

本系列目標對象是針對對 AI 和 Generative AI 完全沒有背景知識的說明,這次說明的觀念是 RAG: Retrieval-Augmented Generation。
大家應該都知道語言模型都是根據訓練資料來回答生成文字,而訓練資料可以是網路文章,書籍,文字資料等等。但是生成式模型的問題是,由於是根據最大機率來生成文字,所以有時候會生成出不合理的文字,或者是不符合上下文的文字,或是不符合特定主題的文字。而大多人都會以此認知為娛樂,例如: 「你看,這就是某某某模型的限制,能力不夠好,都亂回答」
RAG 其實是一種結合傳統檢索式問答系統與生成式模型的方法。檢索式又是什麼意思,指的是透過搜尋引擎的方式,找到相關的資料,然後再進行回答。而 RAG 就是透過檢索式的方式,找到相關的資料,然後再進行生成式的回答。
在這邊搜尋引擎僅是一種概念上的引擎,而不一定是 Google 搜尋,可以回頭想想在做資料庫的查詢也可以是一種檢索式的方式。只要在原始資料中透過有系統的方式找到相關資料,就可以稱為一種檢索式的方式。生活上常見的例子就是,一本書的書目,或是圖書館的索引系統,都是一種檢索式的方式。
透過檢索系統搜尋的結果,通常會有一個或多個答案,而這些答案可以是一段文字,一個句子,或是一個關鍵字。這些答案就是 RAG 的檢索結果。這邊可以想像透過像是 Google Search 或是其他搜尋引擎搜尋到的結果,都是一種檢索結果。
以 Azure Search 這個搜尋結果來看,
https://learn.microsoft.com/en-us/azure/search/search-pagination-page-layout
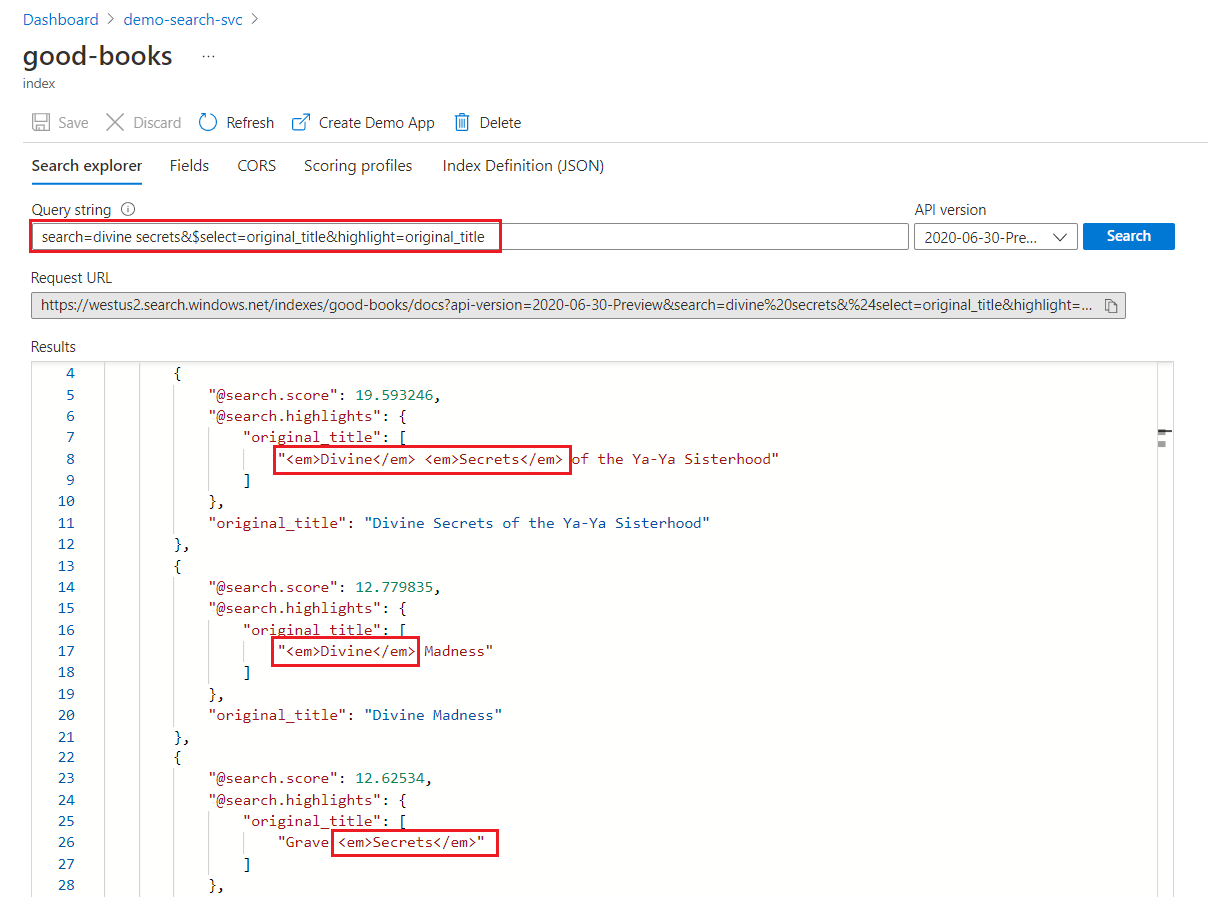
會有幾個部分:
表示搜尋結果的相關性分數, 相關文字等等。
當有了檢索結果之後,就可以進行生成式回答。這邊的生成式回答,就是透過生成式模型來回答問題。而這個生成式模型,可以是 GPT, Gemini, Llama 等等。
RAG 的第一個最基本的優點,就是傳統的搜尋方式,都是關鍵字搜尋,而 RAG 是透過自然語言問答的方式,這個意思指的是,你在搜尋的時候,不需要特別去想關鍵字,而是直接問問題,就可以得到答案。
將 LLM/ChatGPT 整合進公司系統,然後呢? - R-Ladies Taipei
