先前在 Day10 講過了針對計算資源的分散式架構Ray ⚙️,也在 Day26 提到多個server組成cluster的概念 🌐,在這些clusters上每個ESXi都有許多VM,VM上面又有許多的APP,以及完善的HA機制 🛡️,然而,單靠VM作為基礎架構對於服務的彈性來說仍然不夠靈活。
對於LLM服務來說,穩定性和擴展性是非常重要的 🌟,沒有人希望在面對硬體故障或不可預期的狀況時,服務突然中斷 ❌。因此,針對硬體HA的部分昨天提過了,接下來將探索從傳統的VM到容器技術、再到分散式系統的演化過程,並以kubernetes為例,探討其中的關鍵概念,以及它如何管理應用服務 🚀。
🔍 章節大綱
- 電腦 / VM / Container 技術的演化 🧬
- 對於 Kubernetes 的簡單介紹 🌍
因為kubernetes是超大坑,沒有辦法真的詳細介紹XD,只打算說明它針對服務管理有那些優點,以及稍微講一下怎麼跟昨天那個超大VMware infra架構圖接起來。

(圖源: Medium,Docker Swarm也算另一種分散式架構)
在設計分散式架構之前,首先需要了解計算資源管理技術的演化過程!從傳統的一台電腦到虛擬化、再到容器化,這大大地影響了服務部署和管理的靈活性。 🖥️ ➡️ 📦
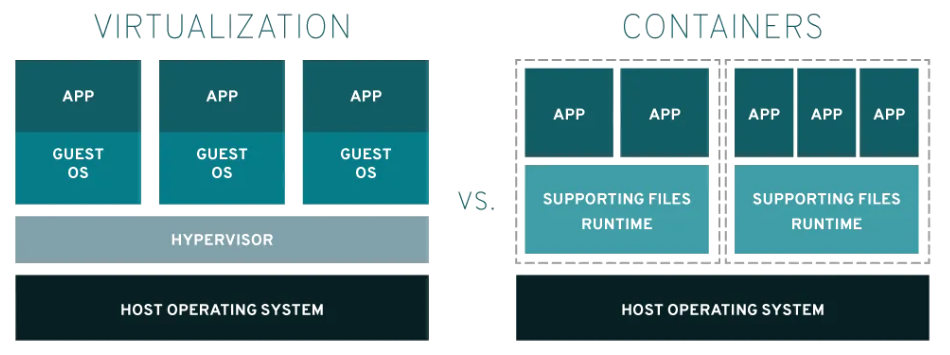
(圖源: redhat)
傳統電腦 (Physical Machines) 🖥️
虛擬機器 (VM) 🖥️
容器 (Container) 📦
這種從單機到虛擬化、再到容器化的演化過程,使我們能夠更有效率地去利用計算資源,同時為大規模的模型訓練和推理服務提供了穩定的基礎!
先前 Day10 介紹計算資源的分散式架構時很常提到Node,這邊我們以kubernetes為例來提一下它是什麼。
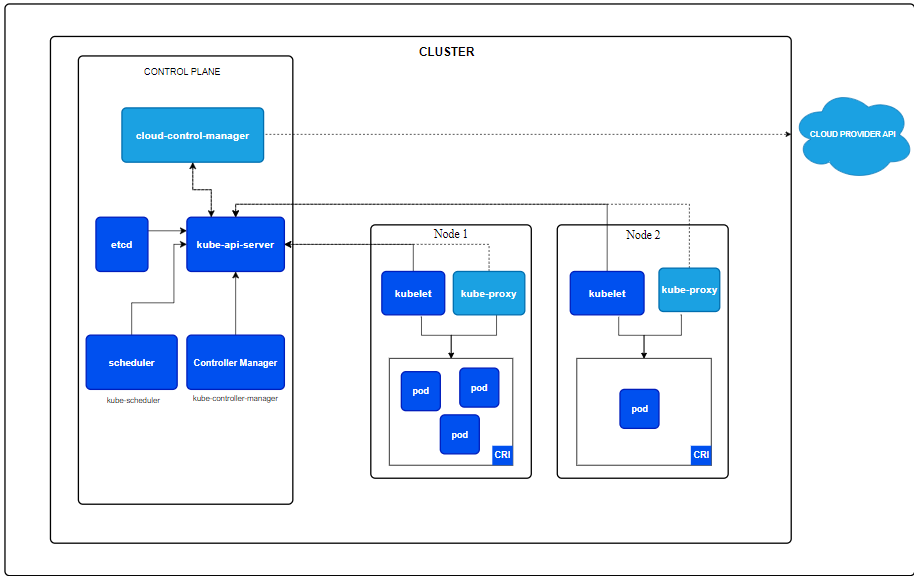
(圖源: kubernetes docs,先不用在意裡面的細節XD,cluster就是昨天那張圖的cluster,Node對應的就是VM!如果沒有VM,對應的就是電腦。)
Node的概念 🖥️
Pod、Container、服務 🧳
高可用性和自我修復 🔄
⏳ 而這種自我修復的能力對於LLM推理這種需要長時間運作、以及會有大量requests的服務特別重要,至於它的缺點正如同 Day10 所說,它主要是針對服務的分散式架構,因此對於計算資源的分配搭配Ray使用會更好。
註:雖然網路上有其他更好懂的圖,但亂貼好像不太好,所以這邊都放大公司的文件的圖。
這一章中,我們更深入地了解了從VM到container的架構演化 🔄,以及kubernetes如何幫助管理分散式的應用服務 🛠️,將VM上面的結構又看得更清楚一些了,更深入了解從資料中心一路到APP的其中一種infra設計架構 🌐。雖然kubernetes仍有許多細節可以學習,但它提供的靈活性和高可用性讓其成為現代基礎設施設計中的核心工具。
BTW,筆者個人滿喜歡2022鐵人賽的從異世界歸來發現只剩自己不會 Kubernetes 系列,講得很簡單又好懂,同樣推推。 🌟
雖然文章中的架構看似簡單,但在實際部署中又是一個大坑 🔥。希望這些技術分享能讓讀者在探索分散式架構時有更多的靈感 💡,即使對於小公司來說並不需要這麼大規模的架構,這之中的經典架構仍值得一學 📚。
幫文章取名好難,而且寫infra篇會讓筆者做惡夢,今天半夜才夢到自己回infra時期的工作地方上班......明天就繼續往監控的地方做最後衝刺了!

(圖源: Medium)

