在 LlamaIndex🦙 中,Indexing 模組是一個關鍵的組件,負責組織和存儲來自不同數據來源的資訊,以便更有效地進行檢索。這個模組的核心是節點(Node),每個 Node 都是一個包含文本的資料結構。當用戶提供一個文件時,該文件會被切割成多個片段,並存儲在這些 Node 中,這樣可以提高查詢的靈活性和準確性。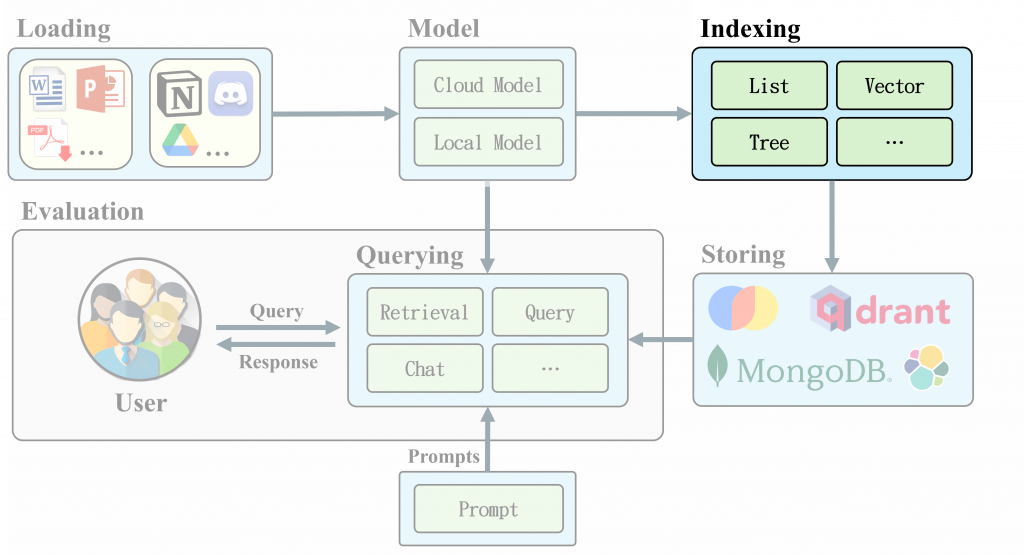
LlamaIndex 支持多種索引類型,每種索引都有其特定的用途和特點:
Summary(List)Index📜:索引將 Node 以鏈表的形式存儲,並可以通過基於 Embedding 方式查詢獲取相關的 Nodes 或使用關鍵字過濾器進行查詢。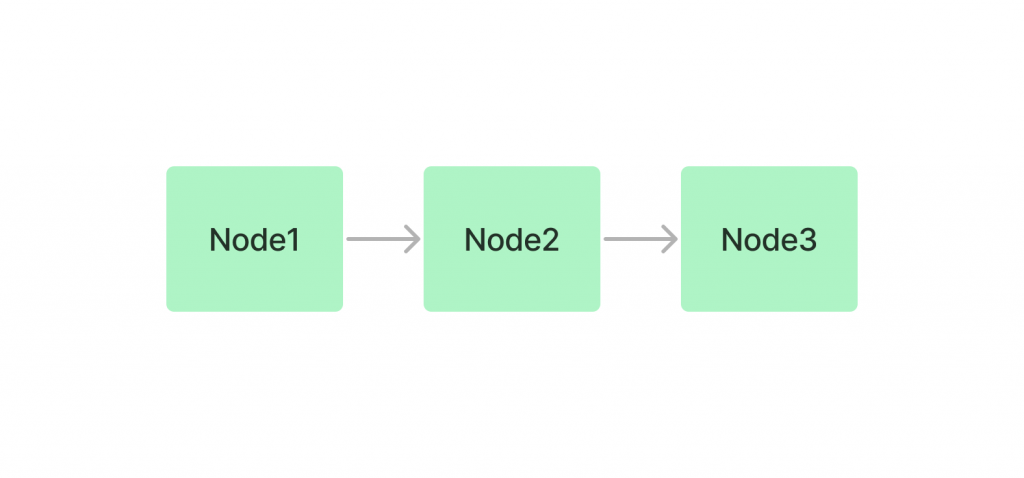
查詢時如果沒有指定其他查詢參數,LlamaIndex 將會返回 List 中的所有 Node 至 Querying 模組。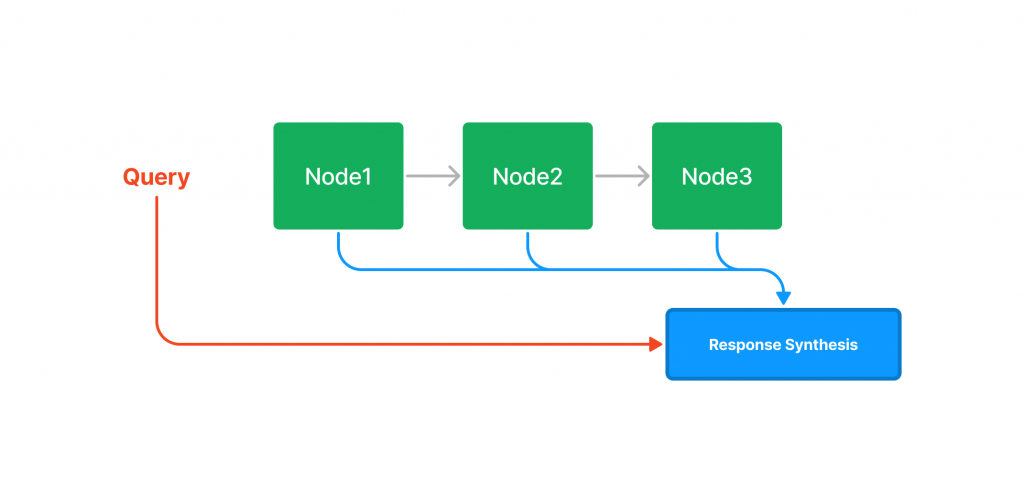
from llama_index.core import SummaryIndex, Document
index = SummaryIndex([])
text_chunks = [
"台北是台灣的首都,也是台灣政治、經濟、文化和交通的中心。這座城市充滿了活力與多元文化,結合了現代與傳統的魅力。台北擁有世界知名的地標——台北101,它曾是全球最高的摩天大樓,並且是購物和觀光的熱門地點。此外,台北還有許多文化和歷史景點,如故宮博物院、龍山寺和中正紀念堂,吸引了大量國內外遊客。台北市內交通便捷,捷運系統發達,是探索這座都市的絕佳方式。這裡也是台灣美食的集中地,夜市文化如士林夜市、饒河街夜市更是不可錯過的體驗之一。",
"新竹被譽為「風城」,因為當地的強風而得名。它位於台灣的西北部,距離台北約一小時車程。新竹是台灣高科技產業的重要基地,特別是以竹科(新竹科學園區)而聞名,是台灣的“矽谷”。新竹擁有良好的教育環境,著名的清華大學與交通大學皆位於此地。雖然新竹給人現代化的高科技城市印象,但它同時保留了豐富的歷史文化資產,如新竹城隍廟、新竹市東門城等。當地的風味小吃,如米粉和貢丸湯,也深受遊客喜愛,是品嚐道地台灣味的好去處。",
"台中位於台灣中部,氣候溫暖,擁有台灣第三大城市的規模。它以文化氣息濃厚著稱,擁有豐富的藝術與文化活動,如國立台灣美術館、霧峰林家花園等。台中還是熱門的觀光景點之一,尤其以彩虹眷村和高美濕地最為著名。此外,台中市還以舒適的生活環境和悠閒的生活步調著稱,常被視為居住和發展的理想城市。台中的夜市文化也相當發達,逢甲夜市是其中最具代表性的夜市之一,吸引了無數美食愛好者前來品嚐台灣各地的美食",
"台南是台灣最古老的城市,也是台灣的文化和歷史重鎮,擁有豐富的歷史遺跡和古蹟。作為台灣的發源地,台南保存了大量具有歷史價值的建築物,如赤崁樓、安平古堡和延平郡王祠。這座城市還以其宗教文化著名,每年都有多場盛大的廟會活動,如媽祖遶境、五廟祭典等,吸引大量信徒參與。台南同時也是美食天堂,台南小吃如擔仔麵、碗粿和牛肉湯聞名全台。台南擁有獨特的歷史氛圍與人文風情,讓每個造訪者都能感受到濃厚的古早味。",
"高雄是台灣的南部最重要的港口城市。高雄港是世界最繁忙的貨運港之一,帶動了當地的經濟發展。高雄市內的交通便捷,擁有輕軌和捷運系統,讓市民和遊客都能方便地遊覽這座城市。高雄的著名景點包括蓮池潭、打狗英國領事館、六合夜市等,是旅遊和購物的好地方。此外,旗津半島也是高雄知名的觀光勝地,以海灘、美食和古蹟著稱。高雄擁有豐富的自然景觀和現代化的都市建設,結合了傳統與現代的多元風貌。"]
metadata_chunks = ['台北', '新竹', '台中', '台南', '高雄']
doc_chunks = []
for i, text in enumerate(text_chunks):
doc = Document(
text=text,
id_=f"doc_id_{i}",
metadata={"city": metadata_chunks[i]})
doc_chunks.append(doc)
# insert
for doc_chunk in doc_chunks:
index.insert(doc_chunk)
print(index.ref_doc_info)
# Output [1]: {'doc_id_0': RefDocInfo(node_ids=['0a411f35-aa4d-459e-b769-bdf208e69c83'], metadata={'city': '台北'}),
'doc_id_1': RefDocInfo(node_ids=['2919cb1c-11bb-4ac0-96d1-76da7c739dbb'], metadata={'city': '新竹'}),
'doc_id_2': RefDocInfo(node_ids=['41daa0b0-f564-448c-a686-6f2d099b2d18'], metadata={'city': '台中'}),
'doc_id_3': RefDocInfo(node_ids=['e5a74c74-19f6-4da7-b0c6-c0556746be06'], metadata={'city': '台南'}),
'doc_id_4': RefDocInfo(node_ids=['794cdc1a-42ee-43e8-a98f-2c84d5b70fbb'], metadata={'city': '高雄'})}
Vector Store Index🔢:索引將每個 Nodes 及其對應的 Embedding Vector 存儲在向量庫中。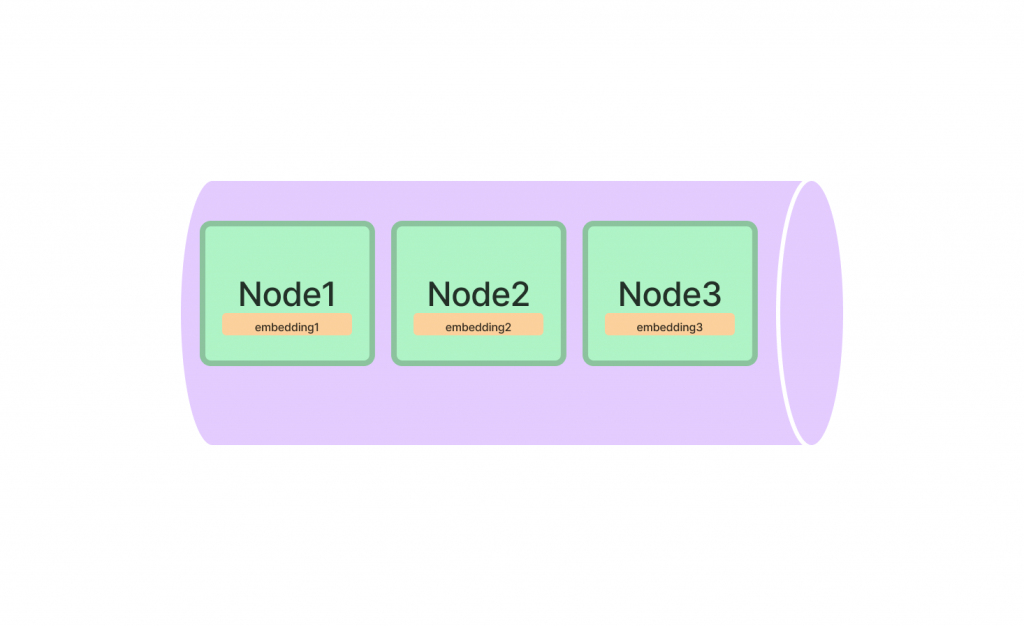
查詢時會提供與查詢最相關的前k個最相似的 Nodes ,適合高效檢索的應用。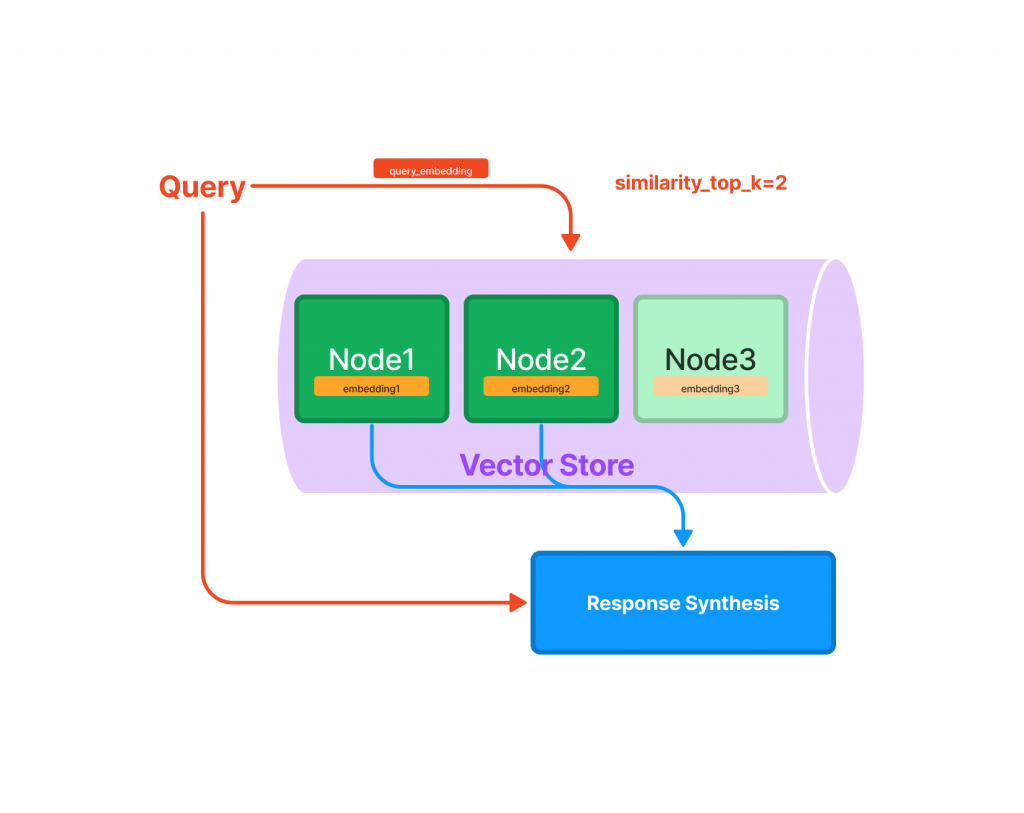
你也可以替換 OpenAI Embedding 就不需輸入 API KEY 。雖然印出來的 Nodes 看起來一樣,但可以進一步去模組內查看底層多儲存了 Embedding Vector ,在未來檢索階段時會跟 List 有不一樣的效果。
import os
os.environ["OPENAI_API_KEY"] = "your-api-key"
from llama_index.core import Document, VectorStoreIndex
# Create document
text_chunks = [
"台北是台灣的首都,也是台灣政治、經濟、文化和交通的中心。這座城市充滿了活力與多元文化,結合了現代與傳統的魅力。台北擁有世界知名的地標——台北101,它曾是全球最高的摩天大樓,並且是購物和觀光的熱門地點。此外,台北還有許多文化和歷史景點,如故宮博物院、龍山寺和中正紀念堂,吸引了大量國內外遊客。台北市內交通便捷,捷運系統發達,是探索這座都市的絕佳方式。這裡也是台灣美食的集中地,夜市文化如士林夜市、饒河街夜市更是不可錯過的體驗之一。",
"新竹被譽為「風城」,因為當地的強風而得名。它位於台灣的西北部,距離台北約一小時車程。新竹是台灣高科技產業的重要基地,特別是以竹科(新竹科學園區)而聞名,是台灣的“矽谷”。新竹擁有良好的教育環境,著名的清華大學與交通大學皆位於此地。雖然新竹給人現代化的高科技城市印象,但它同時保留了豐富的歷史文化資產,如新竹城隍廟、新竹市東門城等。當地的風味小吃,如米粉和貢丸湯,也深受遊客喜愛,是品嚐道地台灣味的好去處。",
"台中位於台灣中部,氣候溫暖,擁有台灣第三大城市的規模。它以文化氣息濃厚著稱,擁有豐富的藝術與文化活動,如國立台灣美術館、霧峰林家花園等。台中還是熱門的觀光景點之一,尤其以彩虹眷村和高美濕地最為著名。此外,台中市還以舒適的生活環境和悠閒的生活步調著稱,常被視為居住和發展的理想城市。台中的夜市文化也相當發達,逢甲夜市是其中最具代表性的夜市之一,吸引了無數美食愛好者前來品嚐台灣各地的美食",
"台南是台灣最古老的城市,也是台灣的文化和歷史重鎮,擁有豐富的歷史遺跡和古蹟。作為台灣的發源地,台南保存了大量具有歷史價值的建築物,如赤崁樓、安平古堡和延平郡王祠。這座城市還以其宗教文化著名,每年都有多場盛大的廟會活動,如媽祖遶境、五廟祭典等,吸引大量信徒參與。台南同時也是美食天堂,台南小吃如擔仔麵、碗粿和牛肉湯聞名全台。台南擁有獨特的歷史氛圍與人文風情,讓每個造訪者都能感受到濃厚的古早味。",
"高雄是台灣的南部最重要的港口城市。高雄港是世界最繁忙的貨運港之一,帶動了當地的經濟發展。高雄市內的交通便捷,擁有輕軌和捷運系統,讓市民和遊客都能方便地遊覽這座城市。高雄的著名景點包括蓮池潭、打狗英國領事館、六合夜市等,是旅遊和購物的好地方。此外,旗津半島也是高雄知名的觀光勝地,以海灘、美食和古蹟著稱。高雄擁有豐富的自然景觀和現代化的都市建設,結合了傳統與現代的多元風貌。"]
metadata_chunks = ['台北', '新竹', '台中', '台南', '高雄']
documents = []
for i, text in enumerate(text_chunks):
doc = Document(
text=text,
id_=f"doc_id_{i}",
metadata={"city": metadata_chunks[i]})
documents.append(doc)
# Indexing
index = VectorStoreIndex.from_documents(documents)
print(index.ref_doc_info)
# Output [1]: {'doc_id_0': RefDocInfo(node_ids=['0a411f35-aa4d-459e-b769-bdf208e69c83'], metadata={'city': '台北'}),
doc_id_1': RefDocInfo(node_ids=['2919cb1c-11bb-4ac0-96d1-76da7c739dbb'], metadata={'city': '新竹'}),
'doc_id_2': RefDocInfo(node_ids=['41daa0b0-f564-448c-a686-6f2d099b2d18'], metadata={'city': '台中'}),
'doc_id_3': RefDocInfo(node_ids=['e5a74c74-19f6-4da7-b0c6-c0556746be06'], metadata={'city': '台南'}),
'doc_id_4': RefDocInfo(node_ids=['794cdc1a-42ee-43e8-a98f-2c84d5b70fbb'], metadata={'city': '高雄'})}
Keyword Table Index🗂️:此索引專注於從 Nodes 中提取關鍵字,並利用這些關鍵字查找相關文檔。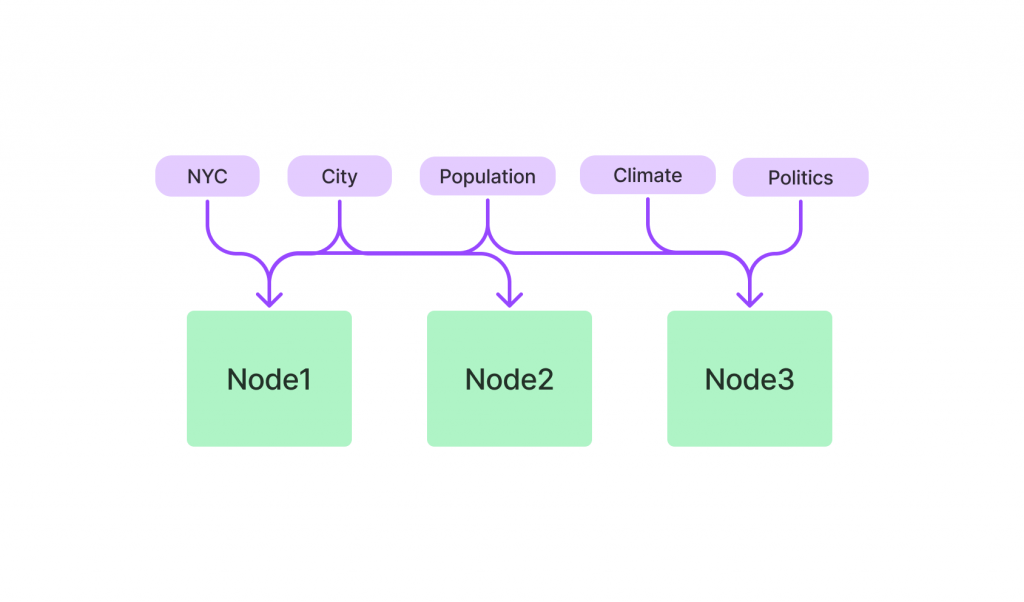
當用戶提出問題時,系統首先生成關鍵字,然後搜索相關文檔並將相關文檔傳送至 Querying 模組。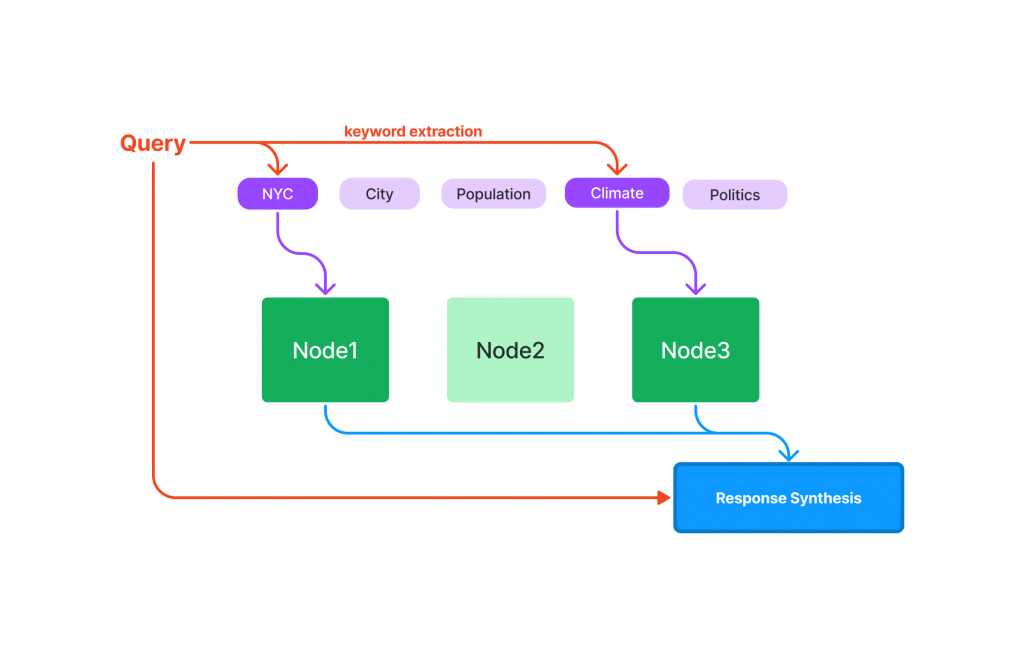
因為 LlamaIndex 是使用 OpenAI LLM 提取關鍵字,因此需要輸入 API KEY。預設使用的Prompt如下:
Some text is provided below. Given the text, extract up to {max_keywords} keywords from the text. Avoid stopwords.
---------------------
{text}
---------------------
Provide keywords in the following comma-separated format: 'KEYWORDS: <keywords>'
# Code
import os
os.environ["OPENAI_API_KEY"] = "your-api-key"
from llama_index.core import Document, KeywordTableIndex
# Create document
...
# Indexing
index = KeywordTableIndex.from_documents(documents)
print(index.ref_doc_info)
# Output[1]: {'doc_id_4': RefDocInfo(node_ids=['60522352-084a-4fda-af1d-7cf9abfa984d'], metadata={'city': '高雄'}),
'doc_id_0': RefDocInfo(node_ids=['22ea5acf-65b7-4409-8f09-a076e76670fc'], metadata={'city': '台北'}),
'doc_id_3': RefDocInfo(node_ids=['2bb90b4e-1ae0-4f64-bd93-f0c42149ce4d'], metadata={'city': '台南'}),
'doc_id_1': RefDocInfo(node_ids=['236dedaf-d2e8-4fbb-84ff-dfc306fb9f5d'], metadata={'city': '新竹'}),
'doc_id_2': RefDocInfo(node_ids=['c2ce0b99-4265-46c6-98d1-e2ff079e14b6'], metadata={'city': '台中'})}
target_value = '22ea5acf-65b7-4409-8f09-a076e76670fc' # 台北 node_ids
keyword_ls = [key for key, value in index.index_struct.table.items() if target_value in value]
print(keyword_ls)
# Output[2]: ['中正紀念堂', '觀光', '台北101', '政治', '首都', '捷運系統', '購物', '美食', '夜市文化', '故宮博物院', '台北', '交通便捷', '交通', '龍山寺', '經濟', '文化']
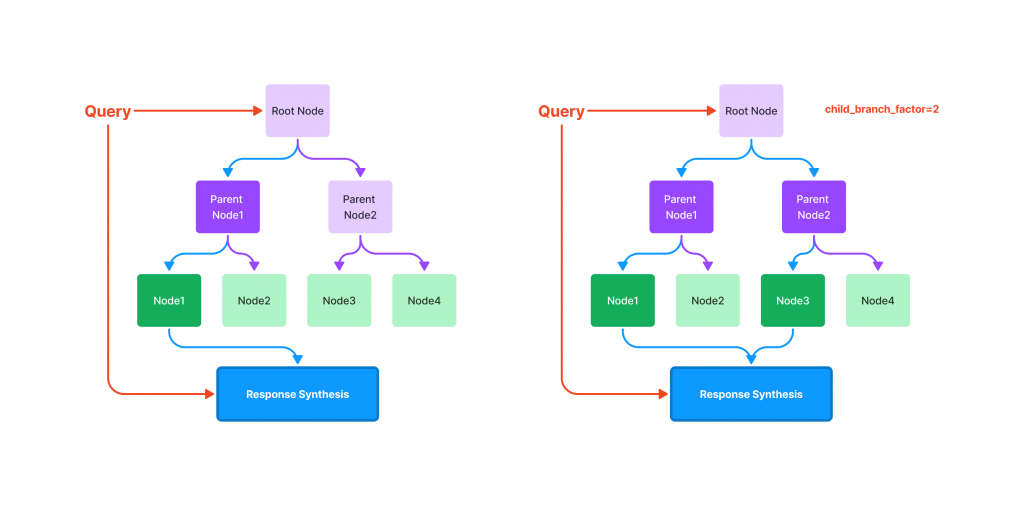
Tree Index🌳:樹形索引通過將 Nodes 組織成一個分層的樹狀結構來工作。每個父節點是其下方節點的摘要,查詢過程從根節點向下進行,這樣的結構能夠有效地管理和檢索大量數據。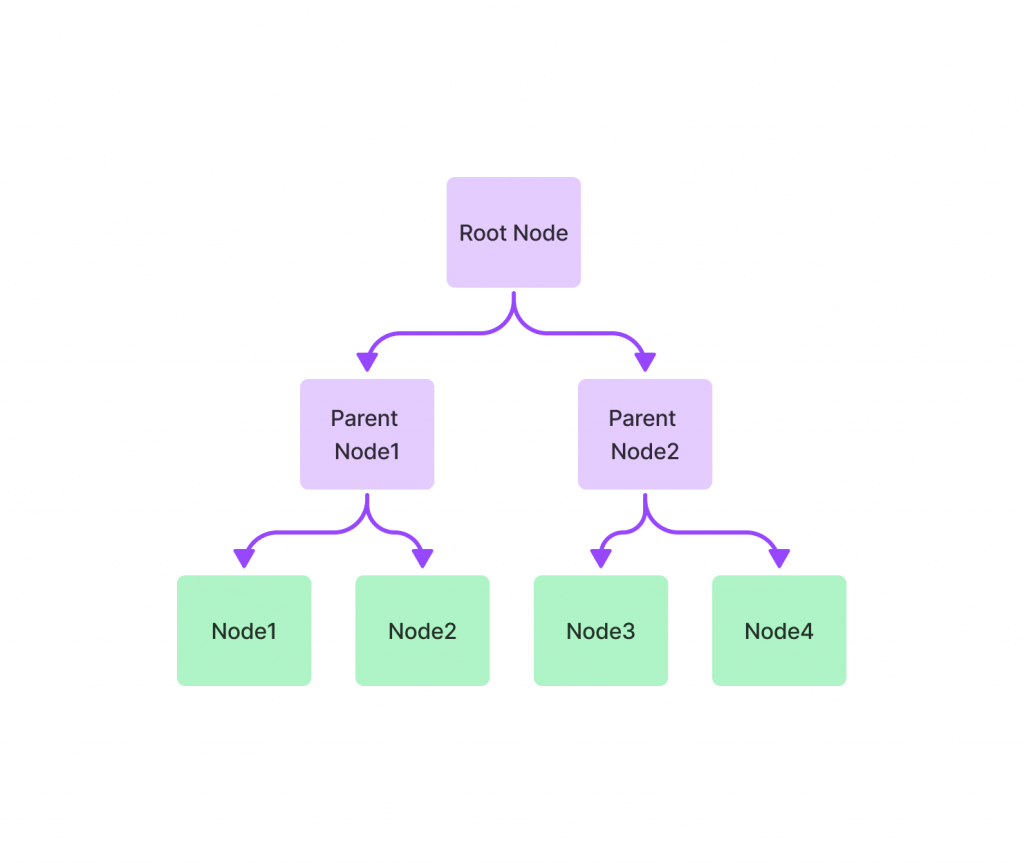
Knowledge Graph Index🧠:這個索引通過自動提取文本中的實體和關係來簡化知識圖的構建,並提供了靈活性以便根據特定需求定制圖形結構和推理規則。知識圖能夠捕捉實體之間的豐富關係,增強了資料檢索的能力。
import nest_asyncio
nest_asyncio.apply()
from llama_index.core import PropertyGraphIndex
# Create document
...
# create
index = PropertyGraphIndex.from_documents(
documents
)
LlamaIndex 的 Indexing 模組在需要快速檢索特定領域知識的應用中表現出色,尤其是在客戶服務或專業知識查詢方面。透過將資料轉換成向量並進行高效索引,該系統能夠在用戶提問時迅速找到最相關的資訊,從而提升了回應的準確性並有效降低了查詢的時間成本。這種高效的檢索能力不僅能夠滿足用戶對於迅速回應的需求,也在日益複雜的數據環境中提供了穩定的解決方案。

