今天我們要以規則式(rule-based)來建構一個對話模擬器。
模擬當使用者跟Chatbot溝通時,如何不使用任何深度學習模型來決定如何回覆。
所以我們不廢話了,我們以crossWOZ為例,直接上rule-based DPL範例程式碼rule_simulator.py:
在rule_simulator.py中,對話模擬是通過定義一組規則來實現的。這些規則通常包括:
form convlab.policy.rule.crosswoz.rule_simulator import Simulator
from pprint import pprint
if __name__ == '__main__':
simulator = Simulator() # 初始化模擬器
simulator.init_session() # 與DST相同,初始化對話狀態欄、對話目標
pprint(simulator.goal) # 對話目標,在rule-based為隨機產生
# 依據話語者意圖來決定回覆意圖
pprint(simulator.predict([['Inform','酒店','名称','北京首都宾馆']]))
pprint(simulator.state) # 在這的對話狀態即為對話目標
看起來使用上一樣簡單,那我們來說明Simulator類別如何以規則建立進行對話模擬:
goal_generator.generate()其實就是檢視目前Chatbot與使用者談到什麼話題(領域),
並將該話題有什麼資訊(槽)當作目標goal及對話狀態state
def init_session(self, goal=None, state=None, turn_num=0, da_seq=list()):
self.goal = self.goal_generator.generate() if not goal else goal
self.goal_type = self.infer_goal_type(self.goal) # 確定話題是不是多領域的
self.original_goal = deepcopy(self.goal) # 初始目標,會因為不斷對談而改變
# 初始化對話狀態,即DPL應該要達到的目標
self.state = deepcopy(self.goal) if not state else state
self.sub_goals = [None]+[[] for _ in range(self.goal[-1][0])]
for t in self.goal:
sub_goal_id = t[0]
self.sub_goals[sub_goal_id].append(t)
self.sub_goals_state = [None] + [[] for _ in range(self.goal[-1][0])]
for t in self.state:
sub_goal_id = t[0]
self.sub_goals_state[sub_goal_id].append(t)
self.turn_num = turn_num
self.da_seq = da_seq # 初始對話行為,即第一次對話時,使用者的意圖
def predict(self, sys_act):
if self.turn_num==0: # 若還沒開始對話,隨機抽選一個打招呼的意圖
da = self.begin_da() # 以打招呼開始對話
self.turn_num+=1
self.da_seq.append(da)
return da
else:
self.da_seq.append(sys_act)
self.turn_num+=1
self.state_update(self.da_seq[-2], self.da_seq[-1])
da = self.state_predict() # 依據對話狀態去決定Chatbot的回覆
self.da_seq.append(da)
self.turn_num += 1
return da
在模擬過程中,系統會根據用戶輸入匹配相應的規則。這一過程通常涉及以下步驟:
解析用戶輸入:將用戶的語言轉換為可處理的格式。
匹配規則:即state_predict(),使用預先定義的規則集來找到最符合當前對話狀態和用戶意圖的規則。
如果找到匹配,系統將執行相應的動作,如更新槽位或生成回應。
因為規則寫的很長,所以我只貼出片段:
def state_predict(self):
if self.is_terminated():
da.append(['General', 'bye', 'none', 'none'])
return sorted(da)
else:
# 根據對話狀態去決定回覆的對話行為
for t in cur_sub_goal_state:
if not t[4]:
# have not been expressed
if t[3]:
# constraints
if isinstance(t[3], str):
if 'id' in t[3]:
ref_id = int(t[3][t[3].index('id')+3])
# 看起來很複雜,其實只是依據當前狀態決定對話行為
for x in self.sub_goals_state[ref_id]:
if x[2] == '名称':
if t[2] == '名称':
cross_constraints.append([t, ['Select', t[1], '源领域', x[1]]])
cross_constraints.append([t, ['Inform', x[1], '名称', x[3]]])
else:
cross_constraints.append([t, ['Inform', t[1], t[2], x[3]]])
break
else:
normal_constraints.append([t, ['Inform', t[1], t[2], t[3]]])
else:
for v in t[3]:
normal_constraints.append([t, ['Inform', t[1], t[2], v]])
else:
# requirements
requires.append([t, ['Request', t[1], t[2], '']])
elif not t[3]:
requires.append([t, ['Request', t[1], t[2], '']])
return sorted(da)
詳細的請到ConvLab GitHub瀏覽
但這邊有個問題:
咦?怎麼rule-based不輸入對話狀態呢? 輸入對話狀態應該會更準吧?
答案也很簡單,因為要建立新規則,會更複雜啊XD
那有沒有以transformer-based的DPL模型呢?
有的,那就是Dynamic Dialogue Policy Transformer (DDPT)!
DDPT使用CLEAR算法(Rolnick等人於2019年提出)來進行持續強化學習,
使得DDPT能夠處理多種主題並適應新的對話場景。
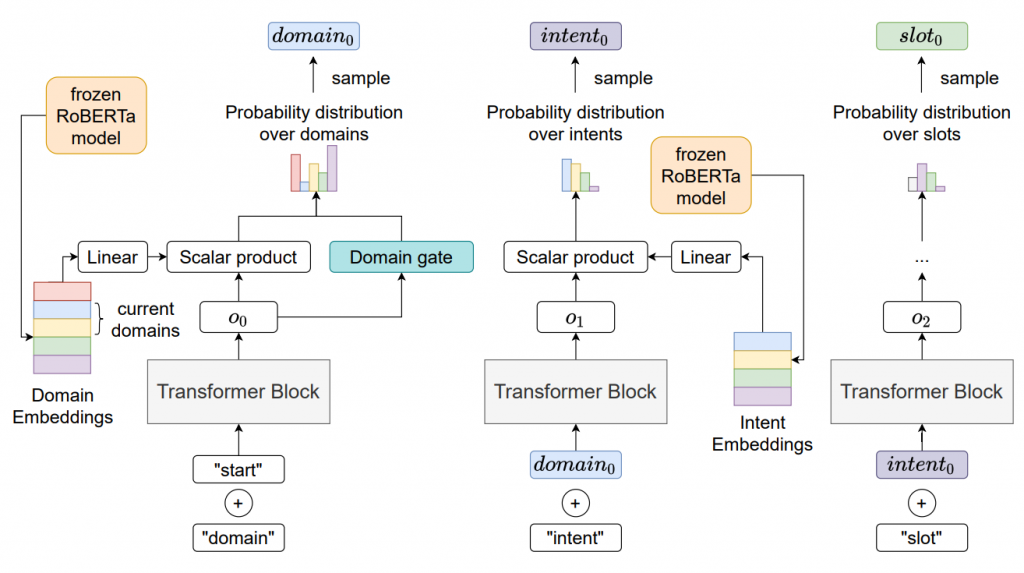
DDPT利用RoBERTa語言模型生成狀態信息、領域、槽位和行動集中的值的嵌入
Reference.
ConvLab-3
Coling2022-Dynamic Dialogue Policy for Continual Reinforcement Learning

