的每一行都與右表格的每一行組合在一起。
創建表格的查詢語法:
假設我們想要創建兩個表格:
customers和orders。-- 創建 customers 表格 CREATE TABLE customers ( customer_id INT PRIMARY KEY, name VARCHAR(50) ); -- 插入一些示例數據 INSERT INTO customers (customer_id, name) VALUES (1, 'Alice'), (2, 'Bob'), (3, 'Carol'); -- 創建 orders 表格 CREATE TABLE orders ( order_id INT PRIMARY KEY, customer_id INT, order_date DATE, total_amount DECIMAL(10,2), FOREIGN KEY (customer_id) REFERENCES customers(customer_id) ); -- 插入一些示例數據 INSERT INTO orders (order_id, customer_id, order_date, total_amount) VALUES (101, 1, '2023-10-20', 100.00), (102, 2, '2023-10-21', 150.50), (103, 1, '2023-10-22', 75.25);JOIN 的範例:
INNER JOIN
SELECT customers.name, orders.order_id, orders.order_date FROM customers INNER JOIN orders ON customers.customer_id = orders.customer_id;LEFT JOIN
SELECT customers.name, orders.order_id, orders.order_date FROM customers LEFT JOIN orders ON customers.customer_id = orders.customer_id;RIGHT JOIN
SELECT customers.name, orders.order_id, orders.order_date FROM customers RIGHT JOIN orders ON customers.customer_id = orders.customer_id;FULL JOIN
SELECT customers.name, orders.order_id, orders.order_date FROM customers FULL JOIN orders ON customers.customer_id = orders.customer_id;CROSS JOIN
SELECT customers.name, orders.order_id, orders.order_date FROM customers CROSS JOIN orders;這些範例展示了不同種類的 JOIN 操作以及相應的 SQL 查詢語法。如果你對特定類型的 JOIN 或相關概念有任何疑問,請隨時告訴我!
上面的範例裡面FULL JOIN的例子是錯的,mysql遇到「FULL JOIN」會跑出錯誤訊息
除此之外的話,都可以順利執行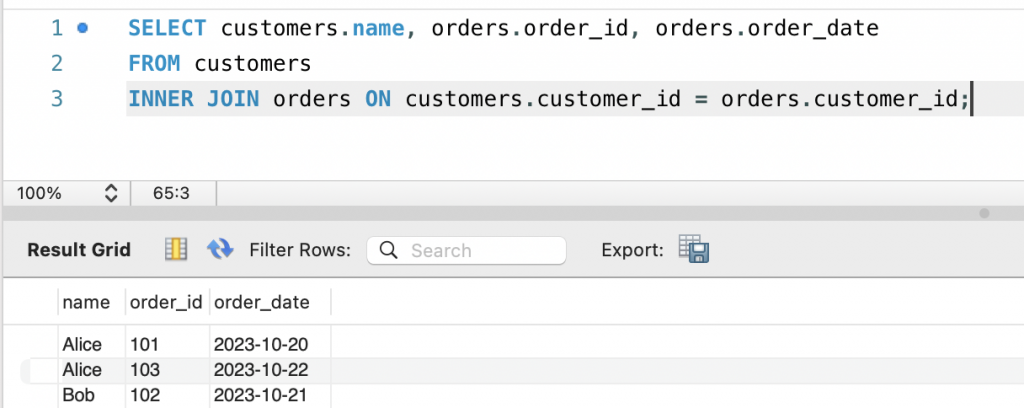
跟ChatGPT反應一下有關FULL JOIN的語法問題
對不起,我的錯誤。MySQL 不支援
FULL JOIN的語法。謝謝你的提醒。如果你需要獲得兩個表格中的所有數據,可以使用
LEFT JOIN和RIGHT JOIN的組合,然後使用UNION將它們聯合起來。以下是一個示例:
SELECT customers.name, orders.order_id, orders.order_date FROM customers LEFT JOIN orders ON customers.customer_id = orders.customer_id UNION SELECT customers.name, orders.order_id, orders.order_date FROM customers RIGHT JOIN orders ON customers.customer_id = orders.customer_id;這將獲得兩個表格中的所有行,並將它們聯合起來。
再次感謝你的提醒,如果你有任何其他問題或需要進一步的幫助,請隨時告訴我。
OK知錯能改,讚讚

當然!索引在資料庫中起著重要的作用,它可以提升查詢效能並加快數據的檢索速度。以下是有關索引的詳細介紹和教學:
什麼是索引?
在資料庫中,索引是一種特殊的數據結構,它可以加速查詢和檢索數據的速度。索引通常是一個獨立的數據結構,與表格相關聯,允許直接訪問數據,而無需進行全表掃描。
為什麼需要使用索引?
- 提升查詢效能:通過使用索引,查詢可以更快速地定位到需要的數據,而無需進行全表掃描。
- 加速數據檢索:對於大型表格或包含大量數據的表格,索引可以顯著減少檢索所需的時間。
- 加速數據排序和分組:對於包含 ORDER BY 或 GROUP BY 子句的查詢,索引可以提升排序和分組的效能。
- 提升多表格連接的效能:當進行多表格 JOIN 操作時,索引可以提升連接的效能。
如何創建索引?
在創建表格時,你可以在特定欄位上創建索引,這將加快對這些欄位的查詢效能。以下是創建索引的基本語法:
CREATE INDEX index_name ON table_name (column1, column2, ...);例如,假設我們有一個名為
users的表格,我們想要在username欄位上創建一個索引:CREATE INDEX username_index ON users (username);如何使用索引?
當你執行一個查詢時,資料庫系統會試圖使用索引來優化查詢。你無需手動指定索引,資料庫會根據查詢的條件和索引的可用性來自動選擇適當的索引。
然而,請注意,過多或不必要的索引可能會導致效能下降,因此在創建索引之前,應該仔細考慮哪些欄位最需要索引。
如何刪除索引?
你可以使用
DROP INDEX來刪除已經存在的索引:DROP INDEX index_name ON table_name;例如,如果我們要刪除先前創建的
username_index:DROP INDEX username_index ON users;這將刪除
users表格上的username索引。總結來說,索引是資料庫中一個重要的工具,可以提升查詢效能和數據檢索速度。然而,適當地使用索引非常重要,過多或不必要的索引可能會導致效能下降。因此,在創建索引之前,應該仔細考慮哪些欄位最需要索引。如果你有任何進一步的問題或需要協助,請隨時告訴我!
ChatGPT只說了要考慮哪些欄位要,但沒有明確講述說判斷與考慮基準是什麼
索引的作用是加速查詢,它實現這個目的的原理和概念如下:
原理和概念:
- 數據結構:索引是一種特殊的數據結構,通常是 B-樹或哈希表,它以某種方式存儲了特定欄位的值和指向相應行的位置。
- 減少查詢成本:當你執行一個查詢時,如果表格沒有索引,數據庫系統可能需要進行全表掃描,逐行檢查以找到符合條件的數據。但如果表格有了索引,數據庫可以使用索引直接定位到符合條件的數據,這樣可以大大減少查詢的成本。
- 提升數據檢索速度:索引使得數據庫可以更快速地定位到需要的數據行,而不是進行全表搜索,這在大型表格中特別重要。
判斷要添加哪些索引:
選擇要添加索引的欄位是一個重要的決策,需要根據實際情況和查詢模式進行評估。以下是一些指導原則:
- 頻繁用於查詢的欄位:如果一個欄位經常用於查詢條件,那麼在這個欄位上添加索引是有意義的。
- JOIN 操作的關聯欄位:在進行 JOIN 操作時,通常需要在連接的欄位上創建索引,這樣可以提升連接的效能。
- 排序和分組欄位:如果你經常使用 ORDER BY 或 GROUP BY 子句,則在這些欄位上添加索引可以提升排序和分組的效能。
- 小表格:對於小型表格,索引的影響可能不如對於大型表格顯著,因此在小型表格上添加索引的必要性可能較低。
- 避免過度索引:過多或不必要的索引可能會導致效能下降,因為每個索引都需要維護並佔用額外的存儲空間。因此,在添加索引之前,應該仔細考慮哪些欄位最需要索引。
總結來說,索引的作用是加速查詢,通過使用特殊的數據結構來儲存和定位數據,以減少查詢的成本。選擇要添加索引的欄位應根據實際情況和查詢模式進行評估,並避免過度索引。如果你需要進一步的幫助或有其他問題,請隨時告訴我!

索引可以大幅提升查詢效能,但並非所有的查詢都能充分受益於索引。以下是一些情況下索引可能不適用或效果有限的情況:
- 低基数欄位:當一個欄位的基數(唯一值的數量)非常低時,索引的效果可能有限。例如,一個只有兩種值的布爾欄位。
- 全表掃描:當需要檢索大部分或全部表格的數據時,索引可能不會提升效能,因為數據庫系統會選擇進行全表掃描。
- LIKE 操作中的模糊搜索:在
LIKE操作中使用通配符(例如%pattern%)可能會降低索引效能,因為這需要在索引中進行額外的模式匹配。- 頻繁的更新、刪除操作:如果一個表格經常被更新或刪除,那麼索引的維護成本可能會超過了查詢效能的提升。
- 小表格:對於小型表格,索引的影響可能不如對於大型表格顯著。
- 低選擇性的索引:如果一個索引對大部分數據返回的行數相對較高,那麼效能提升可能有限。
- 大量的 NULL 值:如果一個欄位包含大量的 NULL 值,則在這個欄位上添加索引可能無法提升效能。
- JOIN 操作中未使用索引的連接條件:如果在 JOIN 操作中未使用索引的連接條件,則索引可能無法發揮作用。
總的來說,儘管索引可以大幅提升查詢效能,但在某些情況下可能會導致效能下降或無法提升效能。因此,在添加索引之前,應該仔細考慮哪些查詢將受益於索引,並避免不必要的索引。如果你對特定情況或查詢的適用性有任何疑問,請隨時告訴我!

當然!索引是一個相當廣泛的主題,還有許多進階或細節的內容可以探討:
- 複合索引:可以在多個欄位上創建一個索引,稱為複合索引。這種索引可用於查詢需要條件涵蓋多個欄位的情況。
- 覆蓋索引:當一個查詢只需要從索引中獲取信息而不需要訪問實際表格時,稱為覆蓋索引。這可以減少訪問磁盤的次數,提升效能。
- 最左前綴原則:對於複合索引,可以根據最左前綴原則來使用索引,這意味著查詢必須使用索引的最左側欄位來保證索引的使用。
- B-樹和哈希索引:除了常見的 B-樹索引外,還有哈希索引可以用於某些特定的查詢。
- 索引的選擇性:索引的選擇性是指索引中唯一值的比例。高選擇性的索引通常效能較好。
- 索引的優化和維護:當表格發生變動(如插入、更新、刪除操作)時,索引需要進行相應的優化和維護工作,這可能會對寫入效能造成一定的影響。
- 索引的大小和存儲:索引需要占用一定的存儲空間,因此在設計表格時需要考慮索引的大小。
- 索引的類型和用途:每種類型的索引(如普通索引、唯一索引、全文索引等)都有特定的用途,應根據情況選擇適當的索引類型。
- 分區索引:對於非常大的表格,可以將其分為多個區段,並在每個區段上創建索引,以提升效能。
- 索引和優化器:優化器是負責選擇最有效的查詢執行計劃的組件,它會根據查詢條件和可用的索引選擇最佳的執行方式。
這些都是與索引相關的進階或細節內容。如果你對其中的任何一個主題感興趣,或者有任何具體的問題,請隨時告訴我!

除了基礎的 SQL 語法和索引相關的內容,還有許多進階主題可以學習,這些主題可以讓你更深入地理解和應用 SQL:
- 視圖 (Views): 學習如何創建、使用和管理視圖。視圖可以簡化複雜的查詢,並提供一個虛擬的表格。
- 存儲過程 (Stored Procedures): 學習如何創建、執行和管理存儲過程。存儲過程是預先編譯的 SQL 語句,可以被多次調用,提供了更高的效能和安全性。
- 觸發器 (Triggers): 了解觸發器的概念和使用方法。觸發器是一種在特定事件發生時自動執行的程式。
- 資料庫設計 (Database Design): 學習如何設計正規化的資料庫結構,以確保數據的一致性和有效性。
- 索引優化 (Index Optimization): 進一步學習如何設計和優化索引,以提升查詢效能。
- 窗口函數 (Window Functions): 了解窗口函數的概念,這些函數可以在結果集中的一部分執行計算。
- 通用表格運算式 (Common Table Expressions, CTEs): 學習如何使用 CTEs 來創建可重複使用的查詢片段,提高查詢的可讀性和維護性。
- 遞歸查詢 (Recursive Queries): 了解如何在 SQL 中進行遞歸查詢,這對於處理具有階層結構的數據非常有用。
- 分析函數 (Analytic Functions): 學習如何使用分析函數來進行複雜的數據分析和報表生成。
- 大數據和分佈式查詢:了解如何在大數據環境中使用 SQL,包括分佈式資料庫和相關工具。
這些是 SQL 中的一些進階主題,可以讓你更全面地應用 SQL 於實際情境中。根據你的興趣和需要,你可以選擇深入研究其中的一個或多個主題。如果你對特定主題或相關問題有任何疑問,請隨時告訴我!

綜合以上所有內容,我們可以得出以下 SQL 的重點:
- 基礎 SQL 語法:包括
SELECT、INSERT、UPDATE、DELETE等基本操作,以及條件和運算符的使用。- 資料型態:了解不同資料型態的特性,如整數、浮點數、字串等,以及如何使用它們。
- 索引:索引是用於提升查詢效能的關鍵工具,可以加速數據的檢索速度,需要根據情況選擇適當的欄位創建索引。
- JOIN 操作:用於將多個表格的資料結合在一起,根據相應的關聯條件進行匹配。
- 函數:包括聚合函數(如
SUM、COUNT)、數學函數、日期函數等,可以進行數據的運算和處理。- 子查詢:允許在一個查詢中嵌套另一個查詢,用於處理較為複雜的查詢邏輯。
- GROUP BY 和 HAVING:用於對數據進行分組和篩選,常與聚合函數一起使用。
- 視圖、存儲過程、觸發器:這些是進階的 SQL 功能,可以提高數據管理和處理的效率和靈活性。
- 索引優化、窗口函數、通用表格運算式:進一步優化查詢和數據處理的方式,提升效能。
- 資料庫設計、分析函數、遞歸查詢、大數據處理:更高階的主題,可以應用於複雜的數據處理場景。
結語:
透過這些 SQL 的核心概念和進階主題,你可以建立強大的數據操作和查詢能力,並有效地管理和處理數據。記得在實際應用中,適當地使用這些技巧將對你的工作產生重大的影響。持續學習並實踐,將讓你成為一名優秀的資料專家或開發者。如果你有任何進一步的問題或需要幫助,隨時歡迎向我詢問!
本次對話記錄在這裡:
https://chat.openai.com/share/866334c2-9179-4dc2-a881-b8fd7fd4acc6
我自己本身在工作上有在使用MySQL和MSSQL
兩者之間有些語法一樣是不太一樣的,像是.. now() 或是字串處理上?
我比較熟悉mysql語法,所以也蠻常拿mysql語法問ChatGPT如果要轉換成MSSQL的話要怎麼寫
資料庫這門學問也是又廣又深
我們這邊就基礎的探討相關query語法,還有簡單的理解索引與效能之間的關係
對跨後端的前端工程師來說就相當夠用了
下一篇!nvm!管理NodeJS版本與環境!
我是熟悉MySQL語法的前端工程師一宵三筵,我們明天見!

