今天繼續紀錄Summary Functions的應用
邏輯計算
mean(): TRUE值的比例
sum(): TRUE值的數量
順序取值
dplyr::first(): 第一個數值
dplyr::last(): 最後一個數值
dplyr::nth(): 在第n位置的數值
建立範例資料集
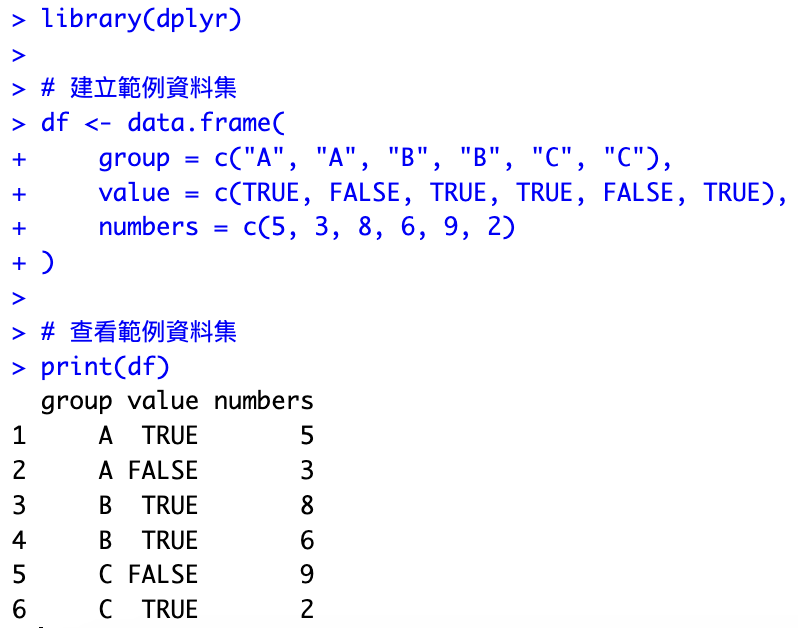
library(dplyr)
# 建立範例資料集
df <- data.frame(
group = c("A", "A", "B", "B", "C", "C"),
value = c(TRUE, FALSE, TRUE, TRUE, FALSE, TRUE),
numbers = c(5, 3, 8, 6, 9, 2)
)
# 查看範例資料集
print(df)
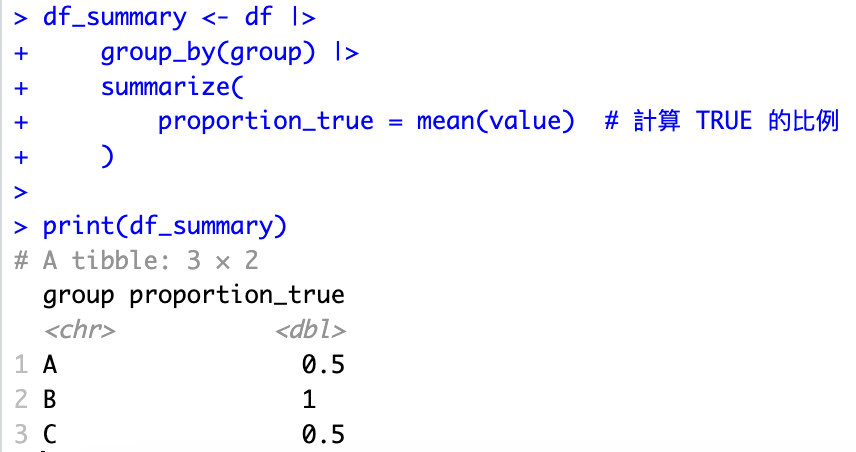
計算每個分組(group)中 value 為 TRUE 的比例
df_summary <- df |>
group_by(group) |>
summarize(
proportion_true = mean(value) # 計算 TRUE 的比例
)
print(df_summary)
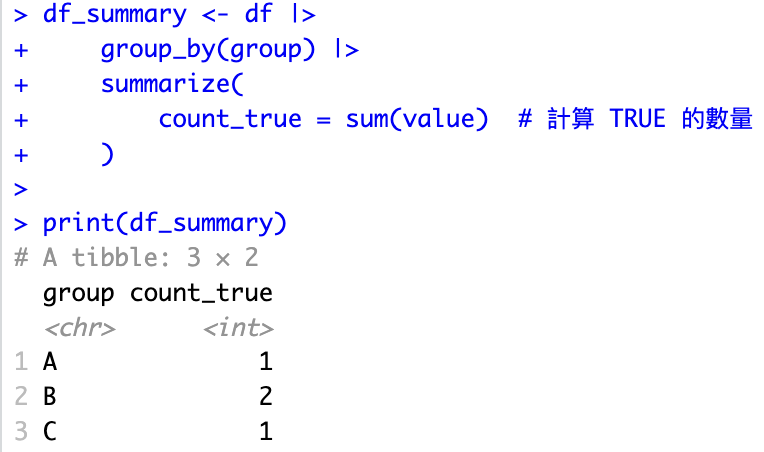
計算每個分組(group)中 value 為 TRUE 的數量
df_summary <- df |>
group_by(group) |>
summarize(
count_true = sum(value) # 計算 TRUE 的數量
)
print(df_summary)
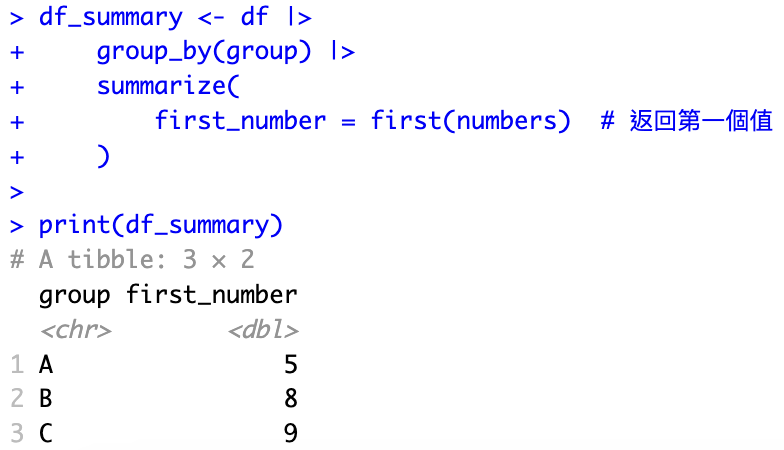
回傳每個分組(group)中 numbers 變數的第一個值
df_summary <- df |>
group_by(group) |>
summarize(
first_number = first(numbers) # 返回第一個值
)
print(df_summary)
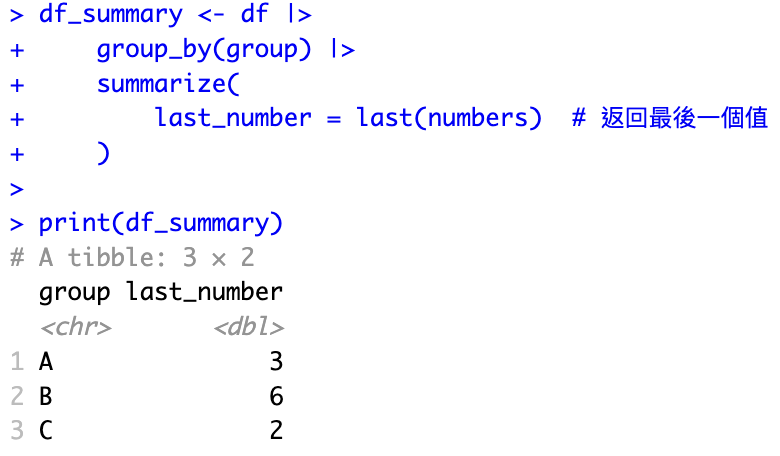
回傳每個分組(group)中 numbers 變數的最後一個值
df_summary <- df |>
group_by(group) |>
summarize(
last_number = last(numbers) # 返回最後一個值
)
print(df_summary)
回傳每個分組(group)中 numbers 變數的第2個值
df_summary <- df |>
group_by(group) |>
summarize(
second_number = nth(numbers, 2) # 返回第2個值
)
print(df_summary)

參考資料:


 iThome鐵人賽
iThome鐵人賽