接著改到 colab 上測試,colab 預設就裝了 google-generativeai。
一樣把 key 跟模型設定好,這次改用輕量快速的 gemini-1.5-flash
import google.generativeai as genai
genai.configure(api_key='自己的 API key')
model = genai.GenerativeModel('gemini-1.5-flash')
先測測讀音檔。
先下載兩個 google 提供的範例。指令前記的加上驚嘆號,代表此行是 command。
!wget -O sample.mp3 https://storage.googleapis.com/generativeai-downloads/data/State_of_the_Union_Address_30_January_1961.mp3
!wget -O samplesmall.mp3 https://storage.googleapis.com/generativeai-downloads/data/Apollo-11_Day-01-Highlights-10s.mp3
把音檔讀近來測試看看。
audio_file = genai.upload_file(path='sample.mp3')
response = model.generate_content(['用繁體中文總結這個音檔的內容', audio_file])
print(response.text)
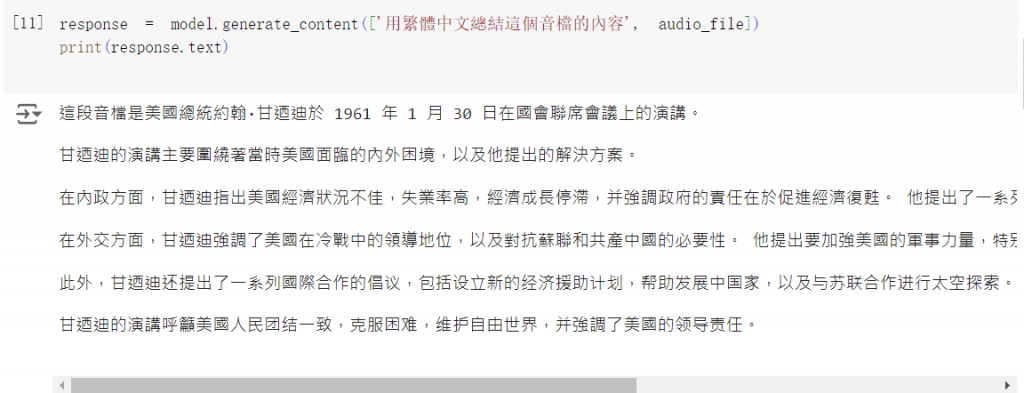
這會將檔案上傳到雲端,官方說 48 小時後會自動刪除,但也可以手動刪掉。
先列出剛剛上傳的檔案,接著刪除掉指定的檔案。
for file in genai.list_files():
print(f"{file.display_name}, URI: {file.uri}")
genai.delete_file(audio_file.name)

他也可以不用上傳,直接讀 byte。順便搭上 chat 功能試試。
import pathlib
chat = model.start_chat(history=[])
response = chat.send_message([
'用繁體中文總結這個音檔的內容',
{
"mime_type": "audio/mp3",
"data": pathlib.Path('samplesmall.mp3').read_bytes()
}
])
print(response.text)

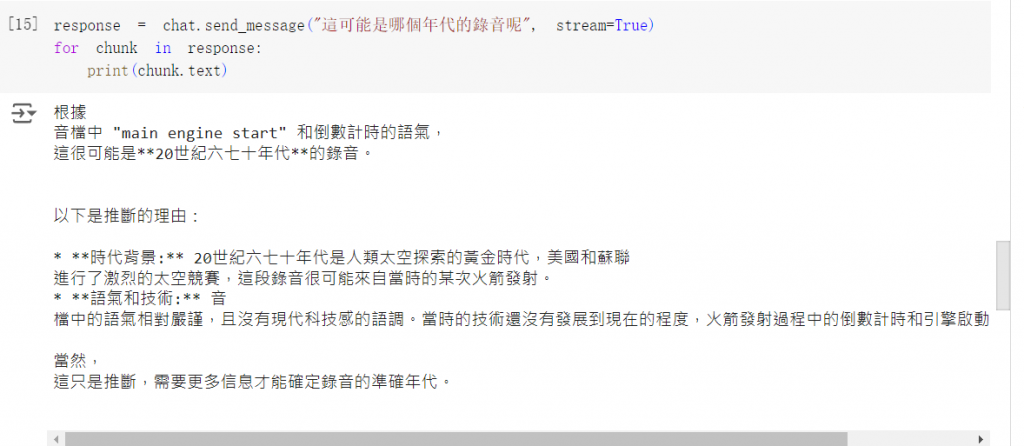
接著往下問問看,效果不錯
response = chat.send_message("這可能是哪個年代的錄音呢", stream=True)
for chunk in response:
print(chunk.text)
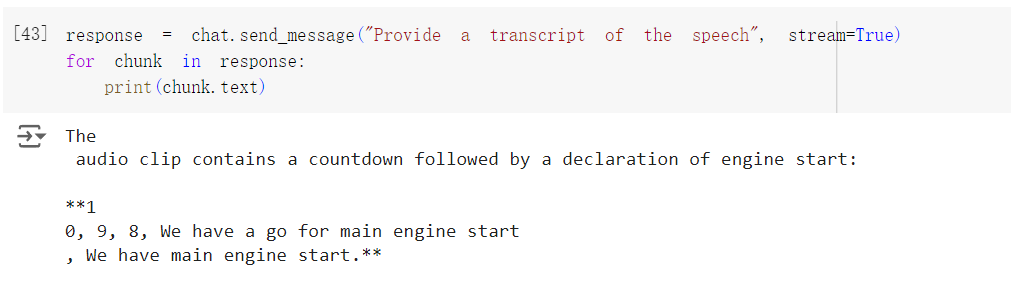
另外他可以提供轉錄搞,但 prompt 如果是中文的話他會無法理解。
response = chat.send_message("Provide a transcript of the speech", stream=True)
for chunk in response:
print(chunk.text)
也可以指定時間區間,把要求下在 prompt 裡就好。
response = chat.send_message("Provide a transcript of the speech from 00:02 to 00:05.", stream=True)
for chunk in response:
print(chunk.text)
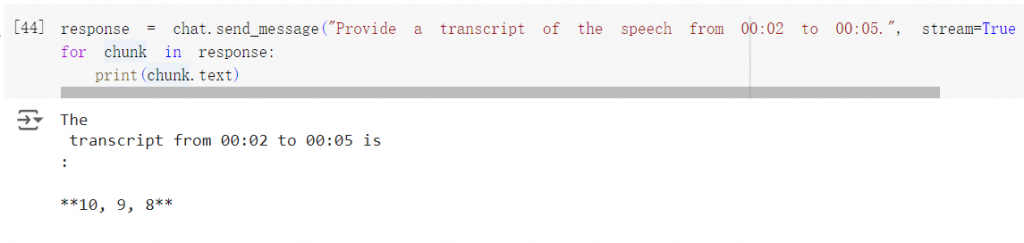
看起來效果是還可以,但不太穩定,我重複試幾次會發現也是會取錯時間,或是順序錯亂。
接著試試影片,下載 google 提供的範例影片。
!wget -O testVideo.mp4 https://storage.googleapis.com/generativeai-downloads/images/GreatRedSpot.mp4
用一樣的方法把資料上傳,順便看一下剛剛的音樂有沒有成功被刪掉。
video_file = genai.upload_file(path='testVideo.mp4')
for file in genai.list_files():
print(f"{file.display_name}, URI: {file.uri}")

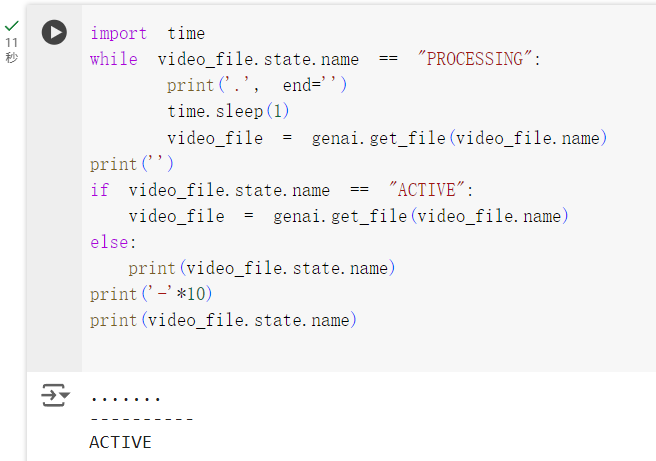
官方說影片上傳時會先經過處理,處理完後檔案的 state 會從 PROCESSING 變成 ACTIVE,這時影像才可以被使用,稍微改一下,來看看他甚麼時後會處理好。
import time
while video_file.state.name == "PROCESSING":
print('.', end='')
time.sleep(1)
video_file = genai.get_file(video_file.name)
print('')
if video_file.state.name == "ACTIVE":
video_file = genai.get_file(video_file.name)
else:
print(video_file.state.name)
print('-'*10)
print(video_file.state.name)
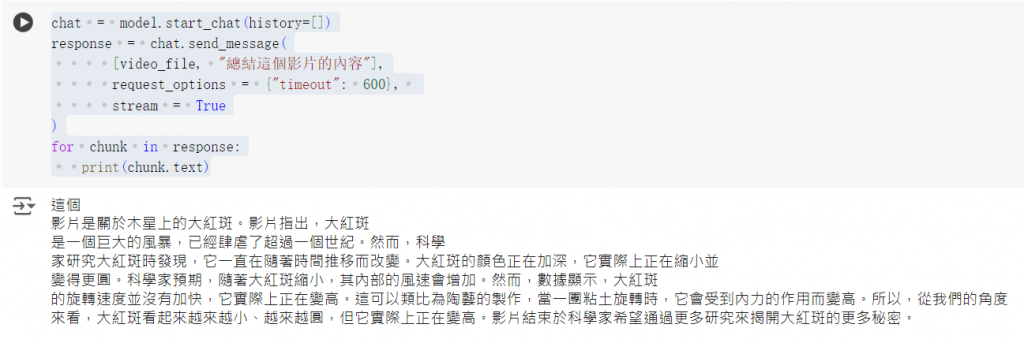
一樣用 chat 來試試他的效果。
chat = model.start_chat(history=[])
response = chat.send_message(
[video_file, "總結這個影片的內容"],
request_options = {"timeout": 600},
stream = True
)
for chunk in response:
print(chunk.text)
跟音檔一樣,也可以指定時間區間。
response = chat.send_message(
"01:35 到 01:47 之間講了些什麼",
stream = True
)
for chunk in response:
print(chunk.text)

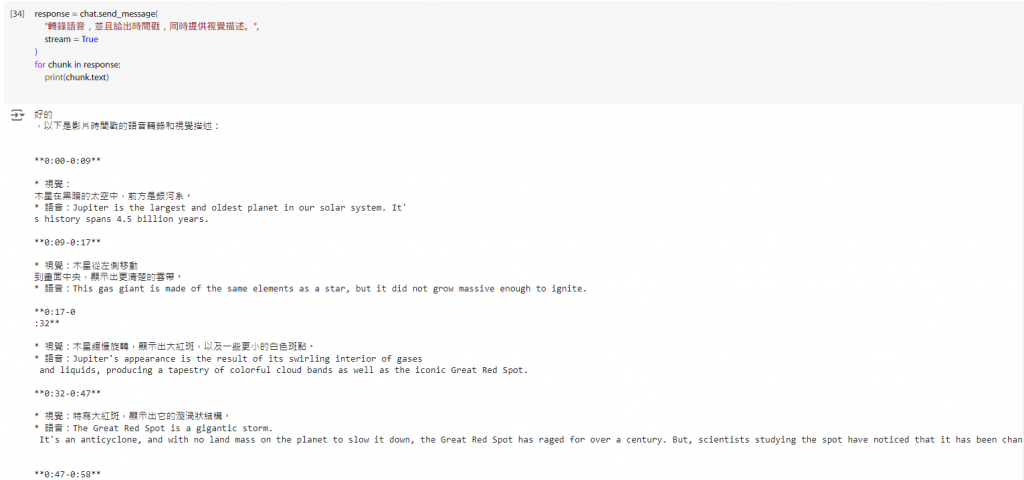
他還有一個用法,除了列出講的內容以外,還可以描述每個時間點的畫面長怎樣。
response = chat.send_message(
"轉錄語音,並且給出時間戳,同時提供視覺描述。",
stream = True
)
for chunk in response:
print(chunk.text)
明天繼續試試看還可以做些什麼。
參考:
https://ai.google.dev/gemini-api/docs/audio?hl=zh-tw&authuser=1&lang=python
https://ai.google.dev/gemini-api/docs/vision?hl=zh-tw&authuser=1&lang=python

