又稱 AdaBoost,是一種機器學習演算法,由 約阿夫·弗羅因德(Yoav Freund 和 羅伯特·沙皮爾(Robert Schapire) 1990 年代提出。也是一種迭代演算法,在每一輪中加入一個新的弱分類器,直到達到某個預定的足夠小的錯誤率
針對同一個訓練集不同的弱分類器,然後把这些弱分類器集合起来,構成一个強分類器。在自適應增強中,每一個弱分類器都是使用隨機抽取的訓練資料和隨機選擇的變數來訓練的。最終預測結果是通過對所有弱分類器的預測結果進行加權投票來獲得的
初始化:通常將所有弱分類器權重都初始化為 1/N,其中 N 是訓練資料的數量訓練弱分類器:在第 t 輪中,使用隨機抽取的訓練資料和隨機選擇的變數來訓練一個弱分類器計算弱分類器的錯誤率:計算弱分類器在訓練資料上的錯誤率更新弱分類器的權重:根據弱分類器錯誤率來更新權重。通常錯誤率越高的弱分類器,權重就越低預測:使用所有弱分類器的預測結果和權重來預測新資料的類別準確性高:可以比單個弱分類器更準確地預測結果。這是因為自適應增強能夠減少過擬合的風險魯棒性強:對訓練資料的噪聲和異常值不敏感易於實現:自適應增強的演算法相對簡單,易於實現計算量大:自適應增強需要訓練多個弱分類器,因此計算量較大容易受到噪聲的影響:自適應增強對訓練資料的噪聲敏感分類:使用自適應增強來分類客戶的信用風險或垃圾郵件迴歸:使用自適應增強來預測房價或股票價格異常檢測:識使用自適應增強來檢測信用卡欺詐或工業設備中的故障許多流行的機器學習庫都提供自適應增強實現,例如:scikit-learn、R軟體中的AdaBoost套件、 XGBoost 等等
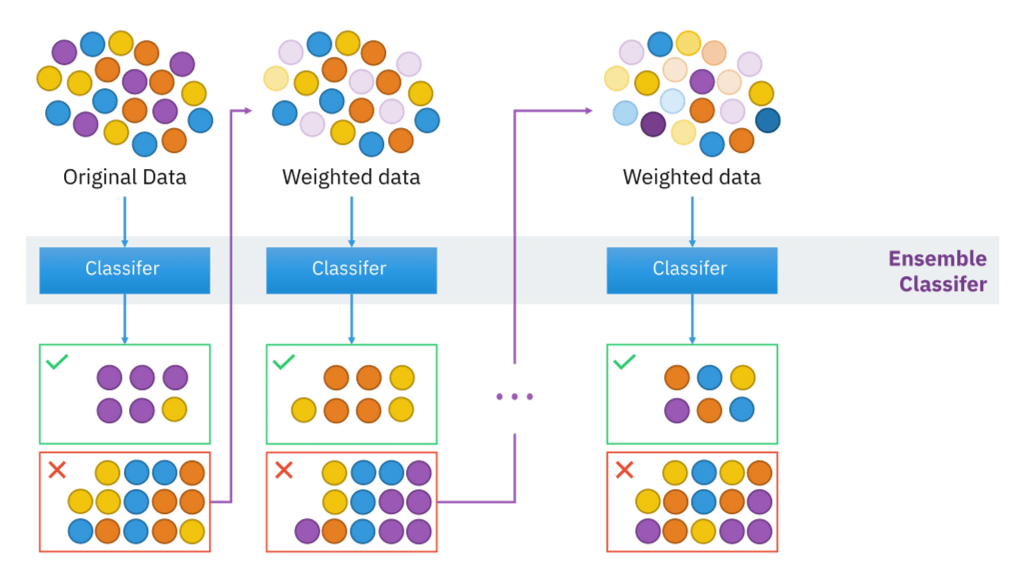
該圖表顯示自適應增強的訓練過程。首先,從訓練資料中隨機抽取一個子集。然後,使用該子集訓練一個弱分類器。對所有決策樹重複此過程。最後,通過對所有決策樹的預測結果進行投票來獲得最終的預測結果
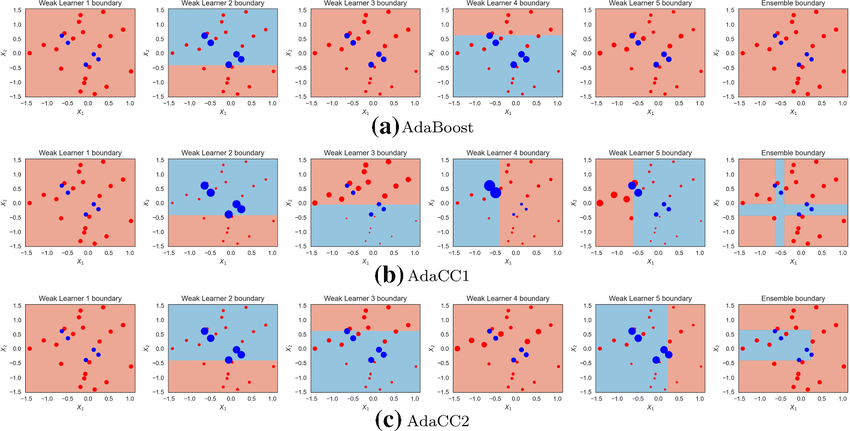
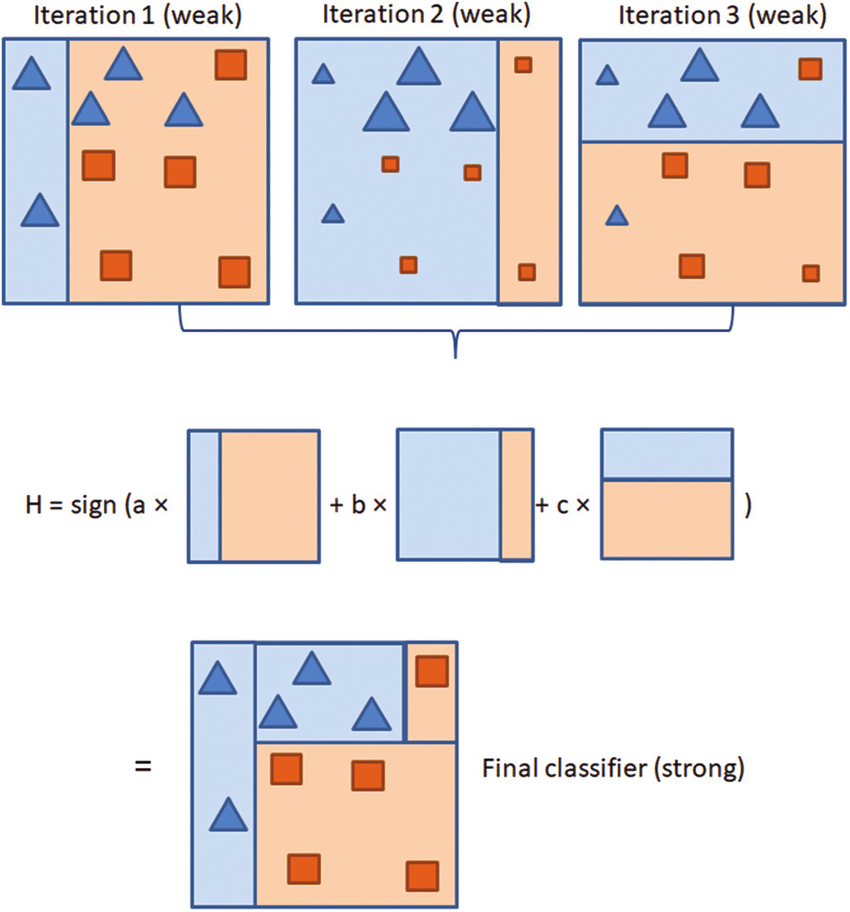
每個弱分類器都產生一個決策邊界,AdaBoost 將這些決策邊界進行加權組合,最終形成一個更複雜、更準確的決策邊界
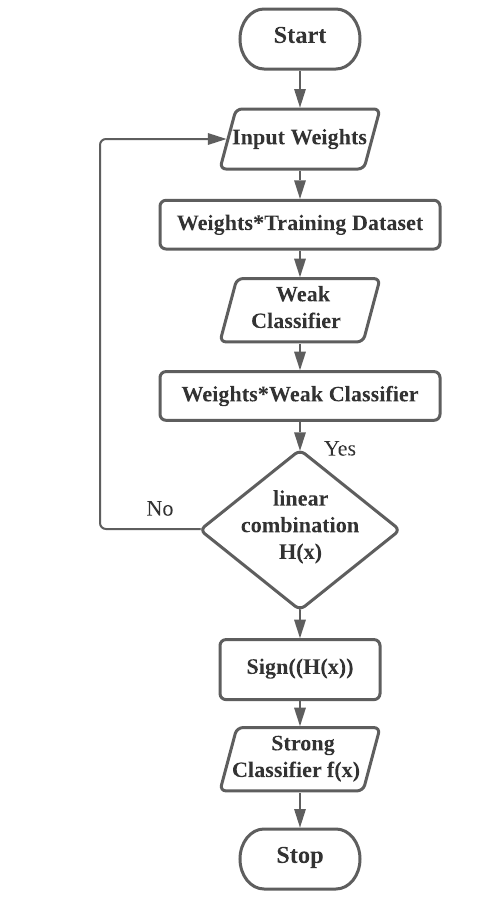
圖片來源:(https://www.researchgate.net/figure/Process-of-Adaboost-Algorithm_fig2_356819075)
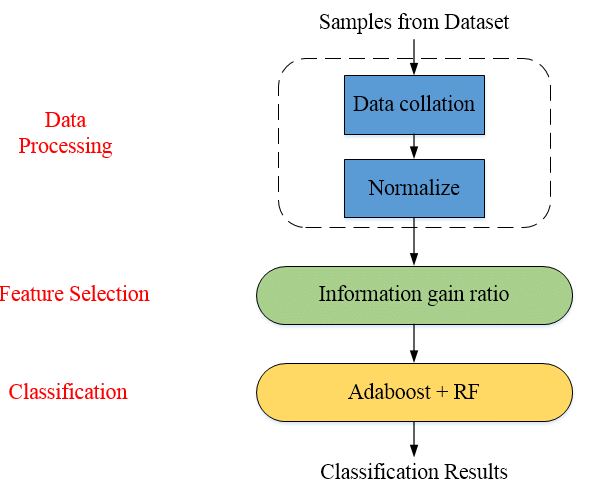
圖片來源:(https://www.researchgate.net/figure/Adaboost-RF-algorithm-flowchart_fig1_333499498)
初始化每個訓練樣本賦予相同的權重

圖片來源:(https://stats.stackexchange.com/questions/473241/weights-in-adaboost)
訓練弱分類器根據當前的樣本權重訓練一個弱分類器
計算錯誤率計算弱分類器的錯誤率
更新樣本權重增加被誤分類樣本的權重,減少被正確分類樣本的權重
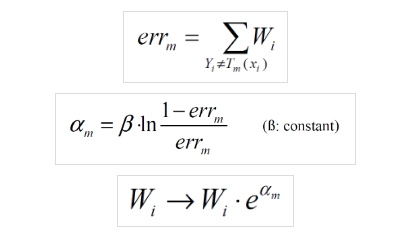
圖片來源:(https://datascience.stackexchange.com/questions/46624/updating-weights-in-adaboost)
計算弱分類器權重根據錯誤率計算弱分類器的權重
組合弱分類器將所有弱分類器按照其權重進行加權組合,得到最終的強分類器
重複步驟2-6直到達到預定的迭代次數或滿足其他停止條件
預測結果y = sign(sum(w_i * y_i))
y |
最終預測結果 |
|---|---|
w_i |
第 i 個弱分類器權重 |
y_i |
第 i 個弱分類器預測結果 |
弱分類器權重w_t+1 = w_t * alpha * exp(-e_t)
w_t |
第 t 輪弱分類器權重 |
|---|---|
w_t+1 |
第 t+1 輪弱分類器權重 |
e_t |
第 t 輪的弱分類器的錯誤率 |
alpha |
學習率 |
初始化樣本權重D_1(i) = 1/N, i = 1, 2, ..., N
N是訓練樣本的數量

在第 t 輪,訓練一個弱分類器 h_t,在加權訓練集上的錯誤率最小
e_t = Σ_i D_t(i)I(h_t(x_i) ≠ y_i)
I(·) 是指示函數,當括號內的條件成立時為 1,否則為 0
計算弱分類器權重α_t = 0.5 * ln((1 - e_t) / e_t)
樣本權重更新w_{t+1,i} = w_{t,i} * exp(-α_t * y_i * h_t(x_i)) / Z_t
w_{t,i} |
第 t 輪中第 i 個樣本的權重 |
|---|---|
α_t |
第 t 個弱分類器的權重 |
y_i |
第 i 個樣本的真實標籤 |
h_t(x_i) |
第 t 個弱分類器對第 i 個樣本的預測 |
Z_t |
歸一化因子,確保所有樣本權重之和為 1 |
最終分類器H(x) = sign(Σ_t α_t h_t(x))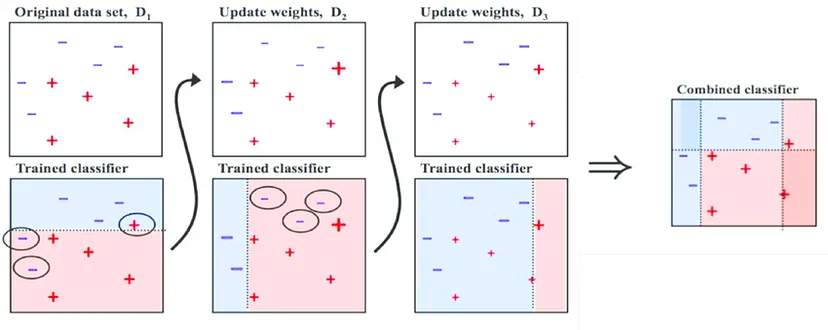
圖片來源:(https://towardsdatascience.com/understanding-adaboost-for-decision-tree-ff8f07d2851)
from sklearn.ensemble import AdaBoostClassifier
# 訓練資料
X = [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]
y = [1, 1, -1, -1, 1]
# 初始化 AdaBoost 分類器
clf = AdaBoostClassifier(n_estimators=100)
# 訓練模型
clf.fit(X, y)
# 預測新資料
new_X = [[11, 12]]
predicted_y = clf.predict(new_X)
print(predicted_y)
程式碼中,首先創建一個訓練資料集和一個標記集。然後初始化一個 AdaBoost 分類器並訓練模型。最後,使用模型預測新資料的類別
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import
load_iris
from sklearn.model_selection import train_test_spli
t
# 載入鳶尾花資料集
iris = load_iris()
X = iris.data
y = iris.target
# 分割訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_st
ate=0)
# 創建 AdaBoost 分類器
clf = AdaBoostClassifier(n_estimators=100, base_estimator=DecisionTreeClassifier(max_depth=1))
# 訓練模型
clf.fit(X_train, y_train)
# 評估模型
accuracy = clf.score(X_test, y_test)
print("Accuracy:", accuracy)
程式碼說明n_estimators:弱分類器的數量base_estimator:基礎分類器,這裡使用決策樹max_depth:決策樹的最大深度from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import
make_classification
# 生成樣本數據
X, y = make_classification(n_samples=1000, n_features=20, random_state=0)
# 創建 AdaBoost 分類器,基分類器為決策樹
clf = AdaBoostClassifier(n_estimators=100, base_estimator=DecisionTreeClassifier(depth=1), learning_rate=1)
# 訓練模型
clf.fit(X, y)
# 預測
y_pred = clf.predict(X)
AdaBoost 作為一種經典的集成學習演算法,在機器學習領域有著廣泛的應用。它通過將多個弱分類器組合成一個強分類器,有效提高了模型的預測性能。然而,在實際應用中,需要根據具體的任務和數據特點,選擇合適的基分類器和調整相關參數,才能取得最佳的實驗效果


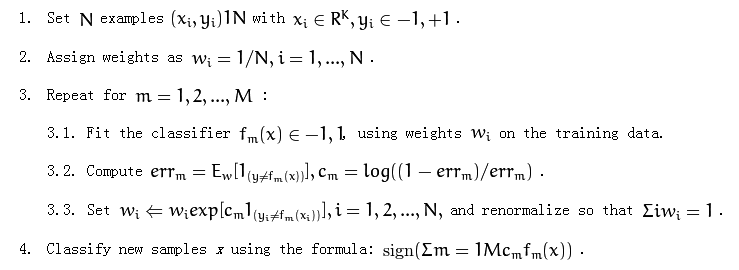

 iThome鐵人賽
iThome鐵人賽