還記得我們前面介紹的NLU和DST嗎?
它們就像是Chatbot的耳朵和大腦,幫助它理解和記憶對話內容。
但是,一個真正優秀的對話者不僅要會聽,還要懂得如何制定戰略,在對話中攻守自如。這就是我們今天要介紹的DPL(Dialogue Policy Learning)!
想象一下,你走進一家餐廳,跟服務生說:「我想吃些清淡的。」
沒有DPL的Chit-chat Chatbot可能會直接推薦沙拉,甚至會直接問你「你怎麼了?」、「是想要減肥嗎?」等閒聊式對話。這些對話,雖然有達成連貫性,但卻沒辦法完成用戶的需求。
在任務導向對話中,我們希望Chatbot能依據我們的建議來為我們點餐或完成訂位
而DPL就不同了,它會依據資料庫查詢的結果,來決定如何回覆。
我們一樣以「我想吃些清淡的。」做舉例,
若DST認為清淡是重要資訊,DPL會將清淡進行查詢,並將查詢結果視為一對話狀態,
最後決定要回覆的意圖,並與查詢的結果進行合併輸出。
在我看來,過去的DPL其實跟現在LLM常用的檢索生成(Retrieval Augmented Generation,RAG)很類似,差別是RAG使用Embedding來做資料庫搜索,而DPL則大多使用傳統資料庫檢索。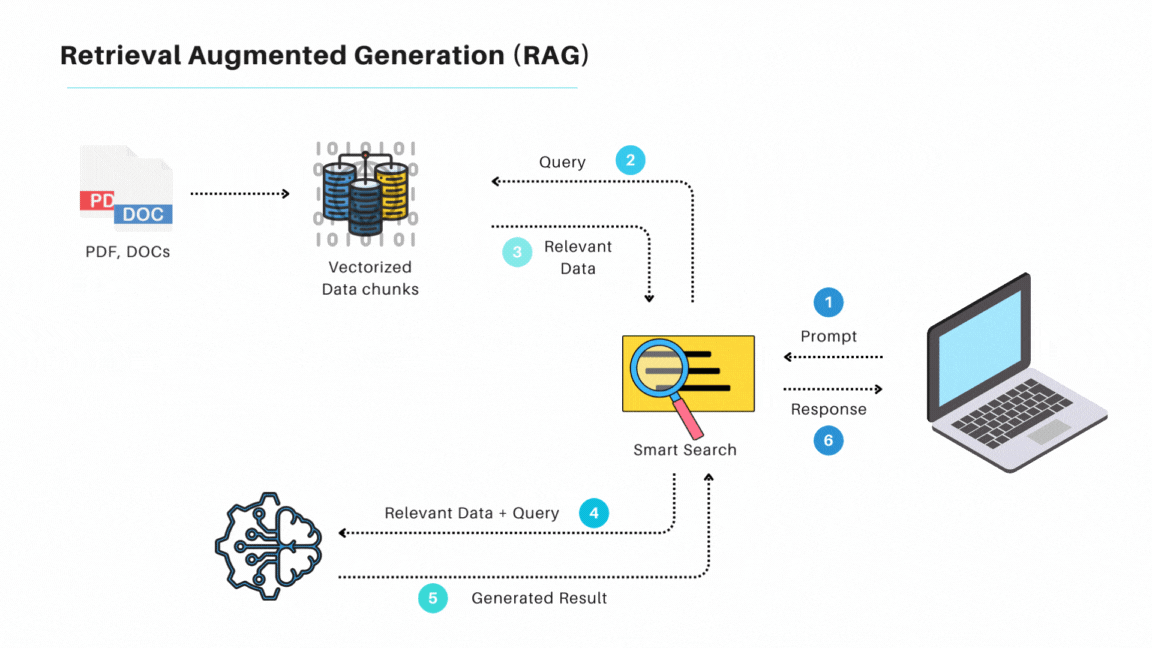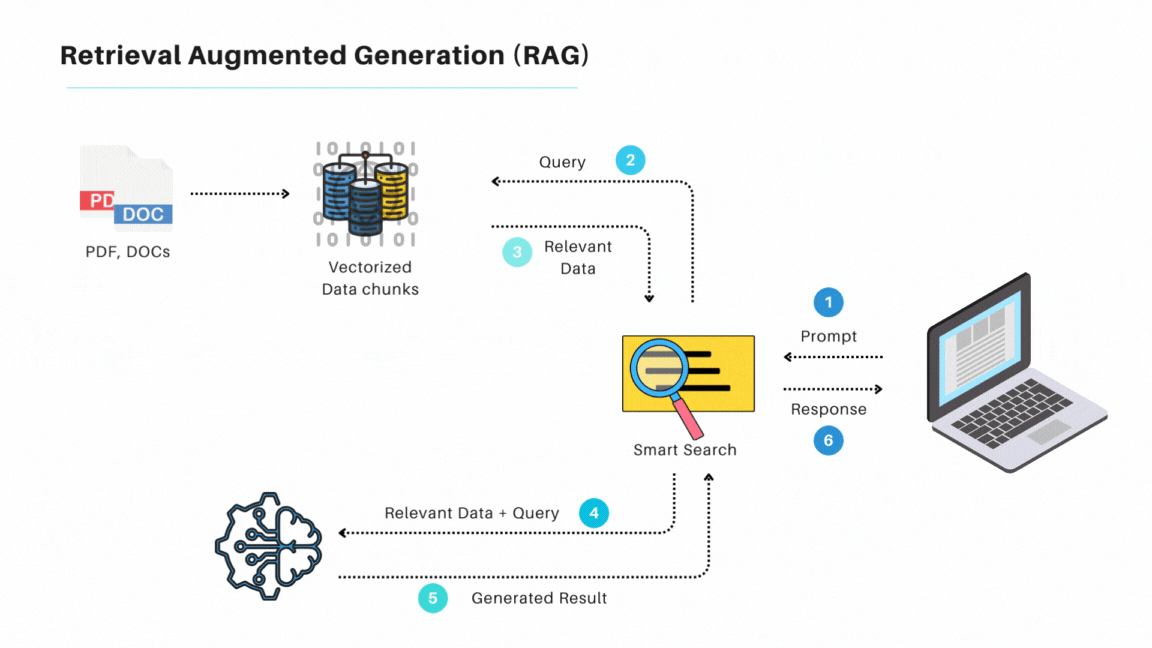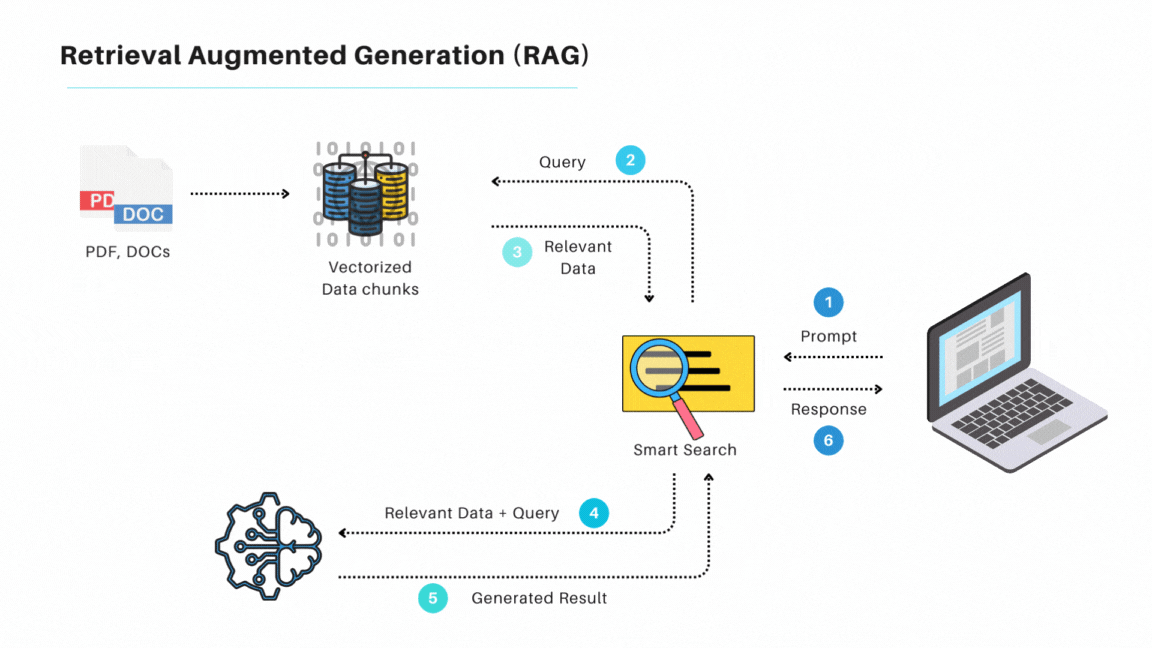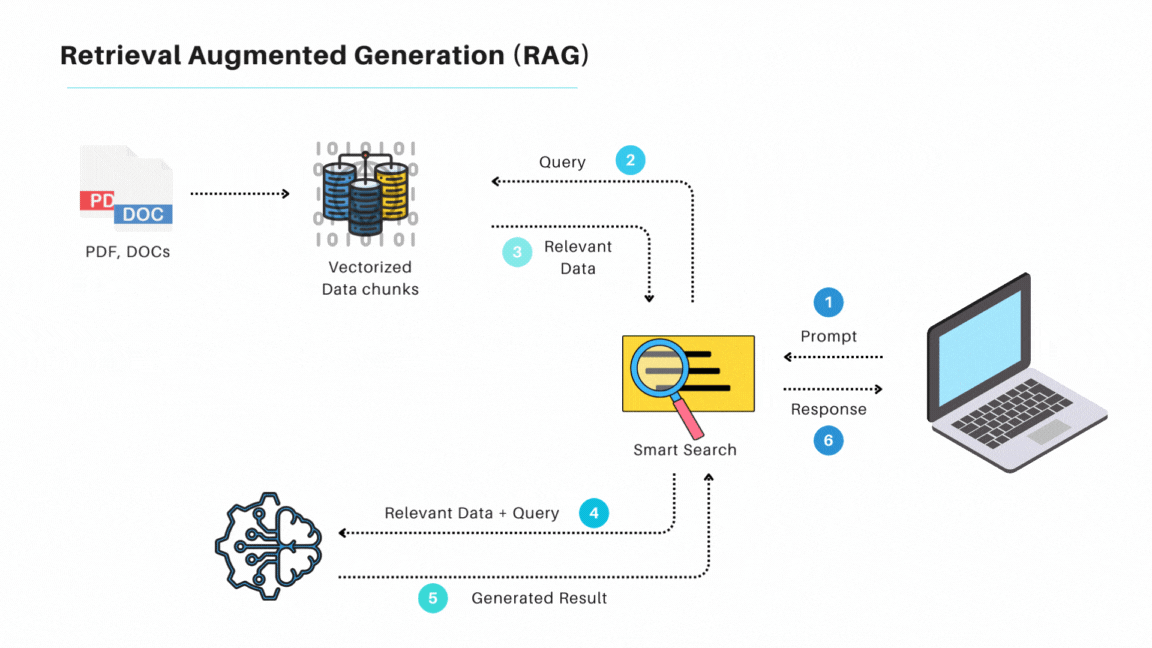
明天,我們來實作幾種DPL方法。
Reference.
A Deep Dive into Retrieval Augmented Generation (RAG)

