剛學習LLM的時候,只會知道要用GPU,因為他的平行計算能力比較快。不過真的只有這樣嗎?

(圖源: 自製)
在運算的過程中,最主要會消耗的是大量的記憶體(資料暫存、傳輸速度),還有計算資源(運算力、計算速度),這篇文章主要參考了NVIDIA BLOG的文章,再加上筆者的整理,來介紹LLM推理過程中哪些地方會用到這兩個部分吧!
在這之前,要讀懂這篇文章有一些必須先熟悉的基礎在,筆者將對應的李宏毅教授yt課連結放上去。
LLM基本上就是堆疊了很多的transformer,因為是autoregressive模型,推理的過程中,會將一系列的tokens作為輸入,預測下一個出現的單字,重複這個循環,直到滿足停止條件,像是字數限制、stopwords。而當然,不同的LLM會有不同的tokenizers。
這邊一共分成了兩個階段:
在prefill階段,LLM會將所有input tokens去做處理,計算中間的狀態 (intermediate states, keys, values),用來產生第一個新token。雖然才剛說過每個token都依賴前一個token,但由於這邊的輸入範圍已經知道是所有input tokens,透過一次foward完成,所以可以一次做出大量矩陣-矩陣之間平行運算,這會使GPU利用率大增加,產生第一個token的速度依賴GPU的運算能力,也就是Compute Bound的任務。
在decode階段,在停止條件之前,LLM每次輸出會用到先前迭代的所有輸出狀態 (keys, values),為了避免重複計算,會使用KV快取來存前面的狀態資料。跟前一個階段比起來,這邊開始的矩陣計算會從矩陣-矩陣,變成矩陣-向量,因此不會用到太多GPU運算能力。且一次只會跑一次forward,如果最後輸出N個Token,那他會跑N-1次forward,這邊不能平行執行,只能串流執行,所以GPU的使用效率很低。這裡更在乎的是暫存資料 (weights, keys, values, activations)從記憶體傳送到GPU的速度,這個讀取速度才是延遲的速度,而非推理上的延遲,也就是Memory Bound的操作。不過一旦當輸出序列變長,推理的延遲也會稍微增加。
因此可以知道LLM推理上最大的問題是Memory Bound的時間!
所以目前大部分的優化方式都在這個階段完成,會在後續的章節 (System-level / Hardware-Level Optimization)中做介紹。另外補充說明,這邊的資料傳輸速度不是指網路的速度,而是記憶體頻寬 (Memory Bandwidth)。
這是GPU在每秒內可以從記憶體讀取或寫入的資料量,通常以GB/s (Gigabytes per second)為單位。在單一電腦的GPU跑LLM的話,KV快取的讀寫只需要考慮到Memory Bandwidth,但是也有狀況是多GPU、clusters的情況下,彼此之間會需要做資料讀取,就會有網路傳輸的速度在了。
這部分也會在後續的章節中提到!
如圖所示,decode階段的計算依賴先前所有token的KV張量,包含prefill階段input token的計算KV,還有當前時間之前計算的所有KV張量。
為了避免在每個步驟都重新進行大計算,所以會將這些張量緩存在GPU的記憶體中。每次迭代,他們都會被加到正在運行的快取當中,讓下一次迭代去使用他們。
如圖粉紫色的地方,也就是犧牲記憶體的用量,大量減少運算資源,結果來看是滿划算的,所以這個方法目前是被廣泛使用的。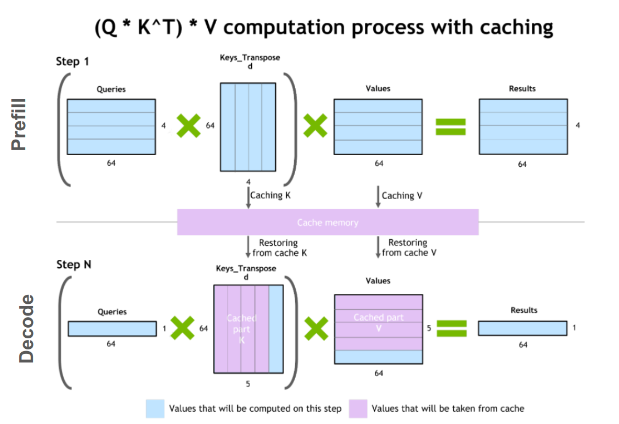
(圖源: NVIDIA DeveloperTechnical Blog)
剛剛介紹了計算上的KV快取,但KV快取並不是LLM唯一卡在記憶體上佔空間的東西,我們不能忘記最重要又肥大的模型權重!
所以真正記憶體的消耗 = 模型權重 + KV快取
假如我們使用batch處理請求,batch中每個請求的KV快取都是獨立分配的,也會各自佔用大量的記憶體。為了要更簡單的了解,先來看他的計算公式:
每個token的 KV 快取大小(以bytes為單位) = 2 * (num_layers) * (num_heads * dim_head) * precision_in_bytes
其中,2代表了K和V的矩陣。通常來說(num_heads * dim_head)的值會跟模型卡中transformer的hidden_size(或模型的維度,d_model)相同。
模型卡通常就是每個模型的config.json
如果是半精度(FP16)的話:
KV 快取的總大小(以bytes為單位) = (batch_size) * (sequence_length) * 2 * (num_layers) * (hidden_size) * sizeof(FP16)
EX:16-bit的Llama-2-7B模型,Batch size=1,KV快取就是1 * 4096 * 2 * 32 * 4096 * 2,大約2GB。
上面提到的FP16是最常使用來載入LLM的精度之一,因為它不需要用到FP32這麼多記憶體消耗,至於還有哪一些我們也在這章簡單介紹一下。
雙精度浮點數(FP64):64位浮點數,用在最高精度的科學計算,如氣候模型、金融分析。
單精度浮點數(FP32):32位浮點數,大多數深度學習框架(TensorFlow、PyTorch)默認使用FP32。
Tesla P32(TF32):32位浮點數,NVIDIA CUDA Compute Capability 8以上的GPU支援。
半精度浮點數(FP16):16位浮點數。
bfloat16(BF16):16位浮點數,與FP16有相同的指數範圍,犧牲了一些精度,但與和FP32之間的轉換方便。
8位浮點數(FP8):8位浮點數。
4位浮點數(FP4):4位浮點數。
4位固定點數(NF4):一些研究使用FN4進行模型量化。
INT8:8位整數,常見的量化精度。
INT4:4位整數,同樣為量化精度。
在推理的部分,LLM最常見的是BF16、FP16、INT8,主要就是看模型選擇和硬體設備支援的精度格式,硬體設備的部分後面有關GPU的章節會提到。
經過簡單的文章整理,我們現在知道當我們要使用LLM,時間上不只是要仰賴GPU的推理計算能力,還有記憶體的容量和I/O。前者在prefill階段特別重要,而後者的decode階段比較重要。而LLM的記憶體主要是包含了模型權重和KV快取。
接下來在下一個章節來介紹LLM的推理上有什麼評估指標。
之後的文章應該就不會這麼長了XD

(圖源: 自製)
Mastering LLM Techniques: Inference Optimization
https://developer.nvidia.com/blog/mastering-llm-techniques-inference-optimization/
淺談DeepLearning的浮點數精度FP32/FP16/TF32/BF16……..(以LLM為例)
https://medium.com/@averyaveavi/%E6%B7%BA%E8%AB%87deeplearning%E7%9A%84%E6%B5%AE%E9%BB%9E%E6%95%B8%E7%B2%BE%E5%BA%A6fp32-fp16-tf32-bf16-%E4%BB%A5llm%E7%82%BA%E4%BE%8B-9bfb475e50be

