一種機器學習演算法,由多棵決策樹組成,透過迭代方式提升模型準確度
每一輪迭代中,先計算出目前模型梯度,也就是模型預測值與真實值之間誤差方向。根據梯度方向,建立一棵新的決策樹,修正前一輪模型誤差。最後,將新決策樹預測結果與前一輪模型預測結果相加,變成最終預測結果
殘差學習 |
每棵樹學習之前所有樹結論和的殘差 |
|---|---|
梯度下降 |
利用梯度下降的思想,找到使損失函數最小化的方向 |
加法模型 |
最終預測结果是所有樹預測结果相加 |
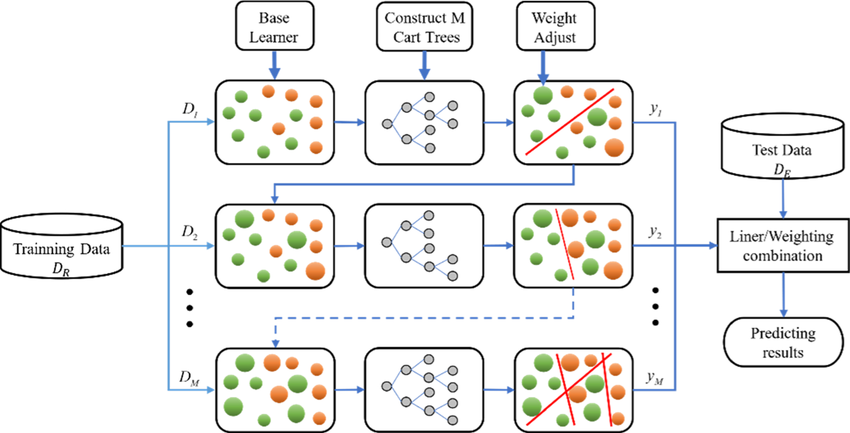
圖片來源:(https://www.researchgate.net/figure/Principle-and-visualization-of-GBDT_fig2_366871709)
圖示說明:GBDT模型由多棵決策樹組成,每棵樹都學習前一棵樹殘差。最終預測結果是所有樹的預測結果加權平均
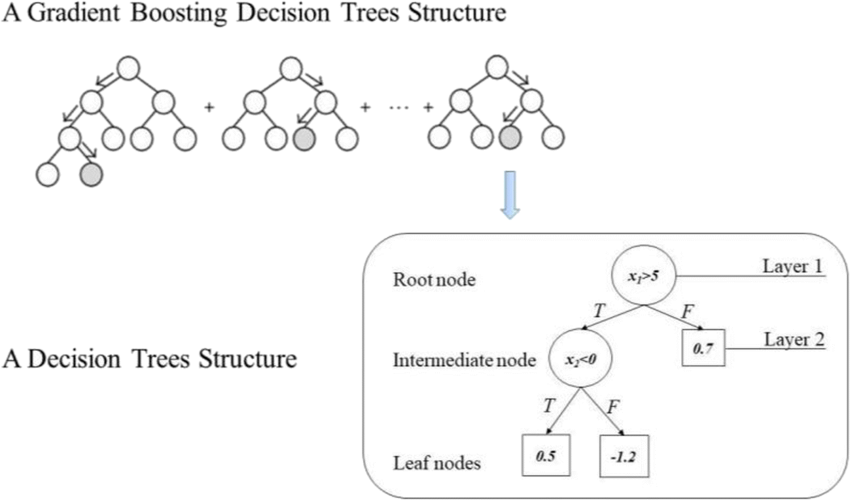
圖片來源:(https://www.researchgate.net/figure/Structure-of-the-gradient-boosting-decision-trees_fig2_344395470)
準確度高 |
能夠處理複雜非線性關係 |
|---|---|
靈活性強 |
可以處理各種類型的數據 |
可解釋性好 |
每棵樹決策過程相對容易理解 |
分類 |
垃圾郵件檢測、欺詐檢測 |
|---|---|
迴歸 |
房價預測、股票價格預測 |
排序 |
搜索引擎排名、商品推薦 |
XGBoost:是目前最流行GBDT實現之一,具有速度快、準確度高等優點LightGBM:是另一個流行的GBDT實現,具有速度更快、內存佔用更小的優點CatBoost:是針對分類任務優化的GBDT實現,具有更高的分類準確度
初始化一個模型,可以是常數模型或簡單的決策樹
在第 t 輪迭代中,計算出目前模型 f(x_i) 的梯度 g_ti = y_i - f(x_i)
建立一棵新的 決策樹h_t(x),來擬合 梯度g_t
更新模型為 f(x) = f(x) + αh_t(x),其中 α 是學習率
F(x) = ∑(m=1 to M) αm h_m(x)
F(x) |
最終預測值 |
|---|---|
αm |
學習率 |
h_m(x) |
第m棵決策樹 |
損失函數L = ∑(i=1 to n) l(y_i, F(x_i))
L |
損失函數 |
|---|---|
l |
損失函數的具體形式(平方損失、對數損失) |
初始化F(x) = c
迭代計算殘差: r_mi = y_i - F(x_i)
擬合新樹: 學習一棵新的決策樹h_m(x),以擬合殘差更新模型: F(x) = F(x) + αm h_m(x)
檢查停止條件: 如果達到最大迭代次數或損失函數不再下降,會停止import xgboost as xgb
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
# 載入數據
boston = load_boston()
X, y = boston.data, boston.target
# 分割數據
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 創建XGBoost模型
params = {
'objective': 'reg:squarederror',
'colsample_bytree': 0.8,
'learning_rate': 0.1,
'max_depth': 3,
'alpha': 10,
'n_estimators': 100
}
model = xgb.XGBRegressor(**params)
# 訓練模型
model.fit(X_train, y_train)
# 進行預測
y_pred = model.predict(X_test)
GBDT是一種強大而靈活機器學習演算法,許多領域都有廣泛應用。通過深入理解原理和實現,可以更好應用GBDT解決實際問題


 iThome鐵人賽
iThome鐵人賽