在ChatGPT出世之前(~2020),以前的語言模型(LM,Language Model)參數量不夠多,
相比LLAMA3、GPT4的70B、175B,T5-Large,甚至是GPT2-Large大概只有800M的參數大小而已。
在LLM百家爭鳴前,超過1B的LM真的屈指可數(圖中的GPT-2為Extra Large,T5為T5-XXL)
一旦參數大小不夠大,語言模型就無法處理複雜的語意,
就會造成語言模型無法進行多輪(Multi-turn)、多語言(Multilingual)或多模態(Multi-moda)
這種較複雜的對話任務。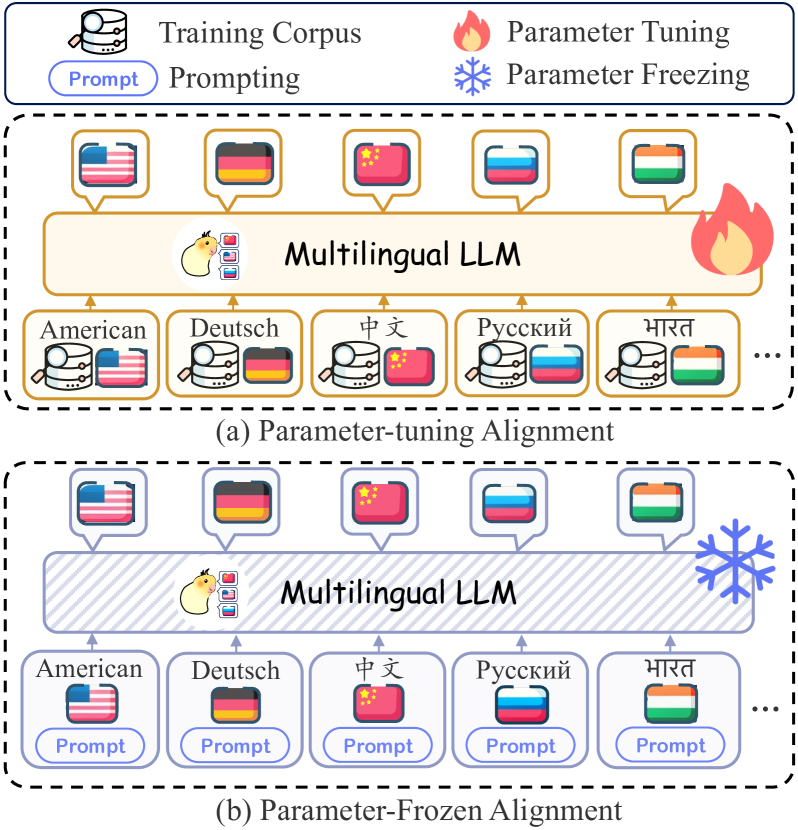
像ChatGPT就是一個能聽的懂多國語言的Multilingual LLMs,要如何依據多個語言做正確的生成仍是個挑戰。
就算使用大數據、強化學習等技巧去訓練,語言模型的回覆也不盡理想
而過去也沒有使用RLHF這種較進階的強化學習技巧,也讓模型的生成有所受限。
過去Chatbot最常回覆I'm don't know.或I'm sorry等短句,因為這樣所受到的誤差最小XD
GAN為使用強化學習及對抗生成的方式產生的回覆
為了要讓比較小的模型也能處理聊天任務,過去將聊天任務分為Chit-chat和Task-oriented二種。
Chit-chat為閒聊式對話,顧名思義就是個普通的聊天機器人,希望回覆符合使用者的上下文。
而Task-oriented為任務導向式對話,目的希望能解決使用者的需求或回覆。
在圖中,前面是聊關於小孩的閒聊式對話,後面是做電影推薦的任務導向式對話。
下一篇我會介紹ChatGPT的祖先-DialoGPT,一個專門跟使用者閒聊的Chatbot。
Reference.
How to Harness the Predictive Power of GPT-J
李宏毅-Improving Sequence Generation by GAN
Adversarial Ranking for Language Generation
Multilingual Large Language Model: A Survey of Resources, Taxonomy and Frontiers
SalesBot: Transitioning from Chit-Chat to Task-Oriented Dialogues

