在機器學習的開發過程中,選擇適當的演算法只是其中的一部分。模型的成功與否,很大程度上取決於如何正確地評估其性能📊。無論模型看起來多麼完美,如果沒有正確的評估方法,就無法確定它在實際應用中的表現📉。模型評估不僅影響模型的選擇,還對模型的優化和改進有著很大的影響。不同類型的任務,如回歸、分類、聚類和降維,適用的評估方法和指標各不相同。我們曾提到數據拆分的概念,訓練集用於學習📖,驗證集則在調整模型時進行性能評估,幫助選擇最佳配置,測試集則用來檢驗模型的泛化能力。接下來,我們將介紹各類問題中的常見評估指標。在今明兩天文章中,我們將介紹在不同類型的問題中各自常見的評估指標:
分類問題是指根據樣本的特徵將其歸類到預定的類別中。常見的評估指標包括:
準確率(Accuracy)= (TP + TN) / (TP + TN + FP + FN)
精確率(Precision)= TP / (TP + FP)
召回率(Recall)或敏感度(Sensitivity)= TP / (TP + FN)
特異度(Specificity)= TN / (TN + FP)
F1 分數 = 2 * (Precision * Recall) / (Precision + Recall)
舉例來說,下面這個混淆矩陣告訴我們,在 200 位患者中,模型正確識別了 90 位正常人和 95 位患病者,但也將 10 位正常人誤判為患病,5 位患病者誤判為正常。模型的敏感度(正確識別患病者的能力)為 95%,特異度(正確識別正常人的能力)為 90%,整體準確率為 92.5%。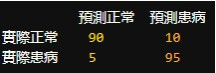
通過分析這些數值,我們可以更全面地理解模型的性能,特別是在處理不平衡數據集時。例如,在罕見疾病診斷中,我們可能更關注召回率(避免漏診)而非精確率。而在垃圾郵件過濾中,我們可能更注重精確率(避免將重要郵件誤判為垃圾郵件)。
當我們評估分類模型時,Type I Error(第一型錯誤)和 Type II Error(第二型錯誤)是常見的概念,它們描述了模型在預測過程中可能出現的錯誤類型。在模型設計和評估過程中,我們通常需要在 Type I Error 和 Type II Error 之間找到一個平衡點。這取決於具體的應用場景:
了解 Type I Error 和 Type II Error 可以幫助我們更好地設計和調整模型,以達到所需的預測準確性和可靠性。Type I Error 和 Type II Error 並非單純是一個專有名詞解釋,這些「明明事實是A,我們卻誤以為是B」的錯誤也是可能發生在我們生活中的任何時候,如:
[source]
在這篇文章中,我們探討了分類問題中常見的評估指標。理解它們的應用場景和限制,有助於我們在實際應用中選擇和調整模型。在下一篇文章中,我們將深入探討回歸、聚類和降維問題的評估指標,以及如何進行模型比較,進一步提升模型性能。


 iThome鐵人賽
iThome鐵人賽