接下來兩天,我們將一起製作一張Euro NCAP 2023安全評分表(註1)。
今天我們說明如何收集資料及將其整理為Polars DataFrame,明天則說如何製作表格及輸出。
其中資料收集的程式碼存於01_collect_data.ipynb,而DataFrame及表格製作等程式碼則存於euroncap_2023.ipynb。
可以點選下圖預覽成果影片: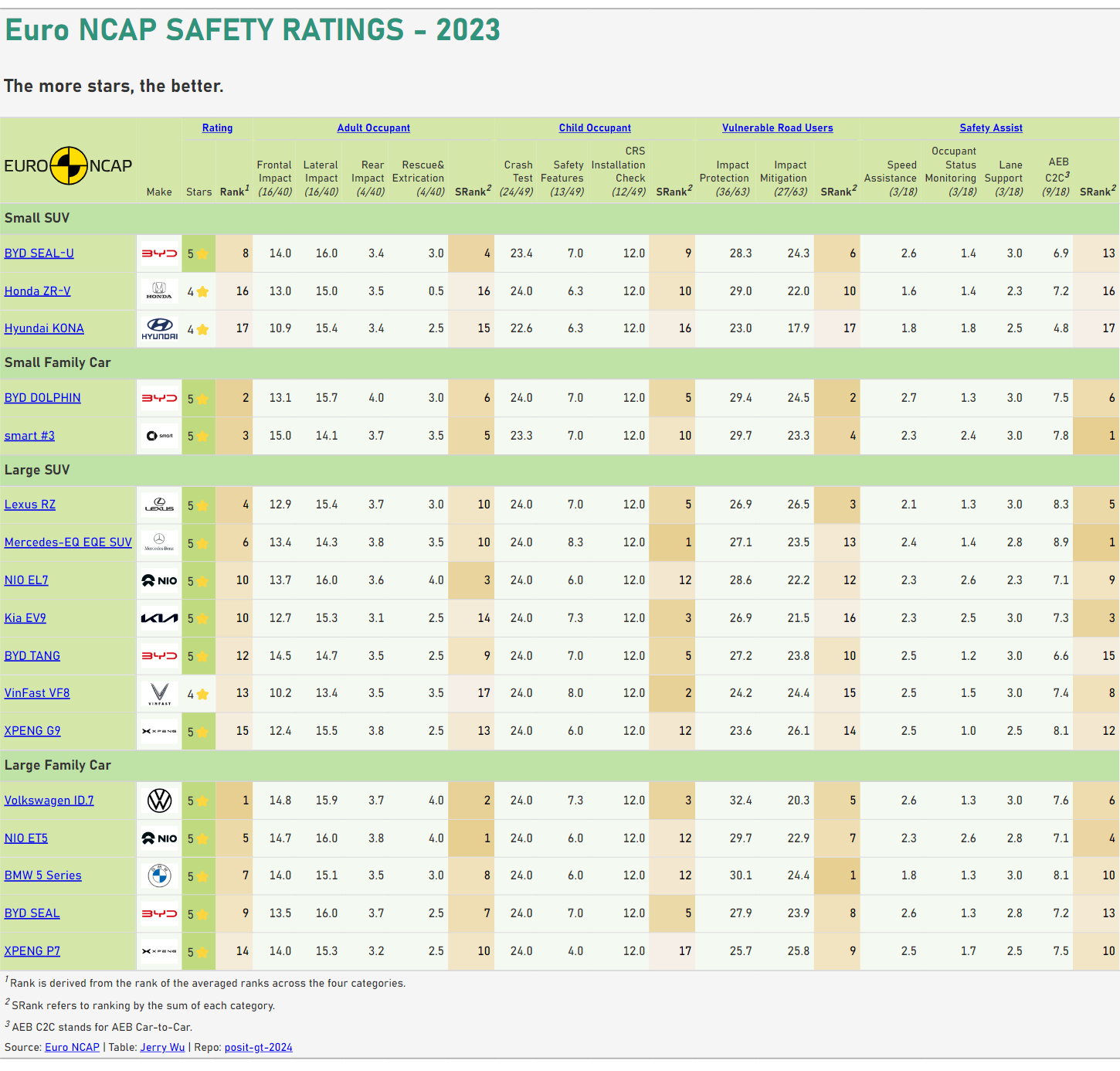
我們的目標是收集2023年十七台車的測試分數(註2)。測試一共分為「"Adult Occupant"」、「"Child Occupant"」 、「"Vulnerable Road Users"」及「"Safety Assist"」四個大項,每項中又有若干細項。此外還需要收集車商、車型等基本資料。
總計每台車需要收集十八個欄位的資訊。我們將每台車的資訊打包成為一個字典,並將十七個字典集合為一個名為data的列表後,再使用DataFrame.write_json()輸出為euroncap_2023.json(註3)。
from enum import Enum
from itertools import chain
from pathlib import Path
from typing import Callable, Iterable
import polars as pl
from great_tables import GT, html, loc, style, system_fonts
from polars import selectors as cs
adult_occupant_columns = [
"Frontal Impact",
"Lateral Impact",
"Rear Impact",
"Rescue and Extrication",
]
child_occupant_columns = [
"Crash Test Performance",
"Safety Features",
"CRS Installation Check",
]
vulnerable_road_users_columns = ["VRU Impact Protection", "VRU Impact Mitigation"]
safety_assist_columns = [
"Speed Assistance",
"Occupant Status Monitoring",
"Lane Support",
"AEB Car-to-Car",
]
columns = [
"Make",
"Model",
"Class",
"Url",
"Stars",
*adult_occupant_columns,
*child_occupant_columns,
*vulnerable_road_users_columns,
*safety_assist_columns,
]
data = [
dict(
zip(
columns,
(
"BMW",
"BMW 5 Series",
"Large Family Car",
"https://www.euroncap.com/en/results/bmw/5+series/50186",
5,
14,
15.1,
3.5,
3,
24,
6,
12,
30.1,
24.4,
1.8,
1.3,
3,
8.1,
),
)
),
...
]
df = pl.DataFrame(data)
df.cast(pl.Utf8).write_json("euroncap_2023.json")
JSON格式部份預覽如下:
[
{
"Make": "BMW",
"Model": "BMW 5 Series",
"Class": "Large Family Car",
"Url": "https://www.euroncap.com/en/results/bmw/5+series/50186",
"Stars": "5",
"Frontal Impact": "14.0",
"Lateral Impact": "15.1",
"Rear Impact": "3.5",
"Rescue and Extrication": "3.0",
"Crash Test Performance": "24.0",
"Safety Features": "6.0",
"CRS Installation Check": "12",
"VRU Impact Protection": "30.1",
"VRU Impact Mitigation": "24.4",
"Speed Assistance": "1.8",
"Occupant Status Monitoring": "1.3",
"Lane Support": "3.0",
"AEB Car-to-Car": "8.1"
},
...
]
接下來我們需要生成gt所需的DataFrame,步驟如下:
euroncap_2023.json生成DataFrame,並預覽其第一行。tweak_df(),其會接收一個JSON檔案為參數,並返回一個整理好的DataFrame。定義一些常用變數,大多為欄位名及其組合:
adult_occupant_columns = [
"Frontal Impact",
"Lateral Impact",
"Rear Impact",
"Rescue and Extrication",
]
child_occupant_columns = [
"Crash Test Performance",
"Safety Features",
"CRS Installation Check",
]
vulnerable_road_users_columns = ["VRU Impact Protection", "VRU Impact Mitigation"]
safety_assist_columns = [
"Speed Assistance",
"Occupant Status Monitoring",
"Lane Support",
"AEB Car-to-Car",
]
testing_columns = (
adult_occupant_columns
+ child_occupant_columns
+ vulnerable_road_users_columns
+ safety_assist_columns
)
testing_groups = (
adult_occupant_columns,
child_occupant_columns,
vulnerable_road_users_columns,
safety_assist_columns,
)
testing_group_names = ("adult", "child", "vru", "assist")
testing_columns_with_rank = []
for _grp, _grp_name in zip(testing_groups, testing_group_names):
testing_columns_with_rank.extend(chain(_grp, [_grp_name]))
在實際於tweak_df()中讀入前一步驟產生的euroncap_2023.json前,我們先試著利用DataFrame.glimpse()預覽第一行的結果:
json_file = "euroncap_2023.json"
pl.read_json(json_file).head(1).glimpse()
Rows: 1
Columns: 18
$ Make <str> 'BMW'
$ Model <str> 'BMW 5 Series'
$ Class <str> 'Large Family Car'
$ Url <str> 'https://www.euroncap.com/en/results/bmw/5+series/50186'
$ Stars <str> '5'
$ Frontal Impact <str> '14.0'
$ Lateral Impact <str> '15.1'
$ Rear Impact <str> '3.5'
$ Rescue and Extrication <str> '3.0'
$ Crash Test Performance <str> '24.0'
$ Safety Features <str> '6.0'
$ CRS Installation Check <str> '12'
$ VRU Impact Protection <str> '30.1'
$ VRU Impact Mitigation <str> '24.4'
$ Speed Assistance <str> '1.8'
$ Occupant Status Monitoring <str> '1.3'
$ Lane Support <str> '3.0'
$ AEB Car-to-Car <str> '8.1'
確認可以成功讀入後,我們就可以放心在tweak_df()中使用pl.read_json()來生成DataFrame。
tweak_df()在這個函數中,我們將進行許多操作,下面一步步說明。
使用pl.read_json()來讀入euroncap_2023.json,並生成df DataFrame。
def tweak_df(json_file: str) -> pl.DataFrame:
df = pl.read_json(json_file)
...
「"Make"」欄的目標是組合一個本地路徑,希望可以透過GT.fmt_image()來顯示各車商的logo(註4)。
其中我們使用了Polars的pl.when().then().otherwise()語法(Polars的if, elif, ...else)
來判斷該路徑所需使用的副檔名。
logo_path = Path("logo")
def tweak_df(json_file: str) -> pl.DataFrame:
...
_make = pl.col("Make").str.to_lowercase()
logo_pngs = [l.stem for l in logo_path.glob("*png")]
make = (
pl.when(_make.is_in(logo_pngs))
.then(_make.add(".png"))
.otherwise(_make.add(".jpg"))
)
「"Model"」欄的目標是組合一個Markdown格式的URL,來顯示資料出處。
這裡我們實作了一個cols_merge_as_str()函數(註5),希望當傳入參數為Polars expression時,可以自動轉換欄位為pl.Utf8型別;當傳入參數為Python的str型別時,可以自動加上pl.lit()。
def _str_exprize(elem: str | pl.Expr) -> pl.Expr:
if isinstance(elem, pl.Expr):
return elem.cast(pl.Utf8)
return pl.lit(str(elem))
def cols_merge_as_str(*elems: pl.Expr | str, alias: str = "merged_col") -> pl.Expr:
if not elems:
raise ValueError("At least one str or Polars expression must be provided.")
cols = None
for elem in elems:
if cols is None:
cols = _str_exprize(elem)
continue
cols = cols.add(_str_exprize(elem))
return cols.alias(alias)
def tweak_df(json_file: str) -> pl.DataFrame:
...
model = cols_merge_as_str(
"[", pl.col("Model"), "](", pl.col("Url"), ")", alias="Model"
)
在「"Stars"」欄最後加上emogi符號「"⭐"」,代表星等。
def tweak_df(json_file: str) -> pl.DataFrame:
...
stars = pl.col("Stars").add("⭐")
此處定義一個grps變數,為一generator,會在之後的context中作用。其功用是使用pl.sum_horizontal()針對四種測試類別,分別求得各自總分。
這邊需留意的是pl.sum_horizontal()這類型以行為主的函數,是Polars特別開發用以提升計算速度的,這比以迴圈針對各行進行操作,要來得快速許多。
def tweak_df(json_file: str) -> pl.DataFrame:
...
grps = (
pl.sum_horizontal(grp).alias(grp_name)
for grp, grp_name in zip(testing_groups, testing_group_names)
)
此處定義一個sub_ranks變數,為一generator,會在之後的context中作用。其功用是使用pl.Expr.rank()針對上面grps產生的四類測試總分欄,進行排序。
我們將pl.Expr.rank()的method參數設為「"min"」(可能會有同分的情況,此時將以最小排名來取值),且因為分數越高,其排名應該越高,故將descending參數設為True。
def tweak_df(json_file: str) -> pl.DataFrame:
...
sub_ranks = (
pl.col(grp_name).rank("min", descending=True).cast(pl.UInt8)
for grp_name in testing_group_names
)
此處定義一個rank變數,為一generator,會在之後的context中作用。其功用是使用pl.mean_horizontal()針對四種測試類別的排名,求得平均排名後,再使用pl.Expr.rank()進行排序。
pl.Expr.rank()的method參數一樣設為「"min"」,但是因為排名越低代表表現越好,故將descending參數設為False。
def tweak_df(json_file: str) -> pl.DataFrame:
...
rank = (
pl.mean_horizontal(testing_group_names)
.rank("min", descending=False)
.cast(pl.UInt8)
.alias("Rank")
)
tweak_df()最後我們將上述定義的Polars expression(以generator型式暫存於變數中)及欄位名,放在適當的context中產生作用(如DataFrame.with_columns()或DataFrame.select()等)。過程中有使用DataFrame.sort()來整理各欄排序。
def tweak_df(json_file: str) -> pl.DataFrame:
...
return (
df.with_columns(pl.col(testing_columns).cast(pl.Float64))
.with_columns(model, make, stars, *grps)
.with_columns(sub_ranks)
.with_columns(rank)
.sort(
"Class",
"Rank",
*testing_group_names,
descending=[True, False] + [False] * len(testing_group_names),
)
.select(
chain(
("Class", "Model", "Make", "Stars", "Rank"), testing_columns_with_rank
)
)
)
tweak_df()全貌此處我們列出tweak_df()的全部過程,作為參考。
logo_path = Path("logo")
def _str_exprize(elem: str | pl.Expr) -> pl.Expr:
if isinstance(elem, pl.Expr):
return elem.cast(pl.Utf8)
return pl.lit(str(elem))
def cols_merge_as_str(*elems: pl.Expr | str, alias: str = "merged_col") -> pl.Expr:
"""
Parameters
----------
elems
str or Polars expressions.
alias
alias for the final Polars expressions.
Returns:
----------
pl.Expr
Polars expressions
"""
if not elems:
raise ValueError("At least one str or Polars expression must be provided.")
cols = None
for elem in elems:
if cols is None:
cols = _str_exprize(elem)
continue
cols = cols.add(_str_exprize(elem))
return cols.alias(alias)
def tweak_df(json_file: str) -> pl.DataFrame:
df = pl.read_json(json_file)
_make = pl.col("Make").str.to_lowercase()
logo_pngs = [l.stem for l in logo_path.glob("*png")]
make = (
pl.when(_make.is_in(logo_pngs))
.then(_make.add(".png"))
.otherwise(_make.add(".jpg"))
)
model = cols_merge_as_str(
"[", pl.col("Model"), "](", pl.col("Url"), ")", alias="Model"
)
stars = pl.col("Stars").add("⭐")
grps = (
pl.sum_horizontal(grp).alias(grp_name)
for grp, grp_name in zip(testing_groups, testing_group_names)
)
sub_ranks = (
pl.col(grp_name).rank("min", descending=True).cast(pl.UInt8)
for grp_name in testing_group_names
)
rank = (
pl.mean_horizontal(testing_group_names)
.rank("min", descending=False)
.cast(pl.UInt8)
.alias("Rank")
)
return (
df.with_columns(pl.col(testing_columns).cast(pl.Float64))
.with_columns(model, make, stars, *grps)
.with_columns(sub_ranks)
.with_columns(rank)
.sort(
"Class",
"Rank",
*testing_group_names,
descending=[True, False] + [False] * len(testing_group_names),
)
.select(
chain(
("Class", "Model", "Make", "Stars", "Rank"), testing_columns_with_rank
)
)
)
df = tweak_df(json_file)
註1:此表為小弟參加今年 Posit table contest的參賽作品,您可以在此連結閱讀英文製表流程說明,並在此連結觀看成果。此外,製表過程中可能會有錯誤,請勿以此表為購車依據。
註2:所有數據皆手動取自Euro NCAP官方網站,並未使用爬蟲。舉例來說,2023年的BMW 5 Series資料可以在這個連結中找到。
註3:其使用的Polars版本為0.20.31,故JSON輸出格式現在的略有不同。如果改使用新版本DataFrame.write_json()輸出結果來作為DataFrame.read_json()的輸入,則euroncap_2023.ipynb仍可正常執行。
註4:車商logo取自Euro NCAP官方網站,並存於此repo中的logo資料夾。
註5:依照使用習慣,或許您會覺得pl.concat_str()更加好用。


 iThome鐵人賽
iThome鐵人賽