一種非監督式機器學習算法,將數據集劃分為預定義數量集群。目標是將彼此相似數據點歸為一類,與其他集群中數據點不同
優點缺點客戶分群 |
將客戶分為不同群體,以便進行個性化營銷 |
|---|---|
圖像分割 |
將圖像分割成不同區域 |
聚類分析 |
發現數據集中內在結構 |
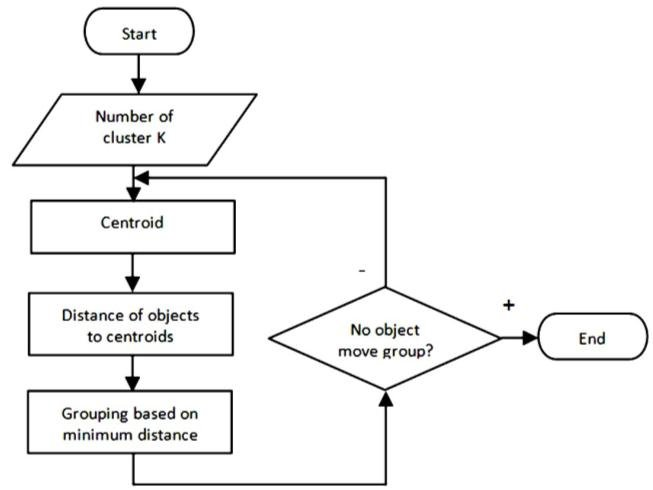
圖片來源:(https://www.researchgate.net/figure/K-means-clustering-process-flowchart_fig7_271305580)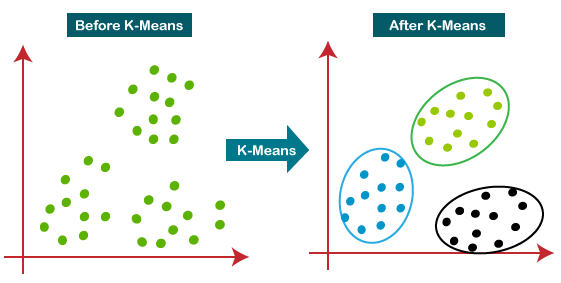
圖片來源:K Means Clustering in Python | Step-by-Step Tutorials for Clustering in Data Analysis
數學公式通常使用歐式距離來計算數據點與簇中心的距離
歐式距離(x, c) = sqrt(Σ(xi - ci)^2)
對於兩個數據點 x 和 y,它們之間的歐式距離為:distance(x, y) = sqrt(Σ(xi - yi)^2)
x |
數據點 |
|---|---|
c |
簇中心 |
xi |
數據點第 i 個特徵 |
ci |
簇中心第 i 個特徵 |
簇中心更新ci = (1/ni) * Σ(x)μ_i = (1/n_i) * Σ(x_j)
ci |
簇中心 |
|---|---|
ni |
簇中數據點的數量 |
x |
簇中所有數據點 |
n_i |
屬於簇 i 數據點數量 |
x_j |
屬於簇 i 的數據點 |
from sklearn.cluster import KMeans
import numpy as np
# 隨機生成一些數據
X = np.random.rand(100, 2)
# 創建 KMeans 模型,指定簇的數量
kmeans = KMeans(n_clusters=3, random_state=0)
# 訓練模型
kmeans.fit(X)
# 預測每個數據點屬於哪個簇
y_pred = kmeans.predict(X)
# 獲取簇中心
centers = kmeans.cluster_centers_
如何選擇最佳K值?肘部法(Elbow Method):繪製不同 K 值下的誤差平方和(SSE),選擇SSE變化率下降最快的K 值輪廓係數 (Silhouette Coefficient):計算每個數據點的輪廓係數,選擇輪廓係數最高的K值Gap Statistic: 比較數據集的聚類結果與隨機數據的聚類結果,選擇差異最大的K值
K-means 聚類是一種強大聚類算法,但也有局限性在實際應用中,需要根據數據特點和具體需求選擇合適聚類算法


 iThome鐵人賽
iThome鐵人賽